
Tutorial PySpark para iniciantes [com exemplos]
Publicados: 2020-10-07PySpark é uma plataforma baseada em nuvem que funciona como uma arquitetura de serviço. A plataforma fornece um ambiente para computar arquivos de Big Data. PySpark refere-se à aplicação da linguagem de programação Python em associação com clusters Spark. Está profundamente associado ao Big Data. Deixe-nos primeiro saber o que o Big Data trata brevemente e obter uma visão geral do tutorial do PySpark .
Índice
Para que serve o PySpark?
Como uma API Python para Spark lançada pela comunidade Apache Spark, ela oferece suporte a Python com Spark. Continue lendo este artigo sobre o tutorial do Spark Python para saber mais sobre os usos.
- Com o uso do PySpark, é possível integrar e trabalhar de forma eficiente com Resilient Distributed Datasets (RDDs) em Python.
- Vários recursos tornam o PySpark uma excelente estrutura, pois facilita o trabalho com grandes conjuntos de dados.
- O PySpark fornece bibliotecas de uma ampla variedade, e o Machine Learning e o Real-Time Streaming Analytics são facilitados com a ajuda do PySpark.
- O PySpark aproveita a simplicidade do Python e o poder do Apache Spark usado para controlar o Big Data.
- Com o advento do Big Data, o poder de tecnologias como Apache Spark e Hadoop foi desenvolvido.
- Um cientista de dados pode lidar eficientemente com grandes conjuntos de dados, estando ao alcance de qualquer desenvolvedor Python.
Leia: Dataframe no Apache PySpark
Conceitos de Big Data em Python
Python é uma linguagem de programação de alto nível que também expõe muitos paradigmas de programação, como programação orientada a objetos (OOPs), programação assíncrona e funcional.
A programação funcional é um paradigma importante ao lidar com Big Data. Ele segue um código paralelo, o que significa que você pode executar seu código em várias CPUs, bem como em máquinas totalmente diferentes. O ecossistema PySpark tem o poder de permitir que você use código funcional e distribua-o em um cluster de computadores.
As ideias principais de programação funcional para programadores estão disponíveis na biblioteca padrão e incorporadas do Python.
A manipulação de dados que ocorre por meio de funções sem qualquer manutenção de estado externa é a personificação da ideia central da programação funcional. Isso significa que seu código contorna variáveis globais e não manipula os dados no local, mas sempre retorna novos dados. Python usa a palavra-chave lambda para expor funções anônimas.
Aprenda o curso de certificação em ciência de dados das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Alguns dos principais recursos do PySpark
- Poliglota: PySpark é uma das estruturas mais apreciáveis para computação através de grandes conjuntos de dados. É compatível com vários idiomas também.
- Persistência de disco e armazenamento em cache: a estrutura PySpark fornece persistência de disco impressionante e armazenamento em cache poderoso.
- Processamento rápido: Comparado com outros frameworks tradicionais usados para processamento de Big Data, o framework PySpark é bem rápido.
- Funciona bem com RDDs: Python é tipado dinamicamente para uma linguagem de programação, o que ajuda a trabalhar com conjuntos de dados distribuídos resilientes.
O que é PySpark?
Este tutorial do Pyspark permitirá que você entenda o que é o PySpark. PySpark é uma interface de programação de aplicativos (API) Python. A API é escrita em Python para formar uma conexão com o Apache Spark. Como você sabe, o Apache Spark lida com análise de big data. A linguagem de programação Scala é usada para criar o Apache Spark. Ele pode ser integrado por outras linguagens de programação, como Python, Java, SQL, R e o próprio Scala.
O PySpark é baseado em dois conjuntos de corroboração:
- API PySpark: Tem muitas amostras.
- API Spark Scala: Para programas PySpark, ele traduz o código Scala, que é uma linguagem de programação muito legível e baseada em trabalho, em código python e o torna compreensível.
O Py4J dá liberdade a um programa Python para se comunicar via código baseado em JVM. Ele ajuda o PySpark a se conectar com a Interface de programação de aplicativos baseada em Spark Scala.
Como definir o ambiente PySpark
Agora vamos discutir os diferentes ambientes em que o PySpark é iniciado e aplicado. Siga este tutorial do Spark Python para definir o PySpark:
- Auto-hospedado: Neste caso, você pode configurar uma coleção ou agrupar-se. Nesse ambiente, você pode usar clusters metálicos ou virtuais. Existem alguns projetos propostos, nomeadamente o Apache Ambari que são aplicáveis para este fim. No entanto, esse processo não é rápido o suficiente.
- Provedores de nuvem: nesse caso, na maioria das vezes, os clusters Spark são usados. Esse ambiente atende mais rápido que a auto-hospedagem. A Amazon Web Services (AWS) possui o Electronic MapReduce (EMR), enquanto o Good Clinical Practice (GCP) possui o Dataproc.
- Soluções de fornecedores: Databricks e Cloudera oferecem soluções Spark. É uma das maneiras mais rápidas de executar o PySpark.
Programação PySpark
Como todos sabemos, Python é uma linguagem de alto nível com várias bibliotecas. Ele desempenha um papel muito importante em Machine Learning e Data Analytics. Portanto, o PySpark é uma API para o spark que é escrito em Python. O Spark tem alguns atributos excelentes com alta velocidade, fácil acesso e aplicado para análise de streaming. Além disso, a estrutura do Spark e do Python ajuda o PySpark a acessar e processar big data com facilidade.
Os fundamentos do tutorial do Spark Python são discutidos a seguir.
Conjuntos de dados distribuídos resilientes (RDDs): Conjuntos de dados distribuídos resilientes ou RDDs são uma das principais rochas de construção da arquitetura de programação PySpark. Essa coleção é imutável e sofre transformações fracas. Cada palavra desta abreviatura tem um significado. É resiliente porque pode permitir erros e redescobrir dados. Ele é distribuído porque se expande sobre vários outros nós em um agrupamento. Dataset significa o armazenamento de dados de valores.
Leia também: Perguntas mais comuns da entrevista do PySpark
RDD suporta principalmente os seguintes tipos de operações
1) Transformações: As transformações seguindo o princípio de Lazy Evaluations, permitem operar execuções chamando uma ação sobre os dados a qualquer momento. Poucas das transformações são Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, classificadas por que são fornecidas por RDDs.

2) Ações: As operações RDD permitem que o PySpark aplique computação, passando o resultado de volta para o driver, que é chamado de ações.
Etapas para converter maiúsculas em minúsculas e dividir uma string
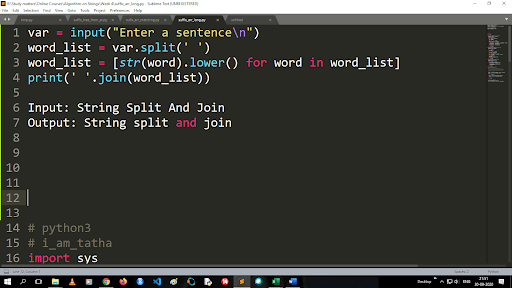
A saída da função split é do tipo lista. Para usar a função join o formato é “.join (sequence data type)” Com o código acima:
Entrada: String Split and Join
Saída: String split and join
Como ler um arquivo?
Leia um arquivo em Python chamando o arquivo .txt em um “modo de leitura”(r).
Passo 1) Abra o arquivo no modo de leitura
f=open(“amostra.txt”, ”r”)
Etapa 2) Usamos a função mode no código para verificar se o arquivo está no modo aberto.
f.mode == 'r':
Etapa 3) Use f.read para ler os dados do arquivo e armazená-los no conteúdo variável
conteudo = f.read()
Etapas na análise preditiva:
- Exploração de dados: você precisa coletar os dados, carregá-los e descobrir o tipo de dados, seu tipo e valor.
- Limpeza de dados: Você precisa encontrar os valores nulos, valores ausentes e outras redundâncias que possam atrapalhar o programa.
- Modelagem: Você deve selecionar um modelo preditivo.
- Avaliação: Você deve verificar a precisão de sua análise.
Transmissão PySpark
O PySpark Streaming nada mais é do que um sistema extensível e livre de erros. Ele obedece aos intervalos de lote RDD que variam de 500ms a slots de intervalo mais altos. De acordo com o tutorial do Spark Python , o Spark Streaming recebe alguns dados transmitidos como entrada.
Dependendo do número de intervalos de lote RDD, esses dados transmitidos são divididos em vários lotes e enviados para o Spark Engine. Algumas das fontes de onde os dados transmitidos são recebidos são Kinesis, Kafka, Apache Flume, etc. Usando estruturas de dados e algoritmos, os Spark Engines podem recuperar dados. Depois disso, os dados recuperados são encaminhados para vários sistemas de arquivos e bancos de dados.
Como dito anteriormente, o PySpark é uma API de alto nível. Apesar de qualquer falha ocorrer, a operação de streaming será executada apenas uma vez. Uma das principais distrações do PySpark Streaming é o Discretized Stream. Esses componentes de fluxo também são criados com a ajuda de lotes RDD. MLib, SQL, Dataframes são usados para ampliar a ampla gama de operações para Spark Streaming.
Neste Tutorial do PySpark , você fica sabendo que o Spark Stream recupera muitos dados de várias fontes. Isso é possível porque usa algoritmos complexos que incluem componentes altamente funcionais — Map, Reduce, Join e Window.
Estas são as coisas que resumem o que é o PySpark Streaming. Agora, neste tutorial do Spark python , vamos falar sobre algumas das vantagens do PySpark.
Vantagens do PySpark
Este segmento pode ser dividido em duas partes. Em primeiro lugar, você conhecerá as vantagens de usar o Python no PySpark e, em segundo lugar, as vantagens do próprio PySpark.
- Sendo uma linguagem de alto nível e amigável ao codificador, é fácil de aprender e executar.
- Uma API simples e inclusiva pode ser usada.
- Python oferece ao leitor uma excelente oportunidade de visualizar dados.
- Python tem uma ampla gama de bibliotecas. Alguns dos exemplos são Matplotlib, Pandas, Seaborn, NumPy, etc.
Agora, os seguintes são os recursos do Tutorial PySpark :
- O PySpark Streaming integra facilmente outras linguagens de programação como Java, Scala e R.
- O PySpark facilita que os programadores executem várias funções com Resilient Distributed Datasets (RDDs)
- O PySpark é preferido em relação a outras soluções de Big Data devido à sua alta velocidade, mecanismos poderosos de captura e persistência de disco para processamento de dados.
Deve ler: Tutorial Python para iniciantes
Inclusão de Data Science e Machine Learning no PySpark
Sendo uma linguagem de programação altamente funcional, o Python é a espinha dorsal da Ciência de Dados e do Machine Learning. Portanto, não é surpresa que Data Science e ML sejam partes integrantes do sistema PySpark. A Machine Learning Library (MLib) é o operador que controla a funcionalidade do Machine Learning no PySpark.
A seguir estão as vantagens de usar o Machine Learning no PySpark:
- É altamente extensível.
- Permanece funcional em sistemas distribuídos.
As principais funções do Machine Learning no PySpark:
- O Machine Learning prepara vários métodos e habilidades para o processamento adequado de dados. Estes são transformação, extração, hashing, seleção, etc.
- Ele fornece alguns algoritmos complexos, como mencionado anteriormente. Estes são usados para processar dados de várias fontes.
- Ele usa alguma interpretação matemática e dados estatísticos. Envolve álgebra linear e processos de avaliação de modelos.
Conclusão
Neste tutorial, discutimos os principais recursos, configuração do ambiente, leitura de um arquivo e muito mais.
Se você está curioso para aprender sobre ciência de dados, confira o Programa PG Executivo em Ciência de Dados do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1 -on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
O que é PySpark?
O PySpark foi formado para promover a colaboração do Apache Spark com o Python. Essa colaboração fornece uma API Python para Spark. Além disso, o PySpark permite que os usuários interajam com conjuntos de dados distribuídos resilientes (RDDs) no Apache Spark e no Python. O PySpark permite que os usuários integrem e interajam rapidamente com RDDs na linguagem de programação Python. Existem várias características que tornam o PySpark uma ferramenta tão excelente para trabalhar com grandes conjuntos de dados. Os engenheiros de dados estão recorrendo a essa ferramenta para fazer cálculos em grandes conjuntos de dados ou apenas para estudá-los. Isso é feito utilizando a biblioteca Py4j.
Quais são os casos de uso reais do PySpark?
Atualmente, o PySpark é usado para ETL de streaming. O streaming ETL limpa e agrega dados continuamente antes de serem entregues no armazenamento de dados. O PySpark auxilia no enriquecimento de dados, enriquecendo os dados ao vivo, integrando-os com dados estáticos, permitindo que as empresas realizem análises de dados em tempo real mais abrangentes. Pyspark também é usado para detecção de gatilho. Os gatilhos são usados por organizações financeiras para detectar transações fraudulentas e interrompê-las. Os gatilhos também são usados em hospitais para identificar alterações potencialmente prejudiciais à saúde enquanto monitoram os sinais vitais do paciente, fornecendo notificações automáticas aos cuidadores relevantes que podem tomar as medidas imediatas e necessárias.
Python e PySpark estão relacionados?
O PySpark é resultado da parceria Apache Spark e Python. Python é uma linguagem de programação de alto nível de uso geral, enquanto o Apache Spark é uma plataforma de computação em cluster de código aberto focada em velocidade, facilidade de uso e análise de streaming. Ele oferece um conjunto diversificado de bibliotecas e é usado principalmente para Machine Learning e Real-Time Streaming Analytics. Isso significa que é uma API Python para Spark que permite domar Big Data combinando a simplicidade do Python com o poder do Apache Spark.