
Tutorial PySpark per principianti [con esempi]
Pubblicato: 2020-10-07PySpark è una piattaforma basata su cloud che funziona come un'architettura di servizio. La piattaforma fornisce un ambiente per il calcolo dei file Big Data. PySpark si riferisce all'applicazione del linguaggio di programmazione Python in associazione con i cluster Spark. È profondamente associato ai Big Data. Facci sapere prima brevemente di cosa trattano i Big Data e ottieni una panoramica del tutorial di PySpark .
Sommario
A cosa serve PySpark?
In quanto API Python per Spark rilasciata dalla comunità Apache Spark, supporta Python con Spark. Continua a leggere questo articolo su Spark tutorial Python per saperne di più sugli usi.
- Con l'uso di PySpark, è possibile integrarsi e lavorare in modo efficiente con Resilient Distributed Dataset (RDD) in Python.
- Numerose funzionalità rendono PySpark un framework eccellente in quanto facilita il lavoro con enormi set di dati.
- PySpark fornisce librerie di un'ampia gamma e Machine Learning e Real-Time Streaming Analytics sono semplificati con l'aiuto di PySpark.
- PySpark sfrutta la semplicità di Python e la potenza di Apache Spark utilizzato per domare i Big Data.
- Con l'avvento dei Big Data, è stata sviluppata la potenza di tecnologie come Apache Spark e Hadoop.
- Un data scientist può gestire in modo efficiente set di dati di grandi dimensioni, essendo alla portata di qualsiasi sviluppatore Python.
Leggi: Dataframe in Apache PySpark
Concetti di Big Data in Python
Python è un linguaggio di programmazione di alto livello che espone anche molti paradigmi di programmazione come la programmazione orientata agli oggetti (OOP), la programmazione asincrona e funzionale.
La programmazione funzionale è un paradigma importante quando si ha a che fare con i Big Data. Segue un codice parallelo, il che significa che puoi eseguire il tuo codice su diverse CPU e macchine completamente diverse. L'ecosistema PySpark ha il potere di consentirti di utilizzare codice funzionale e distribuirlo su un cluster di computer.
Le idee di base per la programmazione funzionale per i programmatori sono disponibili nella libreria standard e nei built-in di Python.
La manipolazione dei dati che avviene attraverso funzioni senza alcun mantenimento dello stato esterno è l'incarnazione dell'idea centrale della programmazione funzionale. Questo sta per il fatto che il tuo codice aggira le variabili globali e non manipola i dati sul posto ma restituisce sempre nuovi dati. Python usa la parola chiave lambda per esporre funzioni anonime.
Impara il corso di certificazione della scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Alcune caratteristiche chiave di PySpark
- Polyglot: PySpark è uno dei framework più apprezzabili per il calcolo attraverso enormi set di dati. È compatibile anche con più lingue.
- Persistenza del disco e memorizzazione nella cache: il framework PySpark offre un'impressionante persistenza del disco e una potente memorizzazione nella cache.
- Elaborazione veloce: rispetto agli altri framework tradizionali utilizzati per l'elaborazione di Big Data, il framework PySpark è piuttosto veloce.
- Funziona bene con RDD: Python è tipizzato dinamicamente per un linguaggio di programmazione, che aiuta a lavorare con set di dati distribuiti resilienti.
Cos'è PySpark?
Questo tutorial su Pyspark ti farà capire cos'è PySpark. PySpark è un'API (Application Programming Interface) Python. L'API è scritta in Python per creare una connessione con Apache Spark. Come sapete, Apache Spark si occupa di analisi dei big data. Il linguaggio di programmazione Scala viene utilizzato per creare Apache Spark. Può essere integrato da altri linguaggi di programmazione, ovvero Python, Java, SQL, R e Scala stesso.
PySpark si basa su due serie di conferme:
- API PySpark: ha molti campioni.
- API Spark Scala: per i programmi PySpark, traduce il codice Scala, che è esso stesso un linguaggio di programmazione molto leggibile e basato sul lavoro, in codice Python e lo rende comprensibile.
Py4J dà la libertà a un programma Python di comunicare tramite codice basato su JVM. Aiuta PySpark a collegarsi con l'interfaccia di programmazione dell'applicazione basata su Spark Scala.
Come impostare l'ambiente PySpark
Ora discutiamo i diversi ambienti in cui PySpark inizia e viene richiesto. Segui questo tutorial di spark Python per impostare PySpark:
- Self-hosted: in questo caso, puoi impostare una raccolta o raggrupparti. In questo ambiente, puoi cercare di utilizzare cluster metallici o virtuali. Ci sono alcuni progetti proposti, vale a dire Apache Ambari che sono applicabili a questo scopo. Tuttavia, questo processo non è abbastanza veloce.
- Provider cloud: in questo caso, il più delle volte vengono utilizzati i cluster Spark. Questo ambiente è più veloce dell'hosting automatico. Amazon Web Services (AWS) ha Electronic MapReduce (EMR), mentre Good Clinical Practice (GCP) ha Dataproc.
- Soluzioni dei fornitori: Databricks e Cloudera forniscono soluzioni Spark. È uno dei modi più veloci per eseguire PySpark.
Programmazione PySpark
Come tutti sappiamo, Python è un linguaggio di alto livello con diverse librerie. Svolge un ruolo molto importante nel Machine Learning e nell'analisi dei dati. Pertanto, PySpark è un'API per la scintilla scritta in Python. Spark ha alcuni attributi eccellenti con alta velocità, facile accesso e applicazione per l'analisi in streaming. Inoltre, il framework di Spark e Python aiuta PySpark ad accedere ed elaborare facilmente i big data.
Gli elementi essenziali di Spark tutorial Python sono discussi di seguito.
Set di dati distribuiti resilienti (RDD): i set di dati distribuiti resilienti o RDD sono una delle pietre miliari dell'architettura di programmazione PySpark. Questa collezione è immutabile e subisce deboli trasformazioni. Ogni parola di questa abbreviazione ha un significato. È resiliente perché può consentire errori e può riscoprire i dati. È distribuito perché si espande su vari altri nodi in un gruppo. Dataset sta per la memorizzazione dei dati dei valori.
Leggi anche: Domande più comuni sull'intervista a PySpark
RDD supporta principalmente i seguenti tipi di operazioni
1) Trasformazioni: Trasformazioni che seguono il principio delle Lazy Evaluation, consentono di operare esecuzioni richiamando un'azione sui dati in qualsiasi momento. Poche delle trasformazioni sono Mappa, Mappa piatta, Filtro, Distinta, Riduci per chiave, Partizioni mappa, ordinate in base alle quali sono fornite da RDD.

2) Azioni: le operazioni RDD consentono a PySpark di applicare il calcolo, passando il risultato al driver, che viene chiamato azioni.
Passaggi per convertire maiuscolo in minuscolo e dividere una stringa
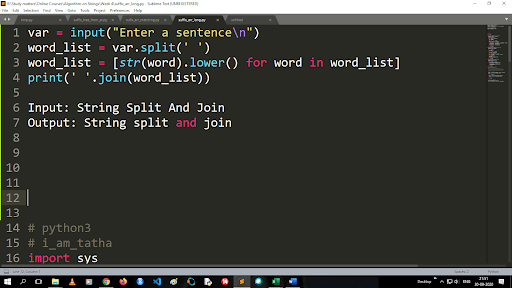
L'output della funzione di divisione è di tipo elenco. Per utilizzare la funzione join il formato è “.join (sequence data type)” Con il codice sopra:
Input: String Split and Join
Output: stringa divisa e unisci
Come leggere un file?
Leggi un file in Python chiamando il file .txt in una "modalità di lettura"(r).
Passaggio 1) Apri il file in modalità di lettura
f=open(“campione.txt”, ”r”)
Passaggio 2) Utilizziamo la funzione modalità nel codice per verificare che il file sia in modalità aperta.
f.mode == 'r':
Passaggio 3) Utilizzare f.read per leggere i dati del file e archiviarli in contenuto variabile
contenuto = f.leggi()
Fasi dell'analisi predittiva:
- Esplorazione dei dati: devi raccogliere i dati, caricarli e capire il tipo di dati, il loro tipo e il valore.
- Pulizia dei dati: devi trovare i valori nulli, i valori mancanti e altre ridondanza che potrebbero ostacolare il programma.
- Modellazione: è necessario selezionare un modello predittivo.
- Valutazione: devi verificare l'accuratezza della tua analisi.
Streaming di PySpark
PySpark Streaming non è altro che un sistema estensibile e privo di errori. Rispetta gli intervalli batch RDD che vanno da 500 ms a slot di intervallo più elevati. Secondo spark tutorial Python , Spark Streaming riceve alcuni dati in streaming come input.
A seconda del numero di intervalli di batch RDD, questi dati in streaming vengono suddivisi in numerosi batch e inviati a Spark Engine. Alcune delle fonti da cui vengono ricevuti i dati in streaming sono Kinesis, Kafka, Apache Flume, ecc. Utilizzando le strutture dei dati e gli algoritmi, Spark Engines può recuperare i dati. Successivamente, i dati recuperati vengono inoltrati a vari file system e database.
Come affermato in precedenza, PySpark è un'API di alto livello. Nonostante l'eventuale errore, l'operazione di streaming verrà eseguita una sola volta. Una delle principali distrazioni del PySpark Streaming è il Discretized Stream. Questi componenti di flusso sono anche costruiti con l'aiuto di batch RDD. MLib, SQL, Dataframes vengono utilizzati per ampliare l'ampia gamma di operazioni per Spark Streaming.
In questo tutorial su PySpark , scoprirai che Spark Stream recupera molti dati da varie fonti. Ciò è possibile perché utilizza algoritmi complessi che includono componenti altamente funzionali: Mappa, Riduci, Unisci e Finestra.
Queste sono le cose che riassumono cos'è lo streaming di PySpark. Ora in questo tutorial di Spark python , parliamo di alcuni dei vantaggi di PySpark.
Vantaggi di PySpark
Questo segmento può essere diviso in due parti. Prima di tutto, conoscerai i vantaggi dell'utilizzo di Python in PySpark e, in secondo luogo, i vantaggi di PySpark stesso.
- Essendo un linguaggio di alto livello e intuitivo per i programmatori, è facile da imparare ed eseguire.
- È possibile utilizzare un'API semplice e inclusiva.
- Python offre al lettore un'eccellente opportunità per visualizzare i dati.
- Python ha una vasta gamma di librerie. Alcuni degli esempi sono Matplotlib, Pandas, Seaborn, NumPy, ecc.
Ora, le seguenti sono le caratteristiche di PySpark Tutorial :
- PySpark Streaming integra facilmente altri linguaggi di programmazione come Java, Scala e R.
- PySpark facilita ai programmatori l'esecuzione di diverse funzioni con i set di dati distribuiti resilienti (RDD)
- PySpark è preferito rispetto ad altre soluzioni Big Data a causa dei suoi meccanismi di elaborazione dei dati ad alta velocità, potente cattura e disco persistente.
Da leggere: Tutorial Python per principianti
Inclusione di Data Science e Machine Learning in PySpark
Essendo un linguaggio di programmazione altamente funzionale, Python è la spina dorsale di Data Science e Machine Learning. Pertanto, non sorprende che Data Science e ML siano le parti integranti del sistema PySpark. Machine Learning Library (MLib) è l'operatore che controlla la funzionalità di Machine Learning in PySpark.
Di seguito sono riportati i vantaggi dell'utilizzo di Machine Learning in PySpark:
- È altamente estensibile.
- Rimane funzionale nei sistemi distribuiti.
Le principali funzioni di Machine Learning in PySpark:
- Machine Learning prepara vari metodi e competenze per il corretto trattamento dei dati. Si tratta di trasformazione, estrazione, hashing, selezione, ecc.
- Fornisce alcuni algoritmi complessi, come accennato in precedenza. Questi sono usati per elaborare dati da varie fonti.
- Utilizza alcune interpretazioni matematiche e dati statistici. Implica l'algebra lineare e processi di valutazione del modello.
Conclusione
In questo tutorial, abbiamo discusso le funzionalità chiave, l'impostazione dell'ambiente, la lettura di un file e altro ancora.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al programma Executive PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 -on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Cos'è PySpark?
PySpark è stata costituita per promuovere la collaborazione di Apache Spark con Python. Questa collaborazione fornisce un'API Python per Spark. Inoltre, PySpark consente agli utenti di interagire con i set di dati distribuiti resilienti (RDD) in Apache Spark e Python. PySpark consente agli utenti di integrare e interagire rapidamente con gli RDD nel linguaggio di programmazione Python. Ci sono diverse caratteristiche che rendono PySpark uno strumento così eccellente per lavorare con grandi set di dati. I data engineer si stanno rivolgendo a questo strumento per eseguire calcoli su enormi set di dati o semplicemente per studiarli. Ciò si ottiene utilizzando la libreria Py4j.
Quali sono i casi d'uso nella vita reale di PySpark?
PySpark è attualmente utilizzato per lo streaming ETL. Lo streaming ETL pulisce e aggrega continuamente i dati prima che vengano consegnati nell'archiviazione dei dati. PySpark aiuta nell'arricchimento dei dati arricchendo i dati in tempo reale integrandoli con dati statici, consentendo alle aziende di eseguire analisi dei dati in tempo reale più complete. Pyspark viene utilizzato anche per il rilevamento dei trigger. I trigger vengono utilizzati dalle organizzazioni finanziarie per rilevare le transazioni fraudolente e bloccarle. I trigger vengono utilizzati anche negli ospedali per identificare i cambiamenti sanitari potenzialmente dannosi durante il monitoraggio dei segni vitali del paziente, fornendo notifiche automatiche agli operatori sanitari interessati che possono quindi intraprendere azioni tempestive e necessarie.
Python e PySpark sono correlati?
PySpark è il risultato della partnership tra Apache Spark e Python. Python è un linguaggio di programmazione generico e di alto livello, mentre Apache Spark è una piattaforma di cluster computing open source incentrata su velocità, facilità d'uso e analisi di streaming. Offre un insieme diversificato di librerie ed è utilizzato principalmente per l'apprendimento automatico e l'analisi dello streaming in tempo reale. Significa che è un'API Python per Spark che ti consente di domare i Big Data combinando la semplicità di Python con la potenza di Apache Spark.