
บทช่วยสอน PySpark สำหรับผู้เริ่มต้น [พร้อมตัวอย่าง]
เผยแพร่แล้ว: 2020-10-07PySpark เป็นแพลตฟอร์มบนคลาวด์ที่ทำงานเป็นสถาปัตยกรรมบริการ แพลตฟอร์มนี้จัดเตรียมสภาพแวดล้อมในการคำนวณไฟล์ Big Data PySpark หมายถึงแอปพลิเคชันของภาษาโปรแกรม Python ที่เชื่อมโยงกับคลัสเตอร์ Spark มีความเกี่ยวข้องอย่างลึกซึ้งกับ Big Data แจ้ง ให้เราทราบก่อนว่า Big Data เกี่ยวข้องกับอะไรโดยสังเขป และรับภาพรวมของ บท ช่วย สอน PySpark
สารบัญ
PySpark ใช้สำหรับอะไร?
ในฐานะที่เป็น Python API สำหรับ Spark ที่เผยแพร่โดยชุมชน Apache Spark จึงสนับสนุน Python ที่มี Spark อ่านบทความนี้ต่อไปเกี่ยวกับ Spark tutorial Python เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับการใช้งาน
- ด้วยการใช้ PySpark เราสามารถรวมและทำงานอย่างมีประสิทธิภาพด้วย Resilient Distributed Datasets (RDDs) ใน Python
- ฟีเจอร์มากมายทำให้ PySpark เป็นเฟรมเวิร์กที่ยอดเยี่ยม เนื่องจากอำนวยความสะดวกในการทำงานกับชุดข้อมูลขนาดใหญ่
- PySpark ให้บริการไลบรารีที่หลากหลาย และการเรียนรู้ด้วยเครื่องและการวิเคราะห์การสตรีมแบบเรียลไทม์ทำได้ง่ายขึ้นด้วยความช่วยเหลือของ PySpark
- PySpark ใช้ประโยชน์จากความเรียบง่ายของ Python และพลังของ Apache Spark ที่ใช้ในการควบคุม Big Data
- ด้วยการถือกำเนิดของ Big Data พลังของเทคโนโลยีเช่น Apache Spark และ Hadoop จึงได้รับการพัฒนา
- นักวิทยาศาสตร์ข้อมูลสามารถจัดการชุดข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพ เช่นเดียวกับนักพัฒนา Python
อ่าน: Dataframe ใน Apache PySpark
แนวคิดข้อมูลขนาดใหญ่ใน Python
Python เป็นภาษาโปรแกรมระดับสูงที่แสดงกระบวนทัศน์การเขียนโปรแกรมมากมาย เช่น การเขียนโปรแกรมเชิงวัตถุ (OOP) การเขียนโปรแกรมแบบอะซิงโครนัสและการทำงาน
การเขียนโปรแกรมเชิงฟังก์ชันเป็นกระบวนทัศน์ที่สำคัญเมื่อต้องรับมือกับบิ๊กดาต้า มันเป็นไปตามรหัสขนาน ซึ่งหมายความว่าคุณสามารถเรียกใช้รหัสของคุณบน CPU หลายตัวรวมถึงเครื่องที่แตกต่างกันโดยสิ้นเชิง ระบบนิเวศ PySpark มีพลังในการอนุญาตให้คุณใช้โค้ดการทำงานและแจกจ่ายไปยังคลัสเตอร์ของคอมพิวเตอร์ได้
แนวคิดหลักในการเขียนโปรแกรมเชิงฟังก์ชันสำหรับโปรแกรมเมอร์มีอยู่ในไลบรารีมาตรฐานและ Python ในตัว
การจัดการข้อมูลที่เกิดขึ้นผ่านฟังก์ชันโดยไม่มีการบำรุงรักษาสถานะภายนอกเป็นแนวคิดหลักของการเขียนโปรแกรมเชิงฟังก์ชัน นี่หมายถึงความจริงที่ว่ารหัสของคุณหลีกเลี่ยงตัวแปรทั่วโลกและไม่ได้จัดการข้อมูลแบบแทนที่ แต่จะส่งคืนข้อมูลใหม่เสมอ Python ใช้คีย์เวิร์ดแลมบ์ดาเพื่อแสดงฟังก์ชันที่ไม่ระบุชื่อ
เรียนรู้ หลักสูตรการรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
คุณสมบัติที่สำคัญบางประการของ PySpark
- พูดได้หลายภาษา: PySpark เป็นหนึ่งในเฟรมเวิร์กที่ประเมินค่าได้มากที่สุดสำหรับการคำนวณผ่านชุดข้อมูลขนาดใหญ่ มันเข้ากันได้กับหลายภาษาด้วย
- ความคงอยู่ของดิสก์และการแคช: เฟรมเวิร์ก PySpark ให้ความคงอยู่ของดิสก์ที่น่าประทับใจและการแคชที่ทรงพลัง
- การประมวลผลที่รวดเร็ว: เฟรมเวิร์ก PySpark นั้นค่อนข้างเร็วเมื่อเทียบกับเฟรมเวิร์กดั้งเดิมอื่นๆ ที่ใช้สำหรับการประมวลผล Big Data
- ทำงานได้ดีกับ RDD: Python ถูกพิมพ์แบบไดนามิกสำหรับภาษาการเขียนโปรแกรม ซึ่งช่วยให้ทำงานกับชุดข้อมูลที่กระจายแบบยืดหยุ่นได้
PySpark คืออะไร?
บทแนะนำ Pyspark นี้ จะช่วยให้คุณเข้าใจว่า PySpark คืออะไร PySpark เป็น Python Application Programming Interface (API) API เขียนด้วย Python เพื่อสร้างการเชื่อมต่อกับ Apache Spark อย่างที่คุณทราบ Apache Spark เกี่ยวข้องกับการวิเคราะห์ข้อมูลขนาดใหญ่ ภาษาการเขียนโปรแกรม Scala ใช้เพื่อสร้าง Apache Spark สามารถรวมเข้ากับภาษาโปรแกรมอื่น ๆ เช่น Python, Java, SQL, R และ Scala ได้
PySpark ขึ้นอยู่กับการยืนยันสองชุด:
- PySpark API: มีตัวอย่างมากมาย
- Spark Scala API: สำหรับโปรแกรม PySpark จะแปลรหัส Scala ซึ่งเป็นภาษาโปรแกรมที่อ่านง่ายและใช้งานเป็นหลัก เป็นรหัสหลามและทำให้เข้าใจได้
Py4J ให้อิสระแก่โปรแกรม Python ในการสื่อสารผ่านโค้ดที่ใช้ JVM ช่วยให้ PySpark เชื่อมต่อกับ Application Programming Interface แบบ Spark Scala
วิธีการตั้งค่าสภาพแวดล้อม PySpark
ตอนนี้ เรามาพูดถึงสภาพแวดล้อมต่างๆ ที่ PySpark เริ่มต้นและนำไปใช้ ทำตาม Python กวดวิชา Spark นี้ เพื่อตั้งค่า PySpark:
- โฮสต์เอง: ในกรณีนี้ คุณสามารถตั้งค่าคอลเล็กชันหรือรวบรวมตัวเองได้ ในสภาพแวดล้อมนี้ คุณสามารถใช้โลหะหรือคลัสเตอร์เสมือน มีบางโครงการที่เสนอคือ Apache Ambari ที่ใช้สำหรับวัตถุประสงค์นี้ อย่างไรก็ตาม กระบวนการนี้ยังไม่เร็วพอ
- ผู้ให้บริการคลาวด์: ในกรณีนี้ มักใช้คลัสเตอร์ Spark สภาพแวดล้อมนี้ให้บริการเร็วกว่าการโฮสต์ด้วยตนเอง Amazon Web services (AWS) มี Electronic MapReduce (EMR) ในขณะที่ Good Clinical Practice (GCP) มี Dataproc
- โซลูชันผู้ขาย: Databricks และ Cloudera นำเสนอโซลูชัน Spark เป็นวิธีที่เร็วที่สุดวิธีหนึ่งในการเรียกใช้ PySpark
การเขียนโปรแกรม PySpark
อย่างที่เราทราบกันดีว่า Python เป็นภาษาระดับสูงที่มีไลบรารีหลายแห่ง มันมีบทบาทสำคัญในการเรียนรู้ของเครื่องและการวิเคราะห์ข้อมูล ดังนั้น PySpark จึงเป็น API สำหรับ Spark ที่เขียนด้วยภาษา Python Spark มีคุณลักษณะที่ยอดเยี่ยมบางอย่างที่มีความเร็วสูง เข้าถึงได้ง่าย และใช้สำหรับการวิเคราะห์การสตรีม นอกจากนี้ เฟรมเวิร์กของ Spark และ Python ยังช่วยให้ PySpark เข้าถึงและประมวลผลข้อมูลขนาดใหญ่ได้อย่างง่ายดาย
สาระสำคัญของการ สอน Spark Python มีการกล่าวถึงดังต่อไปนี้
Resilient Distributed Datasets (RDDs): Resilient Distributed Datasets หรือ RDD เป็นหนึ่งในโครงสร้างหลักของสถาปัตยกรรมการเขียนโปรแกรม PySpark คอลเลกชันนี้ไม่สามารถเปลี่ยนแปลงได้และผ่านการเปลี่ยนแปลงที่อ่อนแอ แต่ละคำของตัวย่อนี้มีความสำคัญ มีความยืดหยุ่นเนื่องจากสามารถทำให้เกิดข้อผิดพลาดและสามารถค้นพบข้อมูลได้อีกครั้ง มีการกระจายเนื่องจากขยายเหนือโหนดอื่นๆ เป็นกลุ่ม ชุดข้อมูลหมายถึงการจัดเก็บข้อมูลค่า
อ่านเพิ่มเติม: คำถามสัมภาษณ์ PySpark ที่พบบ่อยที่สุด
RDD รองรับการดำเนินการประเภทต่อไปนี้เป็นหลัก
1) การแปลงรูปแบบ: การแปลงตามหลักการของการประเมินแบบขี้เกียจ ช่วยให้คุณดำเนินการดำเนินการได้โดยการเรียกใช้การดำเนินการกับข้อมูลเมื่อใดก็ได้ การแปลงบางส่วนได้แก่ Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, sort by that is provided by RDDs.

2) การดำเนินการ: การดำเนินการ RDD อนุญาตให้ PySpark ใช้การคำนวณ โดยส่งผลลัพธ์กลับไปยังไดรเวอร์ ซึ่งเรียกว่าการดำเนินการ
ขั้นตอนในการแปลงตัวพิมพ์ใหญ่เป็นตัวพิมพ์เล็กและแยกสตริง
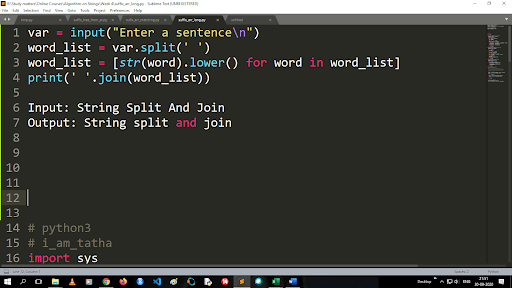
เอาต์พุตของฟังก์ชัน split เป็นประเภทรายการ ในการใช้ฟังก์ชัน join รูปแบบคือ “.join (sequence data type)” ด้วยรหัสด้านบน:
อินพุต: แยกสตริงและเข้าร่วม
เอาต์พุต: การแยกสตริงและเข้าร่วม
วิธีอ่านไฟล์?
อ่านไฟล์ใน Python โดยเรียกไฟล์ .txt ใน “read mode”(r)
ขั้นตอนที่ 1) เปิดไฟล์ในโหมดอ่าน
f=open(“sample.txt”, ”r”)
ขั้นตอนที่ 2) เราใช้ฟังก์ชันโหมดในโค้ดเพื่อตรวจสอบว่าไฟล์อยู่ในโหมดเปิดหรือไม่
f.mode == 'r':
ขั้นตอนที่ 3) ใช้ f.read เพื่ออ่านข้อมูลไฟล์และเก็บไว้ในเนื้อหาตัวแปร
เนื้อหา = f.read()
ขั้นตอนในการวิเคราะห์เชิงทำนาย:
- การสำรวจข้อมูล: คุณต้องรวบรวมข้อมูล อัปโหลด และค้นหาประเภทข้อมูล ชนิด และมูลค่าของข้อมูล
- การล้างข้อมูล: คุณต้องค้นหาค่า Null ค่าที่หายไป และความซ้ำซ้อนอื่นๆ ที่อาจขัดขวางโปรแกรม
- การสร้างแบบจำลอง: คุณต้องเลือกแบบจำลองการทำนาย
- การประเมิน: คุณต้องตรวจสอบความถูกต้องของการวิเคราะห์ของคุณ
PySpark สตรีมมิ่ง
PySpark Streaming เป็นเพียงระบบที่ขยายได้และปราศจากข้อผิดพลาด เป็นไปตามช่วงของแบทช์ RDD ตั้งแต่ 500 มิลลิวินาทีไปจนถึงช่วงช่วงที่สูงกว่า ตาม spark กวดวิชา Python Spark Streaming จะได้รับข้อมูลที่สตรีมเป็นอินพุต
ข้อมูลที่สตรีมเหล่านี้แบ่งออกเป็นแบทช์จำนวนมากและจะถูกส่งไปยัง Spark Engine ทั้งนี้ขึ้นอยู่กับจำนวนช่วงแบตช์ RDD แหล่งข้อมูลบางส่วนที่ได้รับข้อมูลที่สตรีม ได้แก่ Kinesis, Kafka, Apache Flume เป็นต้น ด้วยการใช้โครงสร้างข้อมูลและอัลกอริทึม Spark Engines สามารถดึงข้อมูลได้ หลังจากนั้นข้อมูลที่ดึงมาจะถูกส่งต่อไปยังระบบไฟล์และฐานข้อมูลต่างๆ
ตามที่ระบุไว้ก่อนหน้านี้ PySpark เป็น API ระดับสูง แม้จะเกิดความล้มเหลวใดๆ ก็ตาม การสตรีมจะดำเนินการเพียงครั้งเดียว สิ่งที่ทำให้ไขว้เขวหลักของ PySpark Streaming คือ Discretized Stream ส่วนประกอบสตรีมเหล่านี้สร้างขึ้นด้วยความช่วยเหลือของแบตช์ RDD MLib, SQL, Dataframes ใช้เพื่อขยายการดำเนินงานที่หลากหลายสำหรับ Spark Streaming
ใน บทช่วยสอน PySpark นี้ คุณจะได้เรียนรู้ว่า Spark Stream ดึงข้อมูลจำนวนมากจากแหล่งต่างๆ สิ่งนี้เป็นไปได้เพราะใช้อัลกอริธึมที่ซับซ้อนซึ่งมีส่วนประกอบที่ใช้งานได้สูง — แผนที่ ลด การเข้าร่วม และหน้าต่าง
นี่คือสิ่งที่สรุปว่า PySpark Streaming คืออะไร ใน python บทช่วยสอน Spark นี้ เรามาพูดถึงข้อดีของ PySpark กัน
ข้อดีของ PySpark
ส่วนนี้สามารถแบ่งออกเป็นสองส่วน ก่อนอื่น คุณจะได้ทราบถึงข้อดีของการใช้ Python ใน PySpark และประการที่สองคือข้อดีของ PySpark เอง
- เนื่องจากเป็นภาษาระดับสูงและเป็นมิตรกับผู้เขียนโค้ด จึงง่ายต่อการเรียนรู้และดำเนินการ
- สามารถใช้ API ที่เรียบง่ายและครอบคลุมได้
- Python เปิดโอกาสให้ผู้อ่านได้เห็นภาพข้อมูล
- Python มีไลบรารีที่หลากหลาย ตัวอย่างบางส่วน ได้แก่ Matplotlib, Pandas, Seaborn, NumPy เป็นต้น
ต่อไปนี้เป็นคุณสมบัติของ PySpark Tutorial :
- PySpark Streaming สามารถรวมภาษาการเขียนโปรแกรมอื่น ๆ เช่น Java, Scala และ R ได้อย่างง่ายดาย
- PySpark ช่วยให้โปรแกรมเมอร์ทำงานหลายอย่างด้วย Resilient Distributed Datasets (RDDs)
- PySpark เป็นที่ต้องการมากกว่าโซลูชัน Big Data อื่น ๆ เนื่องจากมีความเร็วสูง การจับที่มีประสิทธิภาพ และกลไกการคงอยู่ของดิสก์สำหรับการประมวลผลข้อมูล
ต้องอ่าน: บทช่วยสอน Python สำหรับผู้เริ่มต้น
การรวม Data Science และ Machine Learning ใน PySpark
เนื่องจากเป็นภาษาโปรแกรมที่ใช้งานได้จริง Python เป็นแกนหลักของ Data Science และ Machine Learning ดังนั้นจึงไม่น่าแปลกใจที่ Data Science และ ML เป็นส่วนสำคัญของระบบ PySpark Machine Learning Library (MLib) เป็นโอเปอเรเตอร์ที่ควบคุมการทำงานของ Machine Learning ใน PySpark
ข้อดีของการใช้ Machine Learning ใน PySpark มีดังนี้:
- มันขยายได้สูง
- มันยังคงทำงานในระบบแบบกระจาย
หน้าที่หลักของแมชชีนเลิร์นนิงใน PySpark:
- การเรียนรู้ของเครื่องเตรียมวิธีการและทักษะต่างๆ สำหรับการประมวลผลข้อมูลอย่างเหมาะสม สิ่งเหล่านี้คือการแปลง การสกัด การแฮช การเลือก ฯลฯ
- มันมีอัลกอริธึมที่ซับซ้อนบางอย่างดังที่ได้กล่าวไว้ก่อนหน้านี้ สิ่งเหล่านี้ใช้ในการประมวลผลข้อมูลจากแหล่งต่างๆ
- ใช้การตีความทางคณิตศาสตร์และข้อมูลทางสถิติ มันเกี่ยวข้องกับพีชคณิตเชิงเส้นและกระบวนการประเมินแบบจำลอง
บทสรุป
ในบทช่วยสอนนี้ เราได้พูดถึงคุณสมบัติหลัก การตั้งค่าสภาพแวดล้อม การอ่านไฟล์ และอื่นๆ
หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ลองดูโปรแกรม Executive PG ของ IIIT-B & upGrad ใน Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1 -on-1 พร้อมที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
PySpark คืออะไร?
PySpark ก่อตั้งขึ้นเพื่อส่งเสริมการทำงานร่วมกันของ Apache Spark กับ Python การทำงานร่วมกันนี้จัดเตรียม Python API สำหรับ Spark นอกจากนี้ PySpark ยังให้ผู้ใช้โต้ตอบกับชุดข้อมูลการกระจายแบบยืดหยุ่น (RDD) ใน Apache Spark และ Python PySpark ช่วยให้ผู้ใช้สามารถรวมและโต้ตอบกับ RDD ในภาษาการเขียนโปรแกรม Python ได้อย่างรวดเร็ว มีคุณสมบัติหลายประการที่ทำให้ PySpark เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการทำงานกับชุดข้อมูลขนาดใหญ่ วิศวกรข้อมูลหันมาใช้เครื่องมือนี้เพื่อคำนวณชุดข้อมูลขนาดใหญ่หรือเพื่อศึกษาข้อมูลเหล่านี้ ทำได้โดยใช้ไลบรารี Py4j
กรณีการใช้งานจริงของ PySpark คืออะไร?
ปัจจุบัน PySpark ใช้สำหรับ Streaming ETL ETL แบบสตรีมจะล้างและรวบรวมข้อมูลอย่างต่อเนื่องก่อนที่จะส่งไปยังที่จัดเก็บข้อมูล PySpark ช่วยในการเสริมแต่งข้อมูลโดยเพิ่มคุณค่าของข้อมูลสดโดยการรวมเข้ากับข้อมูลคงที่ ทำให้บริษัทต่างๆ ดำเนินการวิเคราะห์ข้อมูลแบบเรียลไทม์ที่ครอบคลุมมากขึ้น Pyspark ยังใช้สำหรับการตรวจจับทริกเกอร์ องค์กรทางการเงินใช้ทริกเกอร์เพื่อตรวจจับธุรกรรมที่เป็นการฉ้อโกงและหยุดพวกเขาในเส้นทางของพวกเขา นอกจากนี้ ยังใช้ทริกเกอร์ในโรงพยาบาลเพื่อระบุการเปลี่ยนแปลงด้านสุขภาพที่อาจเป็นอันตราย ในขณะที่ติดตามสัญญาณชีพของผู้ป่วย โดยส่งการแจ้งเตือนอัตโนมัติไปยังผู้ดูแลที่เกี่ยวข้องซึ่งอาจดำเนินการทันทีและจำเป็น
Python และ PySpark เกี่ยวข้องกันหรือไม่
PySpark เป็นผลมาจากความร่วมมือระหว่าง Apache Spark และ Python Python เป็นภาษาการเขียนโปรแกรมระดับสูงสำหรับวัตถุประสงค์ทั่วไป ในขณะที่ Apache Spark เป็นแพลตฟอร์มคอมพิวเตอร์คลัสเตอร์แบบโอเพนซอร์สที่เน้นที่ความเร็ว ความง่ายในการใช้งาน และการวิเคราะห์การสตรีม มีชุดไลบรารีที่หลากหลายและส่วนใหญ่จะใช้สำหรับการเรียนรู้ของเครื่องและการวิเคราะห์การสตรีมแบบเรียลไทม์ หมายความว่าเป็น Python API สำหรับ Spark ที่ช่วยให้คุณเชื่อง Big Data โดยผสมผสานความเรียบง่ายของ Python เข้ากับพลังของ Apache Spark