
Tutoriel PySpark pour les débutants [avec exemples]
Publié: 2020-10-07PySpark est une plate-forme basée sur le cloud fonctionnant comme une architecture de service. La plate-forme fournit un environnement pour calculer des fichiers Big Data. PySpark fait référence à l'application du langage de programmation Python en association avec des clusters Spark. Il est profondément associé au Big Data. Dites-nous d'abord ce que Big Data traite brièvement et obtenez un aperçu du didacticiel PySpark .
Table des matières
A quoi sert PySpark ?
En tant qu'API Python pour Spark publiée par la communauté Apache Spark, elle prend en charge Python avec Spark. Continuez à lire cet article sur le didacticiel Spark Python pour en savoir plus sur les utilisations.
- Avec l'utilisation de PySpark, on peut intégrer et travailler efficacement avec des ensembles de données distribués résilients (RDD) en Python.
- De nombreuses fonctionnalités font de PySpark un excellent framework car il facilite le travail avec des ensembles de données volumineux.
- PySpark fournit des bibliothèques d'une large gamme, et l'apprentissage automatique et l'analyse de flux en temps réel sont facilités avec l'aide de PySpark.
- PySpark exploite la simplicité de Python et la puissance d'Apache Spark utilisé pour apprivoiser le Big Data.
- Avec l'avènement du Big Data, la puissance de technologies telles qu'Apache Spark et Hadoop a été développée.
- Un scientifique des données peut gérer efficacement de grands ensembles de données, car il est à la portée de tout développeur Python.
Lire : Dataframe dans Apache PySpark
Concepts du Big Data en Python
Python est un langage de programmation de haut niveau qui expose également de nombreux paradigmes de programmation tels que la programmation orientée objet (POO), la programmation asynchrone et fonctionnelle.
La programmation fonctionnelle est un paradigme important lorsqu'il s'agit de Big Data. Il suit un code parallèle, ce qui signifie que vous pouvez exécuter votre code sur plusieurs processeurs ainsi que sur des machines entièrement différentes. L'écosystème PySpark a le pouvoir de vous permettre d'utiliser du code fonctionnel et de le distribuer sur un cluster d'ordinateurs.
Les idées de base de la programmation fonctionnelle pour les programmeurs sont disponibles dans la bibliothèque standard et les éléments intégrés de Python.
La manipulation de données se produisant par le biais de fonctions sans aucune maintenance d'état externe est l'incarnation de l'idée centrale de la programmation fonctionnelle. Cela signifie que votre code contourne les variables globales et ne manipule pas les données sur place, mais renvoie toujours de nouvelles données. Python utilise le mot-clé lambda pour exposer des fonctions anonymes.
Apprenez le cours de certification en science des données des meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Quelques fonctionnalités clés de PySpark
- Polyglot : PySpark est l'un des frameworks les plus appréciables pour le calcul à travers des ensembles de données massifs. Il est également compatible avec plusieurs langues.
- Persistance et mise en cache du disque : le framework PySpark offre une persistance de disque impressionnante et une mise en cache puissante.
- Traitement rapide : par rapport aux autres frameworks traditionnels utilisés pour le traitement du Big Data, le framework PySpark est assez rapide.
- Fonctionne bien avec les RDD : Python est typé dynamiquement pour un langage de programmation, ce qui permet de travailler avec des ensembles de données distribués résilients.
Qu'est-ce que PySpark ?
Ce tutoriel Pyspark vous permettra de comprendre ce qu'est PySpark. PySpark est une interface de programmation d'application Python (API). L'API est écrite en Python pour établir une connexion avec Apache Spark. Comme vous le savez, Apache Spark traite de l'analyse de données volumineuses. Le langage de programmation Scala est utilisé pour créer Apache Spark. Il peut être intégré par d'autres langages de programmation, à savoir Python, Java, SQL, R et Scala lui-même.
PySpark est basé sur deux ensembles de corroboration :
- API PySpark : elle contient de nombreux exemples.
- API Spark Scala : pour les programmes PySpark, elle traduit le code Scala qui est lui-même un langage de programmation très lisible et basé sur le travail, en code python et le rend compréhensible.
Py4J donne la liberté à un programme Python de communiquer via du code basé sur JVM. Il aide PySpark à se connecter à l'interface de programmation d'application basée sur Spark Scala.
Comment définir l'environnement PySpark
Parlons maintenant des différents environnements dans lesquels PySpark démarre et est appliqué. Suivez ce didacticiel Spark Python pour définir PySpark :
- Auto-hébergé : Dans ce cas, vous pouvez mettre en place une collecte ou vous regrouper. Dans cet environnement, vous pouvez chercher à utiliser des clusters métalliques ou virtuels. Certains projets proposés, à savoir Apache Ambari, sont applicables à cette fin. Cependant, ce processus n'est pas assez rapide.
- Fournisseurs de cloud : dans ce cas, le plus souvent, des clusters Spark sont utilisés. Cet environnement sert plus rapidement que l'auto-hébergement. Amazon Web Services (AWS) a Electronic MapReduce (EMR), tandis que Good Clinical Practice (GCP) a Dataproc.
- Solutions des fournisseurs : Databricks et Cloudera proposent des solutions Spark. C'est l'un des moyens les plus rapides d'exécuter PySpark.
Programmation PySpark
Comme nous le savons tous, Python est un langage de haut niveau possédant plusieurs bibliothèques. Il joue un rôle crucial dans l'apprentissage automatique et l'analyse de données. Par conséquent, PySpark est une API pour l'étincelle écrite en Python. Spark a d'excellents attributs avec une vitesse élevée, un accès facile et appliqué pour l'analyse en continu. En plus de cela, le cadre de Spark et Python aide PySpark à accéder et à traiter facilement le Big Data.
Les éléments essentiels du didacticiel Spark Python sont abordés ci-dessous.
Ensembles de données distribués résilients (RDD) : les ensembles de données distribués résilients ou les RDD sont l'un des principaux éléments constitutifs de l'architecture de programmation PySpark. Cette collection est immuable et subit de faibles transformations. Chaque mot de cette abréviation a une signification. Il est résilient car il peut permettre des erreurs et peut redécouvrir des données. Il est distribué car il s'étend sur divers autres nœuds dans un bloc. Dataset représente le stockage de données de valeurs.
Lisez aussi: Questions d'entretien PySpark les plus courantes
RDD prend principalement en charge les types d'opérations suivants
1) Transformations : Les transformations suivant le principe des Lazy Evaluations, permettent d'opérer des exécutions en appelant à tout moment une action sur les données. Peu de transformations sont Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, triées par les RDD.

2) Actions : les opérations RDD permettent à PySpark d'appliquer le calcul, en renvoyant le résultat au pilote, appelé actions.
Étapes pour convertir les majuscules en minuscules et diviser une chaîne
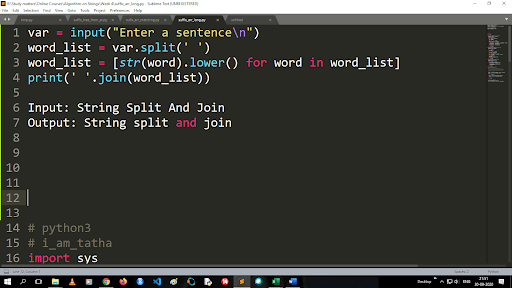
La sortie de la fonction split est de type liste. Pour utiliser la fonction de jointure, le format est ".join (type de données de séquence)" Avec le code ci-dessus :
Entrée : String Split et Join
Sortie : scission et jointure de chaîne
Comment lire un fichier ?
Lire un fichier en Python en appelant le fichier .txt dans un "mode lecture" (r).
Étape 1) Ouvrez le fichier en mode lecture
f=open("exemple.txt", "r")
Étape 2) Nous utilisons la fonction mode dans le code pour vérifier que le fichier est en mode ouvert.
f.mode == 'r' :
Étape 3) Utilisez f.read pour lire les données du fichier et les stocker dans un contenu variable
contenu = f.read()
Étapes de l'analyse prédictive :
- Exploration des données : vous devez collecter les données, les télécharger et déterminer le type de données, son type et sa valeur.
- Nettoyage des données : Vous devez trouver les valeurs nulles, les valeurs manquantes et autres redondances qui pourraient gêner le programme.
- Modélisation : Vous devez sélectionner un modèle prédictif.
- Évaluation : Vous devez vérifier l'exactitude de votre analyse.
Streaming PySpark
PySpark Streaming n'est rien d'autre qu'un système extensible et sans erreur. Il respecte les intervalles de lot RDD allant de 500 ms à des intervalles d'intervalle plus élevés. Selon le didacticiel Spark Python , Spark Streaming reçoit des données diffusées en continu en entrée.
En fonction du nombre d'intervalles de lot RDD, ces données diffusées en continu sont divisées en plusieurs lots et sont envoyées au moteur Spark. Certaines des sources à partir desquelles les données diffusées sont reçues sont Kinesis, Kafka, Apache Flume, etc. En utilisant des structures de données et des algorithmes, les moteurs Spark peuvent récupérer des données. Après cela, les données récupérées sont transmises à divers systèmes de fichiers et bases de données.
Comme indiqué précédemment, PySpark est une API de haut niveau. Malgré tout échec, l'opération de streaming ne sera exécutée qu'une seule fois. L'une des principales distractions du PySpark Streaming est le Discretized Stream. Ces composants de flux sont également construits à l'aide de lots RDD. MLib, SQL, Dataframes sont utilisés pour élargir le large éventail d'opérations pour Spark Streaming.
Dans ce didacticiel PySpark , vous apprenez que Spark Stream récupère de nombreuses données provenant de diverses sources. Cela est possible car il utilise des algorithmes complexes qui incluent des composants hautement fonctionnels - Map, Reduce, Join et Window.
Ce sont les choses qui résument ce qu'est PySpark Streaming. Maintenant, dans ce tutoriel Spark python , parlons de certains des avantages de PySpark.
Avantages de PySpark
Ce segment peut être divisé en deux parties. Tout d'abord, vous découvrirez les avantages de l'utilisation de Python dans PySpark et, deuxièmement, les avantages de PySpark lui-même.
- Étant un langage de haut niveau et convivial pour les codeurs, il est facile à apprendre et à exécuter.
- Une API simple et inclusive peut être utilisée.
- Python donne au lecteur une excellente occasion de visualiser les données.
- Python a une large gamme de bibliothèques. Certains des exemples sont Matplotlib, Pandas, Seaborn, NumPy, etc.
Maintenant, voici les fonctionnalités de PySpark Tutorial :
- PySpark Streaming intègre facilement d'autres langages de programmation comme Java, Scala et R.
- PySpark permet aux programmeurs d'exécuter plusieurs fonctions avec des ensembles de données distribués résilients (RDD)
- PySpark est préféré aux autres solutions Big Data en raison de sa grande vitesse, de ses puissants mécanismes de capture et de persistance sur disque pour le traitement des données.
Doit lire: Tutoriel Python pour les débutants
Inclusion de la science des données et de l'apprentissage automatique dans PySpark
En tant que langage de programmation hautement fonctionnel, Python est l'épine dorsale de la science des données et de l'apprentissage automatique. Il n'est donc pas surprenant que Data Science et ML fassent partie intégrante du système PySpark. Machine Learning Library (MLib) est l'opérateur qui contrôle les fonctionnalités de Machine Learning dans PySpark.
Voici les avantages de l'utilisation de Machine Learning dans PySpark :
- Il est hautement extensible.
- Il reste fonctionnel dans les systèmes distribués.
Les principales fonctions du Machine Learning dans PySpark :
- Machine Learning prépare diverses méthodes et compétences pour le bon traitement des données. Ce sont la transformation, l'extraction, le hachage, la sélection, etc.
- Il fournit des algorithmes complexes, comme mentionné précédemment. Ceux-ci sont utilisés pour traiter des données provenant de diverses sources.
- Il utilise une interprétation mathématique et des données statistiques. Il implique des processus d'algèbre linéaire et d'évaluation de modèles.
Conclusion
Dans ce didacticiel, nous avons discuté des fonctionnalités clés, de la configuration de l'environnement, de la lecture d'un fichier, etc.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1 -on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Qu'est-ce que PySpark ?
PySpark a été formé pour promouvoir la collaboration d'Apache Spark avec Python. Cette collaboration fournit une API Python pour Spark. De plus, PySpark permet aux utilisateurs d'interagir avec des ensembles de données distribués résilients (RDD) dans Apache Spark et Python. PySpark permet aux utilisateurs d'intégrer et d'interagir rapidement avec les RDD dans le langage de programmation Python. Plusieurs caractéristiques font de PySpark un excellent outil pour travailler avec de grands ensembles de données. Les ingénieurs de données se tournent vers cet outil pour effectuer des calculs sur d'énormes ensembles de données ou simplement pour les étudier. Ceci est accompli en utilisant la bibliothèque Py4j.
Quels sont les cas d'utilisation réels de PySpark ?
PySpark est actuellement utilisé pour le streaming ETL. Le streaming ETL nettoie et agrège en continu les données avant qu'elles ne soient livrées dans le stockage de données. PySpark facilite l'enrichissement des données en enrichissant les données en direct en les intégrant à des données statiques, permettant aux entreprises d'effectuer une analyse de données en temps réel plus complète. Pyspark est également utilisé pour la détection de déclencheur. Les déclencheurs sont utilisés par les organisations financières pour détecter les transactions frauduleuses et les arrêter dans leur élan. Les déclencheurs sont également utilisés dans les hôpitaux pour identifier les changements de santé potentiellement nocifs tout en surveillant les signes vitaux des patients, en envoyant des notifications automatiques aux soignants concernés qui peuvent alors prendre les mesures rapides et nécessaires.
Python et PySpark sont-ils liés ?
PySpark est le résultat du partenariat Apache Spark et Python. Python est un langage de programmation de haut niveau à usage général, tandis qu'Apache Spark est une plate-forme informatique en cluster open source axée sur la vitesse, la facilité d'utilisation et l'analyse en continu. Il offre un ensemble diversifié de bibliothèques et est principalement utilisé pour l'apprentissage automatique et l'analyse en continu en temps réel. Cela signifie qu'il s'agit d'une API Python pour Spark qui vous permet d'apprivoiser le Big Data en combinant la simplicité de Python avec la puissance d'Apache Spark.