
برنامج PySpark التعليمي للمبتدئين [مع أمثلة]
نشرت: 2020-10-07PySpark عبارة عن نظام أساسي قائم على السحابة يعمل كبنية خدمة. توفر المنصة بيئة لحساب ملفات البيانات الضخمة. يشير PySpark إلى تطبيق لغة برمجة Python بالاشتراك مع مجموعات Spark. يرتبط ارتباطًا وثيقًا بالبيانات الضخمة. دعنا نعرف أولاً ما تتعامل معه البيانات الضخمة لفترة وجيزة واحصل على نظرة عامة على برنامج PySpark التعليمي .
جدول المحتويات
ما هو استخدام PySpark؟
كواجهة برمجة تطبيقات Python لـ Spark تم إصدارها بواسطة مجتمع Apache Spark ، فهي تدعم Python مع Spark. استمر في قراءة هذه المقالة حول برنامج سبارك التعليمي بايثون لمعرفة المزيد عن الاستخدامات.
- باستخدام PySpark ، يمكن للمرء أن يتكامل ويعمل بكفاءة مع مجموعات البيانات الموزعة المرنة (RDDs) في Python.
- العديد من الميزات تجعل من PySpark إطار عمل ممتازًا لأنه يسهل العمل مع مجموعات البيانات الضخمة.
- يوفر PySpark مكتبات ذات نطاق واسع ، ويتم تسهيل التعلم الآلي وتحليلات البث في الوقت الفعلي بمساعدة PySpark.
- يستخدم PySpark بساطة Python وقوة Apache Spark المستخدمة في ترويض البيانات الكبيرة.
- مع ظهور البيانات الضخمة ، تم تطوير قوة تقنيات مثل Apache Spark و Hadoop.
- يمكن لعالم البيانات التعامل بكفاءة مع مجموعات البيانات الكبيرة ، كما أنه في متناول أي مطور Python.
قراءة: Dataframe في Apache PySpark
مفاهيم البيانات الضخمة في بايثون
Python هي لغة برمجة عالية المستوى تعرض أيضًا العديد من نماذج البرمجة مثل البرمجة الموجهة للكائنات (OOPs) ، والبرمجة الوظيفية غير المتزامنة.
تعد البرمجة الوظيفية نموذجًا مهمًا عند التعامل مع البيانات الضخمة. يتبع رمزًا متوازيًا ، مما يعني أنه يمكنك تشغيل الكود الخاص بك على العديد من وحدات المعالجة المركزية بالإضافة إلى أجهزة مختلفة تمامًا. يتمتع نظام PySpark البيئي بالقدرة على السماح لك باستخدام كود وظيفي وتوزيعه عبر مجموعة من أجهزة الكمبيوتر.
تتوفر الأفكار الأساسية للبرمجة الوظيفية للمبرمجين في المكتبة القياسية والمكونات المضمنة في Python.
يعتبر التلاعب بالبيانات الذي يحدث من خلال الوظائف دون أي صيانة خارجية للحالة هو تجسيد الفكرة الأساسية للبرمجة الوظيفية. يشير هذا إلى حقيقة أن التعليمات البرمجية الخاصة بك تتحايل على المتغيرات العالمية ولا تتلاعب بالبيانات في مكانها ولكنها تعرض دائمًا بيانات جديدة. تستخدم Python الكلمة الأساسية lambda لفضح الوظائف المجهولة.
تعلم دورة شهادة علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
بعض الميزات الرئيسية لبرنامج PySpark
- متعدد اللغات: PySpark هو أحد أكثر الأطر أهمية للحساب من خلال مجموعات البيانات الضخمة. وهو متوافق مع لغات متعددة أيضًا.
- استمرارية القرص والتخزين المؤقت: يوفر إطار عمل PySpark استمرارًا رائعًا للقرص وتخزينًا مؤقتًا قويًا.
- معالجة سريعة: بالمقارنة مع الأطر التقليدية الأخرى المستخدمة في معالجة البيانات الضخمة ، فإن إطار عمل PySpark سريع جدًا.
- يعمل جيدًا مع RDDs: يتم كتابة Python ديناميكيًا للغة برمجة ، مما يساعد على العمل مع مجموعات البيانات الموزعة المرنة.
ما هو PySpark؟
سيتيح لك هذا البرنامج التعليمي Pyspark فهم ماهية PySpark. PySpark هي واجهة برمجة تطبيقات Python (API). تمت كتابة API بلغة Python لتكوين اتصال مع Apache Spark. كما تعلم ، يتعامل Apache Spark مع تحليل البيانات الضخمة. تُستخدم لغة البرمجة Scala لإنشاء Apache Spark. يمكن دمجها مع لغات البرمجة الأخرى ، مثل Python و Java و SQL و R و Scala نفسها.
يعتمد PySpark على مجموعتين من التأييد:
- PySpark API: يحتوي على الكثير من العينات.
- Spark Scala API: بالنسبة لبرامج PySpark ، فإنه يترجم كود Scala الذي هو في حد ذاته لغة برمجة قابلة للقراءة وقائمة على العمل ، إلى كود Python ويجعلها مفهومة.
يمنح Py4J الحرية لبرنامج Python للتواصل عبر كود قائم على JVM. يساعد PySpark على التوصيل بواجهة برمجة التطبيقات المستندة إلى Spark Scala.
كيفية ضبط بيئة PySpark
الآن دعنا نناقش البيئات المختلفة التي يبدأ فيها PySpark ويتم التقديم عليها. اتبع هذا البرنامج التعليمي لـ Spark Python لتعيين PySpark:
- الاستضافة الذاتية: في هذه الحالة ، يمكنك إعداد مجموعة أو تجميعها بنفسك. في هذه البيئة ، يمكنك البحث عن استخدام مجموعات معدنية أو افتراضية. هناك بعض المشاريع المقترحة ، وهي Apache Ambari التي يمكن تطبيقها لهذا الغرض. ومع ذلك ، فإن هذه العملية ليست بالسرعة الكافية.
- موفرو السحابة: في هذه الحالة ، يتم استخدام مجموعات Spark في أغلب الأحيان. هذه البيئة تخدم بشكل أسرع من الاستضافة الذاتية. خدمات أمازون ويب (AWS) لديها MapReduce الإلكترونية (EMR) ، في حين أن الممارسة السريرية الجيدة (GCP) لديها Dataproc.
- حلول البائعين: Databricks و Cloudera تقدم حلول Spark. إنها إحدى أسرع الطرق لتشغيل PySpark.
برمجة PySpark
كما نعلم جميعًا ، فإن Python هي لغة عالية المستوى بها العديد من المكتبات. إنها تلعب دورًا مهمًا للغاية في التعلم الآلي وتحليلات البيانات. لذلك ، يعد PySpark واجهة برمجة تطبيقات للشرارة المكتوبة بلغة Python. يحتوي Spark على بعض السمات الممتازة التي تتميز بالسرعة العالية وسهولة الوصول والمطبقة لتحليلات البث. بالإضافة إلى ذلك ، يساعد إطار عمل Spark و Python على الوصول إلى البيانات الضخمة ومعالجتها بسهولة.
تتم مناقشة أساسيات برنامج سبارك التعليمي بايثون في ما يلي.
مجموعات البيانات الموزعة المرنة (RDDs): تعد مجموعات البيانات الموزعة المرنة أو RDDs أحد صخور البناء الأساسية لهندسة برمجة PySpark. هذه المجموعة غير قابلة للتغيير وتخضع لتحولات ضعيفة. كل كلمة من هذا الاختصار لها مغزى. إنه مرن لأنه يمكن أن يسمح بالأخطاء ويمكنه إعادة اكتشاف البيانات. يتم توزيعه لأنه يتمدد على عقد أخرى مختلفة في كتلة. مجموعة البيانات تعني تخزين بيانات القيم.
اقرأ أيضًا: أسئلة مقابلة PySpark الأكثر شيوعًا
يدعم RDD بشكل أساسي أنواع العمليات التالية
1) التحويلات: تسمح لك التحويلات التي تتبع مبدأ التقييمات الكسولة بتشغيل عمليات الإعدام من خلال استدعاء إجراء على البيانات في أي وقت. قليل من التحويلات هي خريطة ، خريطة مسطحة ، مرشح ، مميز ، تقليل حسب المفتاح ، أقسام الخريطة ، الفرز التي يتم توفيرها بواسطة RDDs.

2) الإجراءات: تسمح عمليات RDD لبرنامج PySpark بتطبيق الحساب ، وإعادة النتيجة إلى السائق ، وهو ما يسمى الإجراءات.
خطوات تحويل الأحرف الكبيرة إلى أحرف صغيرة وتقسيم سلسلة
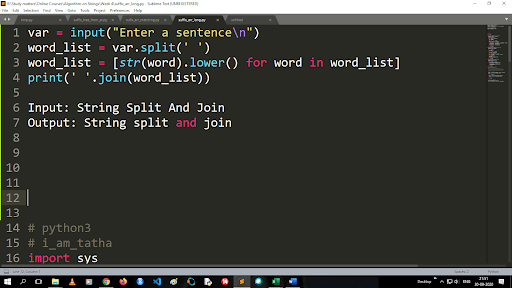
ناتج وظيفة الانقسام من نوع القائمة. لاستخدام وظيفة الانضمام ، يكون التنسيق هو ".join (نوع بيانات التسلسل)" مع الرمز أعلاه:
الإدخال: تقسيم السلسلة والانضمام
الإخراج: تقسيم السلسلة والانضمام
كيف تقرأ الملف؟
اقرأ ملفًا في Python عن طريق استدعاء ملف .txt في "وضع القراءة" (r).
الخطوة 1) افتح الملف في وضع القراءة
f = open ("sample.txt"، "r")
الخطوة 2) نستخدم وظيفة الوضع في الكود للتحقق من أن الملف في وضع الفتح.
f.mode == 'r':
الخطوة 3) استخدم f.read لقراءة بيانات الملف وتخزينها في محتوى متغير
المحتويات = f.read ()
خطوات في التحليل التنبئي:
- استكشاف البيانات: عليك جمع البيانات وتحميلها ومعرفة نوع البيانات ونوعها وقيمتها.
- تنظيف البيانات: يجب عليك العثور على القيم الخالية والقيم المفقودة والتكرار الأخرى التي قد تعيق البرنامج.
- النمذجة: عليك تحديد نموذج تنبؤي.
- التقييم: عليك التحقق من دقة تحليلك.
تدفق PySpark
PySpark Streaming ليس سوى نظام قابل للتوسيع وخالي من الأخطاء. إنه يلتزم بفترات دفعات RDD التي تتراوح من 500 مللي ثانية إلى فتحات الفاصل الزمني الأعلى. وفقًا لبرنامج تعليمي شرارة Python ، يتم إعطاء Spark Streaming بعض البيانات المتدفقة كمدخلات.
اعتمادًا على عدد فترات دفعات RDD ، يتم تقسيم هذه البيانات المتدفقة إلى دفعات عديدة ويتم إرسالها إلى Spark Engine. بعض المصادر التي يتم تلقي البيانات المتدفقة منها هي Kinesis و Kafka و Apache Flume وما إلى ذلك باستخدام هياكل البيانات والخوارزميات ، يمكن لـ Spark Engines استرداد البيانات. بعد ذلك ، يتم إرسال البيانات المسترجعة إلى أنظمة الملفات وقواعد البيانات المختلفة.
كما ذكرنا سابقًا ، يعد PySpark واجهة برمجة تطبيقات عالية المستوى. على الرغم من حدوث أي فشل ، سيتم تنفيذ عملية البث مرة واحدة فقط. أحد مصادر التشتيت الرئيسية في PySpark Streaming هو Discretized Stream. تم تصميم مكونات الدفق هذه أيضًا بمساعدة دفعات RDD. تُستخدم MLib و SQL و Dataframes لتوسيع نطاق واسع من العمليات لـ Spark Streaming.
في هذا البرنامج التعليمي لـ PySpark ، ستتعرف على أن Spark Stream يسترد الكثير من البيانات من مصادر مختلفة. هذا ممكن لأنه يستخدم خوارزميات معقدة تتضمن مكونات عالية الوظائف - الخريطة ، والحد ، والانضمام ، والنافذة.
هذه هي الأشياء التي تلخص ماهية PySpark Streaming. الآن في برنامج Python التعليمي الخاص بشركة Spark ، دعنا نتحدث عن بعض مزايا PySpark.
مزايا PySpark
يمكن تقسيم هذا الجزء إلى جزأين. بادئ ذي بدء ، ستتعرف على مزايا استخدام Python في PySpark وثانيًا مزايا PySpark نفسها.
- نظرًا لكونها لغة رفيعة المستوى وملائمة للمبرمجين ، فمن السهل تعلمها وتنفيذها.
- يمكن استخدام واجهة برمجة تطبيقات بسيطة وشاملة.
- تمنح Python القارئ فرصة ممتازة لتصور البيانات.
- يوجد في بايثون مجموعة كبيرة من المكتبات. بعض الأمثلة هي Matplotlib و Pandas و Seaborn و NumPy وما إلى ذلك.
الآن ، فيما يلي ميزات برنامج PySpark التعليمي :
- يدمج PySpark Streaming لغات البرمجة الأخرى بسهولة مثل Java و Scala و R.
- تسهل PySpark المبرمجين لأداء العديد من الوظائف باستخدام مجموعات البيانات الموزعة المرنة (RDDs)
- يُفضل PySpark على حلول البيانات الكبيرة الأخرى نظرًا لسرعته العالية وآلياته القوية في الالتقاط والقرص لمعالجة البيانات.
يجب أن تقرأ: دروس بايثون للمبتدئين
تضمين علوم البيانات والتعلم الآلي في PySpark
نظرًا لكونها لغة برمجة وظيفية للغاية ، فإن Python هي العمود الفقري لعلوم البيانات والتعلم الآلي. لذلك ، ليس من المستغرب أن يكون علم البيانات و ML جزءًا لا يتجزأ من نظام PySpark. مكتبة التعلم الآلي (MLib) هي المشغل الذي يتحكم في وظائف التعلم الآلي في PySpark.
فيما يلي مزايا استخدام التعلم الآلي في PySpark:
- إنه قابل للتمدد للغاية.
- تظل وظيفية في الأنظمة الموزعة.
الوظائف الرئيسية للتعلم الآلي في PySpark:
- يعد التعلم الآلي أساليب ومهارات مختلفة للمعالجة السليمة للبيانات. هذه هي التحويل ، الاستخراج ، التجزئة ، الاختيار ، إلخ.
- يوفر بعض الخوارزميات المعقدة ، كما ذكرنا سابقًا. تستخدم هذه لمعالجة البيانات من مصادر مختلفة.
- يستخدم بعض التفسيرات الرياضية والبيانات الإحصائية. يتضمن الجبر الخطي وعمليات تقييم النموذج.
خاتمة
في هذا البرنامج التعليمي ، ناقشنا الميزات الرئيسية ، وضبط البيئة ، وقراءة ملف والمزيد.
إذا كنت مهتمًا بالتعرف على علوم البيانات ، فراجع برنامج IIIT-B & upGrad التنفيذي PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1 - في 1 مع موجهين في الصناعة ، أكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هو PySpark؟
تم تشكيل PySpark لتعزيز تعاون Apache Spark مع Python. يوفر هذا التعاون واجهة برمجة تطبيقات Python لـ Spark. علاوة على ذلك ، يتيح PySpark للمستخدمين التفاعل مع مجموعات البيانات الموزعة المرنة (RDDs) في Apache Spark و Python. يسمح PySpark للمستخدمين بالتكامل والتفاعل بسرعة مع RDDs في لغة برمجة Python. هناك العديد من الخصائص التي تجعل من PySpark أداة ممتازة للعمل مع مجموعات البيانات الكبيرة. يلجأ مهندسو البيانات إلى هذه الأداة لإجراء عمليات حسابية على مجموعات بيانات ضخمة أو لمجرد دراستها. يتم تحقيق ذلك من خلال استخدام مكتبة Py4j.
ما هي حالات الاستخدام الواقعية لبرنامج PySpark؟
يتم استخدام PySpark حاليًا لتدفق ETL. يؤدي دفق ETL إلى تنظيف البيانات وتجميعها بشكل مستمر قبل تسليمها إلى تخزين البيانات. تساعد PySpark في إثراء البيانات من خلال إثراء البيانات الحية من خلال دمجها مع البيانات الثابتة ، مما يسمح للشركات بإجراء تحليل أكثر شمولاً للبيانات في الوقت الفعلي. يستخدم Pyspark أيضًا للكشف عن الزناد. يتم استخدام المشغلات من قبل المؤسسات المالية لاكتشاف المعاملات الاحتيالية وإيقافها في مساراتها. تُستخدم المحفزات أيضًا في المستشفيات لتحديد التغيرات الصحية التي قد تكون ضارة أثناء مراقبة العلامات الحيوية للمريض ، وتقديم إخطارات تلقائية لمقدمي الرعاية المعنيين الذين قد يتخذون بعد ذلك الإجراءات اللازمة والفورية.
هل Python و PySpark مرتبطان؟
PySpark هو نتيجة شراكة Apache Spark و Python. Python هي لغة برمجة للأغراض العامة وعالية المستوى ، في حين أن Apache Spark عبارة عن منصة حوسبة عنقودية مفتوحة المصدر تركز على السرعة وسهولة الاستخدام وتدفق التحليلات. يقدم مجموعة متنوعة من المكتبات ويستخدم في الغالب للتعلم الآلي وتحليلات البث في الوقت الفعلي. هذا يعني أنها واجهة برمجة تطبيقات Python لـ Spark والتي تمكنك من ترويض البيانات الضخمة من خلال الجمع بين بساطة Python وقوة Apache Spark.