
Yeni Başlayanlar İçin PySpark Eğitimi [Örneklerle]
Yayınlanan: 2020-10-07PySpark, hizmet mimarisi olarak işlev gören bulut tabanlı bir platformdur. Platform, Büyük Veri dosyalarını hesaplamak için bir ortam sağlar. PySpark, Spark kümeleriyle birlikte Python programlama dilinin uygulanmasını ifade eder. Büyük Veri ile derinden ilişkilidir. Öncelikle Big Data'nın neyle ilgilendiğini kısaca bize bildirin ve PySpark eğitimine genel bir bakış elde edin .
İçindekiler
PySpark ne için kullanılır?
Apache Spark topluluğu tarafından piyasaya sürülen Spark için bir Python API'si olarak, Spark ile Python'u destekler. Kullanımlar hakkında daha fazla bilgi edinmek için kıvılcım öğretici Python hakkındaki bu makaleyi okumaya devam edin .
- PySpark kullanımıyla, Python'da Esnek Dağıtılmış Veri Kümeleri (RDD'ler) ile entegre edilebilir ve verimli bir şekilde çalışılabilir.
- Çok sayıda özellik, büyük veri kümeleriyle çalışmayı kolaylaştırdığı için PySpark'ı mükemmel bir çerçeve haline getirir.
- PySpark, geniş bir yelpazede kitaplıklar sağlar ve Makine Öğrenimi ve Gerçek Zamanlı Akış Analizi, PySpark'ın yardımıyla daha kolay hale getirilir.
- PySpark, Python'un sadeliğinden ve Büyük Verileri evcilleştirmek için kullanılan Apache Spark'ın gücünden yararlanır.
- Büyük Verinin ortaya çıkmasıyla birlikte Apache Spark ve Hadoop gibi teknolojilerin gücü geliştirildi.
- Bir veri bilimcisi, herhangi bir Python geliştiricisinin erişiminde olduğu için büyük veri kümelerini verimli bir şekilde işleyebilir.
Okuyun: Apache PySpark'ta Veri Çerçevesi
Python'da Büyük Veri Kavramları
Python, nesne yönelimli programlama (OOP'ler), eşzamansız ve işlevsel programlama gibi birçok programlama paradigmasını da ortaya çıkaran üst düzey bir programlama dilidir.
Fonksiyonel programlama, Büyük Veri ile uğraşırken önemli bir paradigmadır. Paralel bir kod izler; bu, kodunuzu tamamen farklı makinelerde olduğu kadar birkaç CPU'da da çalıştırabileceğiniz anlamına gelir. PySpark ekosistemi, işlevsel kodu kullanmanıza ve onu bir bilgisayar kümesine dağıtmanıza izin verme gücüne sahiptir.
Programcılar için fonksiyonel programlama temel fikirleri standart kütüphanede ve Python'un yerleşiklerinde mevcuttur.
Herhangi bir harici durum bakımı olmaksızın işlevler aracılığıyla gerçekleşen veri manipülasyonu, işlevsel programlamanın temel fikir düzenlemesidir. Bu, kodunuzun global değişkenleri atlattığı ve verileri yerinde değiştirmediği, ancak her zaman yeni veriler döndürdüğü anlamına gelir. Python, anonim işlevleri ortaya çıkarmak için lambda anahtar sözcüğünü kullanır.
Dünyanın en iyi Üniversitelerinden veri bilimi sertifika kursunu öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
PySpark'ın Bazı Temel Özellikleri
- Polyglot: PySpark, büyük veri kümeleri aracılığıyla hesaplama için en dikkate değer çerçevelerden biridir. Birden çok dille de uyumludur.
- Disk kalıcılığı ve önbelleğe alma: PySpark çerçevesi, etkileyici disk kalıcılığı ve güçlü önbelleğe alma sağlar.
- Hızlı işleme: Büyük Veri işleme için kullanılan diğer geleneksel çerçevelerle karşılaştırıldığında, PySpark çerçevesi oldukça hızlıdır.
- RDD'lerle iyi çalışır: Python, Esnek Dağıtılmış Veri Kümeleri ile çalışmaya yardımcı olan bir programlama dili için dinamik olarak yazılmıştır.
PySpark nedir?
Bu Pyspark öğreticisi , PySpark'ın ne olduğunu anlamanıza izin verecektir. PySpark bir Python Uygulama Programlama Arayüzüdür (API). API, Apache Spark ile bir bağlantı oluşturmak için Python'da yazılmıştır. Bildiğiniz gibi Apache Spark, büyük veri analizi ile ilgilenir. Apache Spark'ı oluşturmak için programlama dili Scala kullanılır. Python, Java, SQL, R ve Scala'nın kendisi gibi diğer programlama dilleri ile entegre edilebilir.
PySpark iki grup doğrulamaya dayanmaktadır:
- PySpark API: Çok fazla örneği var.
- Spark Scala API: PySpark programları için kendisi oldukça okunaklı ve iş tabanlı bir programlama dili olan Scala kodunu python koduna çevirir ve anlaşılır hale getirir.
Py4J, bir Python programına JVM tabanlı kod aracılığıyla iletişim kurma özgürlüğü verir. PySpark'ın Spark Scala tabanlı Uygulama Programlama Arayüzü ile bağlanmasına yardımcı olur.
PySpark Ortamı Nasıl Ayarlanır
Şimdi PySpark'ın kullanılmaya başlandığı ve başvurulduğu farklı ortamları tartışalım. PySpark'ı ayarlamak için bu kıvılcım öğretici Python'u izleyin:
- Kendi Kendine Barındırılan: Bu durumda, bir koleksiyon oluşturabilir veya kendiniz toplayabilirsiniz. Bu ortamda metal veya sanal kümeler kullanmayı düşünebilirsiniz. Bu amaç için geçerli olan bazı önerilen projeler, yani Apache ambarı vardır. Ancak bu süreç yeterince hızlı değildir.
- Bulut Sağlayıcıları: Bu durumda, çoğu zaman Spark kümeleri kullanılır. Bu ortam, kendi kendine barındırmadan daha hızlı hizmet verir. Amazon Web hizmetlerinde (AWS) Elektronik MapReduce (EMR) bulunurken, İyi Klinik Uygulamalarda (GCP) Dataproc bulunur.
- Satıcı Çözümleri: Databricks ve Cloudera, Spark çözümleri sunar. PySpark'ı çalıştırmanın en hızlı yollarından biridir.
PySpark Programlama
Hepimizin bildiği gibi Python, birkaç kütüphaneye sahip üst düzey bir dildir. Makine Öğrenimi ve Veri Analitiğinde çok önemli bir rol oynar. Bu nedenle PySpark, Python'da yazılmış kıvılcım için bir API'dir. Spark, yüksek hız, kolay erişim ve akış analitiği için uygulanan bazı mükemmel özelliklere sahiptir. Buna ek olarak, Spark ve Python çerçevesi, PySpark'ın büyük verilere kolayca erişmesine ve bunları işlemesine yardımcı olur.
Spark öğretici Python'un temelleri aşağıda tartışılmaktadır.
Esnek Dağıtılmış Veri Kümeleri (RDD'ler): Esnek Dağıtılmış Veri Kümeleri veya RDD'ler, PySpark programlama mimarisinin temel yapı taşlarından biridir. Bu koleksiyon değişmez ve zayıf dönüşümlere uğrar. Bu kısaltmanın her bir kelimesinin bir anlamı vardır. Esnektir çünkü hatalara izin verebilir ve verileri yeniden keşfedebilir. Bir kümedeki çeşitli diğer düğümler üzerinde genişlediği için dağıtılır. Veri kümesi, değer verilerinin depolanması anlamına gelir.
Ayrıca Okuyun: En Yaygın PySpark Mülakat Soruları
RDD Temel Olarak Aşağıdaki İşlem Türlerini Destekler
1) Dönüşümler: Tembel Değerlendirmeler ilkesini izleyen Dönüşümler, istediğiniz zaman veriler üzerinde bir eylem çağırarak yürütmeleri çalıştırmanıza olanak tanır. Dönüşümlerin birkaçı, RDD'ler tarafından sağlanan Sıralama, Harita, Düz Harita, Filtre, Farklı, Anahtara Göre Küçült, Harita Bölümleridir.

2) Eylemler: RDD operasyonları, PySpark'ın hesaplama uygulamasına izin verir, sonucu sürücüye geri iletir, buna eylemler denir.
Büyük Harfi Küçük Harfe Dönüştürme ve Bir Dizeyi Bölme Adımları
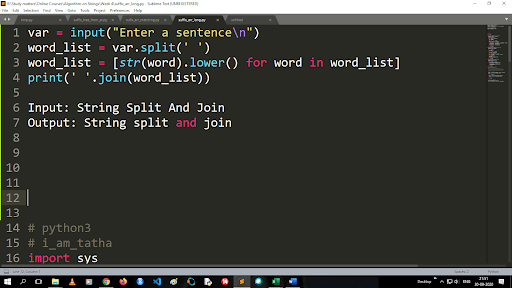
Bölme işlevinin çıktısı liste türündedir. Birleştirme işlevini kullanmak için biçim “.join (sıra veri türü)” şeklindedir. Yukarıdaki kodla birlikte:
Girdi: Dize Böl ve Birleştir
Çıktı: Dize bölme ve birleştirme
Dosya Nasıl Okunur?
Bir "okuma modunda"(r) .txt dosyasını çağırarak Python'da bir dosyayı okuyun.
Adım 1) Dosyayı Okuma modunda açın
f=open(“örnek.txt”, ”r”)
Adım 2) Dosyanın açık modda olup olmadığını kontrol etmek için koddaki mod işlevini kullanırız.
f.mode == 'r':
Adım 3) Dosya verilerini okumak ve değişken içerikte saklamak için f.read kullanın
içindekiler = f.read()
Tahmine Dayalı Analizdeki Adımlar:
- Veri keşfi: Verileri toplamanız, yüklemeniz ve veri türünü, türünü ve değerini bulmanız gerekir.
- Veri temizleme: Programı engelleyebilecek boş değerleri, eksik değerleri ve diğer fazlalıkları bulmanız gerekir.
- Modelleme: Tahmine dayalı bir model seçmelisiniz.
- Değerlendirme: Analizinizin doğruluğunu kontrol etmelisiniz.
PySpark Akışı
PySpark Streaming, genişletilebilir, hatasız bir sistemden başka bir şey değildir. 500ms'den daha yüksek aralıklı yuvalara kadar değişen RDD toplu aralıklarına uyar. Spark öğretici Python'a göre , Spark Streaming'e girdi olarak bazı akış verileri verilir.
RDD grup aralıklarının sayısına bağlı olarak, bu akışlı veriler çok sayıda gruba bölünür ve Spark Engine'e gönderilir. Akış verilerinin alındığı kaynaklardan bazıları Kinesis, Kafka, Apache Flume vb.'dir. Spark Engines, Veri Yapılarını ve algoritmaları kullanarak verileri alabilir. Bundan sonra, alınan veriler çeşitli dosya sistemlerine ve veritabanlarına iletilir.
Daha önce belirtildiği gibi, PySpark üst düzey bir API'dir. Oluşan herhangi bir hataya rağmen, akış işlemi yalnızca bir kez yürütülecektir. PySpark Akışının ana dikkat dağıtıcılarından biri Ayrıklaştırılmış Akıştır. Bu akış bileşenleri ayrıca RDD yığınlarının yardımıyla oluşturulmuştur. MLib, SQL, Dataframe'ler, Spark Akışı için geniş operasyon yelpazesini genişletmek için kullanılır.
Bu PySpark Eğitiminde , Spark Stream'in çeşitli kaynaklardan çok fazla veri aldığını öğreneceksiniz. Harita, Küçült, Birleştir ve Pencere gibi son derece işlevsel bileşenleri içeren karmaşık algoritmalar kullandığı için bu mümkündür.
PySpark Streaming'in ne olduğunu özetleyen şeyler bunlar. Şimdi bu Spark eğitiminde python , PySpark'ın bazı avantajlarından bahsedelim.
PySpark'ın Avantajları
Bu segment iki kısma ayrılabilir. Her şeyden önce, PySpark'ta Python kullanmanın avantajlarını ve ikinci olarak da PySpark'ın avantajlarını öğreneceksiniz.
- Üst düzey ve kodlayıcı dostu bir dil olduğu için öğrenmesi ve yürütmesi kolaydır.
- Basit ve kapsamlı bir API kullanılabilir.
- Python, okuyucuya verileri görselleştirmesi için mükemmel bir fırsat sunar.
- Python, geniş bir kütüphane yelpazesine sahiptir. Örneklerden bazıları Matplotlib, Pandas, Seaborn, NumPy vb.
Şimdi, PySpark Eğitiminin özellikleri şunlardır :
- PySpark Streaming, Java, Scala ve R gibi diğer programlama dillerini kolayca entegre eder.
- PySpark, programcıların Esnek Dağıtılmış Veri Kümeleri (RDD'ler) ile çeşitli işlevleri gerçekleştirmelerini kolaylaştırır
- PySpark, veri işleme için yüksek hızı, güçlü yakalama ve disk kalıcı mekanizmaları nedeniyle diğer Büyük Veri çözümlerine göre tercih edilir.
Mutlaka Okuyun: Yeni Başlayanlar İçin Python Eğitimi
PySpark'ta Veri Bilimi ve Makine Öğreniminin Dahil Edilmesi
Oldukça işlevsel bir programlama dili olan Python, Veri Bilimi ve Makine Öğreniminin bel kemiğidir. Bu nedenle, Data Science ve ML'nin PySpark sisteminin ayrılmaz parçaları olması şaşırtıcı değildir. Machine Learning Library (MLib), PySpark'ta Machine Learning'in işlevselliğini kontrol eden operatördür.
PySpark'ta Machine Learning kullanmanın avantajları şunlardır:
- Son derece genişletilebilir.
- Dağıtılmış sistemlerde işlevsel kalır.
PySpark'ta Makine Öğreniminin ana işlevleri:
- Makine Öğrenimi, verilerin uygun şekilde işlenmesi için çeşitli yöntemler ve beceriler hazırlar. Bunlar dönüşüm, çıkarma, karma, seçim vb.
- Daha önce belirtildiği gibi bazı karmaşık algoritmalar sağlar. Bunlar, çeşitli kaynaklardan gelen verileri işlemek için kullanılır.
- Bazı matematiksel yorumları ve istatistiksel verileri kullanır. Lineer cebir ve model değerlendirme süreçlerini içerir.
Çözüm
Bu eğitimde temel özellikleri, ortamı ayarlamayı, bir dosyayı okumayı ve daha fazlasını tartıştık.
Veri bilimi hakkında bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için oluşturulmuş ve 10'dan fazla vaka çalışması ve proje, uygulamalı uygulamalı atölye çalışmaları, endüstri uzmanlarıyla mentorluk, 1 Endüstri danışmanlarıyla bire bir, en iyi firmalarla 400+ saat öğrenim ve iş yardımı.
PySpark nedir?
PySpark, Apache Spark'ın Python ile işbirliğini teşvik etmek için kuruldu. Bu işbirliği, Spark için bir Python API'si sağlar. Ayrıca PySpark, kullanıcıların Apache Spark ve Python'da Esnek Dağıtılmış Veri Kümeleri (RDD'ler) ile etkileşim kurmasını sağlar. PySpark, kullanıcıların Python programlama dilinde RDD'leri hızlı bir şekilde entegre etmelerine ve bunlarla etkileşim kurmalarına olanak tanır. PySpark'ı büyük veri kümeleriyle çalışmak için bu kadar mükemmel bir araç yapan birkaç özellik vardır. Veri Mühendisleri, büyük veri kümeleri üzerinde hesaplamalar yapmak veya sadece onları incelemek için bu araca yöneliyor. Bu, Py4j kitaplığı kullanılarak gerçekleştirilir.
PySpark'ın gerçek hayattaki kullanım durumları nelerdir?
PySpark şu anda Streaming ETL için kullanılmaktadır. Akış ETL, verileri veri deposuna teslim edilmeden önce sürekli olarak temizler ve toplar. PySpark, canlı verileri statik verilerle entegre ederek zenginleştirerek veri zenginleştirmeye yardımcı olur ve şirketlerin daha kapsamlı gerçek zamanlı veri analizi yapmasına olanak tanır. Pyspark ayrıca Tetik Tespiti için de kullanılır. Tetikleyiciler, finansal kuruluşlar tarafından hileli işlemleri tespit etmek ve izlerinde durdurmak için kullanılır. Tetikleyiciler ayrıca hastanelerde, hastanın yaşamsal belirtilerini izlerken, ilgili bakıcılara otomatik bildirimler gönderirken, potansiyel olarak zararlı sağlık değişikliklerini belirlemek için de kullanılır; bu kişiler daha sonra hızlı ve gerekli önlemi alabilir.
Python ve PySpark ilişkili mi?
PySpark, Apache Spark ve Python ortaklığının bir sonucudur. Python genel amaçlı, üst düzey bir programlama diliyken Apache Spark hız, kullanım kolaylığı ve akış analitiğine odaklanan açık kaynaklı bir küme bilgi işlem platformudur. Çok çeşitli kitaplıklar sunar ve çoğunlukla Makine Öğrenimi ve Gerçek Zamanlı Akış Analitiği için kullanılır. Bu, Python'un basitliğini Apache Spark'ın gücüyle birleştirerek Büyük Veriyi evcilleştirmenizi sağlayan Spark için bir Python API'si olduğu anlamına gelir.