
Go и вызов общему искусственному интеллекту
Опубликовано: 2018-02-15Эта статья направлена на изучение связи между игрой «Го» и искусственным интеллектом. Цель состоит в том, чтобы ответить на вопросы: Что делает игру Го особенной? Почему компьютеру было сложно освоить игру Го? Почему компьютерная программа смогла победить гроссмейстера в 1997 году? Почему потребовалось почти два десятилетия, чтобы взломать Go?
«Джентльмены не должны тратить время на банальные игры — они должны изучать го»
- Конфуций
На самом деле специалисты по искусственному интеллекту считали, что компьютеры смогут победить чемпиона мира по го только к 2027 году. Благодаря DeepMind, компании искусственного интеллекта под эгидой Google, эта грандиозная задача была решена десятью годами ранее. В этой статье речь пойдет о технологиях, которые DeepMind использовала для победы над чемпионом мира по го. Наконец, в этом посте обсуждается, как эту технологию можно использовать для решения некоторых сложных реальных проблем.
Оглавление
Иди - что это?
Го — китайская стратегическая настольная игра, которой уже 3000 лет, и которая сохраняет свою популярность на протяжении веков. В Го играют десятки миллионов людей по всему миру. Это настольная игра для двух игроков с простыми правилами и интуитивно понятной стратегией. Для игры в эту игру используются доски разных размеров; профессионалы используют доску 19×19.

Игра начинается с пустой доски. Затем каждый игрок по очереди кладет черные и белые камни (черные ходят первыми) на доску, на пересечение линий (в отличие от шахмат, где вы расставляете фигуры по клеткам). Игрок может захватить камни противника, окружив его со всех сторон. За каждый захваченный камень игроку начисляются очки. Цель игры состоит в том, чтобы занять как можно больше территории на доске, а также захватить камни противников.
Го — это созидание, в отличие от шахмат, где главное — разрушение. Го требует свободы, творчества, интуиции, баланса, стратегии и интеллектуальной глубины, чтобы овладеть игрой. Игра в го задействует оба полушария мозга. Фактически, сканирование мозга игроков в го показало, что го помогает в развитии мозга, улучшая связи между обоими полушариями мозга.
Нейронные сети для чайников: подробное руководство
Go и вызов искусственному интеллекту (ИИ)
Компьютеры смогли освоить крестики-нолики в 1952 году . Deep Blue смог победить гроссмейстера по шахматам Гарри Каспарова в 1997 году . Компьютерная программа смогла победить чемпиона мира в Jeopardy (популярная американская игра) в 2001 году . AlphaGo от DeepMind смог победить чемпиона мира по го в 2016 году . Почему считается, что компьютерной программе сложно освоить игру в го?
В шахматы играют на доске 8×8, тогда как в го используется доска размером 19×19. В начале шахматной партии у игрока будет 20 возможных ходов. В дебюте го у игрока может быть 361 возможный ход. Количество возможных позиций на доске го равно 10 в степени 170; больше, чем количество атомов в нашей Вселенной! Потенциальное количество позиций на доске делает гугол, умноженный на 10 в степени 100, более сложным, чем шахматы.
В шахматах для каждого шага перед игроком стоит выбор из 35 ходов. В среднем у игрока в го будет 250 возможных ходов на каждом шаге. В шахматах в любой заданной позиции компьютеру относительно легко провести перебор и выбрать наилучший возможный ход, который максимизирует шансы на победу. Поиск методом грубой силы невозможен в случае Go, так как потенциальное количество допустимых ходов, разрешенных для каждого шага, огромно.
Для компьютера освоить шахматы становится легче по ходу игры, потому что фигуры убираются с доски. В Го это становится сложнее для компьютерной программы, так как камни добавляются на доску по ходу игры. Как правило, игра в го длится в 3 раза дольше, чем игра в шахматы.
По всем этим причинам лучшая компьютерная программа Go смогла догнать чемпиона мира по Go только в 2016 году после огромного взрыва новых методов машинного обучения. Ученые, работающие в DeepMind, смогли создать компьютерную программу под названием AlphaGo , которая победила чемпиона мира Ли Сидола . Достижение поставленной задачи было непростым. Исследователи из DeepMind придумали много новых инноваций в процессе создания AlphaGo.
«Правила го настолько элегантны, органичны и строго логичны, что если разумные формы жизни существуют где-то еще во вселенной, они почти наверняка играют в го».
— Эдвард Ласкар
Нейронные сети: приложения в реальном мире
Как работает АльфаГо
AlphaGo — алгоритм общего назначения, а значит, его можно использовать и для решения других задач. Например, Deep Blue от IBM специально разработан для игры в шахматы. Правила игры в шахматы вместе с накопленными за века игры знаниями запрограммированы в мозг программы. Deep Blue нельзя использовать даже для таких тривиальных игр, как крестики-нолики. Он может делать только одну конкретную вещь, в которой он очень хорош, т.е. играть в шахматы. AlphaGo может научиться играть не только в го, но и в другие игры. Эти алгоритмы общего назначения составляют новую область исследований, называемую общим искусственным интеллектом.
AlphaGo использует самые современные методы — глубокие нейронные сети (DNN), обучение с подкреплением (RL), поиск по дереву Монте-Карло (MCTS), Deep Q Networks (DQN) (новый метод, представленный и популяризированный DeepMind, который сочетает в себе нейронные сети с обучением с подкреплением), и это лишь некоторые из них. Затем он новаторски комбинирует все эти методы для достижения сверхчеловеческого уровня мастерства в игре Го.
Давайте сначала посмотрим на каждый отдельный кусочек этой головоломки, прежде чем переходить к тому, как эти кусочки связаны вместе для достижения поставленной задачи.
Глубокие нейронные сети
DNN — это метод машинного обучения, частично вдохновленный функционированием человеческого мозга. Архитектура DNN состоит из слоев нейронов. DNN может распознавать закономерности в данных без явного программирования для этого.
Он сопоставляет входы с выходами, и никто специально не программирует его для этого. В качестве примера предположим, что мы загрузили в сеть много фотографий кошек и собак. В то же время мы также обучаем систему, сообщая ей (в виде меток), является ли конкретное изображение кошкой или собакой (это называется обучением с учителем). DNN научится распознавать узор на фотографиях, чтобы успешно отличать кошку от собаки. Основная цель обучения состоит в том, что когда DNN увидит новое изображение собаки или кошки, она сможет правильно классифицировать его, т.е. предсказать, кошка это или собака.
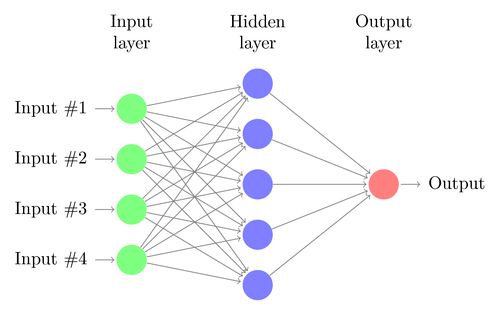
Давайте разберемся с архитектурой простой DNN. Количество нейронов во входном слое соответствует размеру входных данных. Предположим, что наши фотографии кошек и собак имеют размер 28×28. Каждая строка и столбец будут состоять из 28 пикселей, что в сумме дает 784 пикселя для каждого изображения. В таком случае входной слой будет состоять из 784 нейронов, по одному на каждый пиксель. Количество нейронов в выходном слое будет зависеть от количества классов, на которые необходимо классифицировать выходные данные. В этом случае выходной слой будет состоять из двух нейронов — один соответствует «кошке», другой — «собаке».
Следите за следующей большой вещью: машинное обучение
Между входным и выходным слоями будет много слоев нейронов (что является источником использования термина «глубокий» в «глубокой нейронной сети»). Они называются «скрытыми слоями». Количество скрытых слоев и количество нейронов в каждом слое не фиксировано. На самом деле изменение этих значений как раз и приводит к оптимизации производительности. Эти значения называются гиперпараметрами, и их необходимо настраивать в зависимости от решаемой проблемы. Эксперименты с нейронными сетями в основном связаны с поиском оптимального количества гиперпараметров.
Фаза обучения DNN будет состоять из прямого прохода и обратного прохода. Во-первых, все связи между нейронами инициализируются случайными весами. Во время прямого прохода в сеть подается одно изображение. Входные данные (пиксельные данные изображения) объединяются с параметрами сети (веса, смещения и функции активации) и передаются через скрытые слои вплоть до вывода, который возвращает вероятность того, что фотография принадлежит каждому классов.
Затем эта вероятность сравнивается с фактической меткой класса и вычисляется «ошибка». В этот момент выполняется обратный проход — эта информация об ошибке передается обратно по сети с помощью метода, называемого «обратное распространение». На начальных этапах обучения эта ошибка будет высокой, и хороший механизм обучения будет постепенно уменьшать эту ошибку.
Таким образом, DNN обучаются с прямым и обратным проходом до тех пор, пока веса не перестанут меняться (это называется сходимостью). Тогда ГНС смогут предсказывать и классифицировать изображения с высокой степенью точности, т. е. есть ли на картинке кошка или собака.

Исследования дали нам множество различных архитектур глубоких нейронных сетей. Для задач компьютерного зрения (то есть задач, связанных с изображениями) сверточные нейронные сети (CNN) традиционно давали хорошие результаты. Для задач, связанных с последовательностью — распознаванием речи или языковым переводом — рекуррентные нейронные сети (RNN) дают отличные результаты.
Руководство для начинающих по пониманию естественного языка
В случае с AlphaGo процесс был следующим: сначала сверточная нейронная сеть (CNN) обучалась на миллионах изображений позиций на доске. Затем сеть была проинформирована о последующем ходе, сыгранном экспертами-людьми в каждом случае на этапе обучения сети. Таким же образом, как упоминалось ранее, фактическое значение сравнивалось с выходными данными, и была найдена своего рода метрика «ошибки».
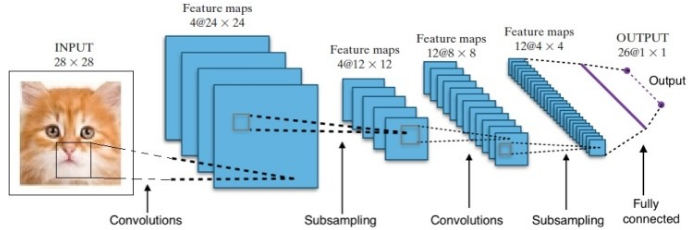
В конце обучения DNN выведет следующие ходы вместе с вероятностями, которые, вероятно, будут сыграны опытным игроком-человеком. Этот тип сети может предложить только шаг, который играет опытный игрок-человек. DeepMind смог достичь точности 60% в предсказании движения, которое сделает человек. Однако, чтобы победить человека-эксперта в Го, этого недостаточно. Выходные данные DNN далее обрабатываются Deep Reinforcement Network — подходом, разработанным DeepMind, который сочетает в себе глубокие нейронные сети и обучение с подкреплением.
Глубокое обучение с подкреплением
Обучение с подкреплением (RL) не является новой концепцией. Лауреат Нобелевской премии Иван Павлов экспериментировал с классическим условным рефлексом на собаках и открыл принципы обучения с подкреплением в 1902 году. RL также является одним из методов, с помощью которых люди осваивают новые навыки. Вы когда-нибудь задумывались, как дельфинов на шоу учат прыгать на такую большую высоту из воды? Именно с помощью РЛ. Сначала в бассейн погружают веревку, которая используется для подготовки дельфинов. Всякий раз, когда дельфин пересекает кабель сверху, он вознаграждается едой. Когда он не пересекает веревку, награда снимается. Постепенно дельфин поймет, что ему платят всякий раз, когда он проходит через шнур сверху. Высота веревки постепенно увеличивается, чтобы тренировать дельфина. 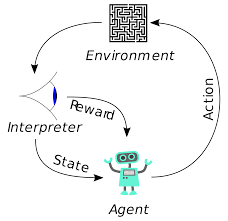
Генерация естественного языка: главное, что вам нужно знать
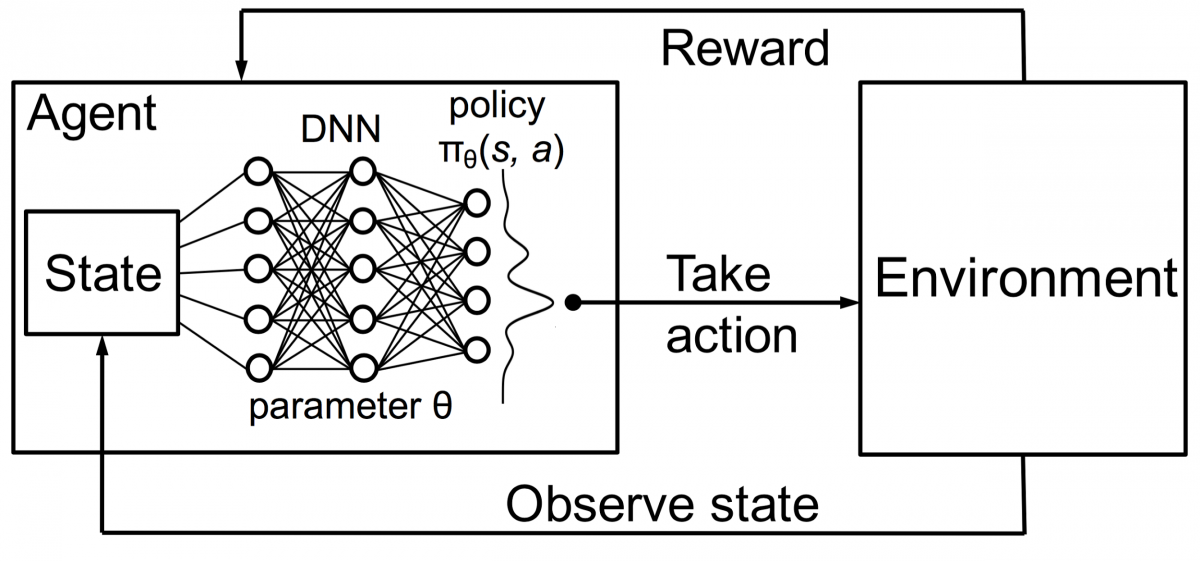
Агенты в обучении с подкреплением также обучаются по тому же принципу. Агент будет действовать и взаимодействовать с окружающей средой. Действие, предпринятое агентом, вызывает изменение среды. Далее агент получал обратную связь об окружении. Агент либо вознаграждается, либо нет, в зависимости от его действия и поставленной цели. Важным моментом является то, что эта цель прямо не заявлена для агента. При наличии достаточного количества времени агент научится максимизировать будущие вознаграждения.

Объединив это с DNN, DeepMind изобрел Deep Reinforcement Learning (DRL) или Deep Q Networks (DQN), где Q означает максимальное вознаграждение в будущем. DQN впервые были применены к играм Atari . DQN научился играть в разные типы игр Atari прямо из коробки. Прорывом стало то, что не требовалось явного программирования для представления различных видов игр Atari. Одна программа была достаточно умна, чтобы узнать обо всех различных средах игры, и благодаря самостоятельной игре смогла освоить многие из них.
В 2014 году DQN превзошел предыдущие методы машинного обучения в 43 из 49 игр (сейчас он протестирован более чем в 70 играх). Фактически, более чем в половине игр он работал на более чем 75% от уровня профессионального игрока-человека. В некоторых играх DQN даже придумывала удивительно дальновидные стратегии, которые позволяли ей набирать максимально достижимое количество очков — например, в Breakout она научилась сначала копать туннель с одного конца кирпичной стены, чтобы мяч отскакивал от нее. вокруг спины и выбить кирпичи сзади.
Политика и сети ценности
Внутри AlphaGo есть два основных типа сетей:
Одна из целей DQN от AlphaGo — выйти за рамки игры человека-эксперта и имитировать новые инновационные ходы, играя против себя миллионы раз и тем самым постепенно улучшая веса. Этот DQN имел 80% выигрышей по сравнению с обычными DNN. DeepMind решил объединить эти две нейронные сети (DNN и DQN), чтобы сформировать первый тип сети — «Сеть политик». Вкратце, задача политической сети состоит в том, чтобы уменьшить широту поиска следующего шага и предложить несколько хороших ходов, заслуживающих дальнейшего изучения.
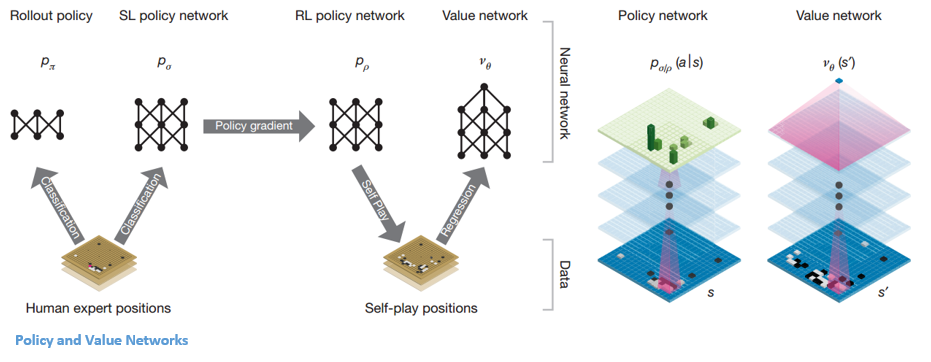 Как только сеть политик замораживается, она играет против самой себя миллионы раз. Эти игры генерируют новый набор данных Go, состоящий из различных позиций на доске и результатов игр. Этот набор данных используется для создания функции оценки. Второй тип функции — «Сеть ценности» — используется для прогнозирования исхода игры. Он учится использовать различные позиции на доске в качестве исходных данных и предсказывать исход игры и ее масштабы.
Как только сеть политик замораживается, она играет против самой себя миллионы раз. Эти игры генерируют новый набор данных Go, состоящий из различных позиций на доске и результатов игр. Этот набор данных используется для создания функции оценки. Второй тип функции — «Сеть ценности» — используется для прогнозирования исхода игры. Он учится использовать различные позиции на доске в качестве исходных данных и предсказывать исход игры и ее масштабы.
Объединение политик и сетей создания ценности
После всего этого обучения DeepMind наконец-то получил две нейронные сети — Policy и Value Networks. Сеть политик принимает положение доски в качестве входных данных и выводит распределение вероятностей как вероятность каждого из ходов в этой позиции. Сеть значений снова принимает положение доски в качестве входных данных и выводит единственное действительное число от 0 до 1. Если выход сети равен нулю, это означает, что белые полностью выигрывают, а 1 указывает на полную победу игрока с черными. камни.
Сеть политики оценивает текущие позиции, а сеть ценности оценивает будущие движения. Разделение задач DeepMind на эти две сети было одной из основных причин успеха AlphaGo.
Объединение политик и сетей ценности с поиском по дереву Монте-Карло (MCTS) и внедрением
Нейросетей самих по себе будет недостаточно. Чтобы выиграть в игре Го, требуется еще немного стратегии. Этот план достигается с помощью MCTS. Поиск по дереву Монте-Карло также помогает объединить две нейронные сети инновационным способом. Нейронные сети помогают в эффективном поиске следующего лучшего хода.
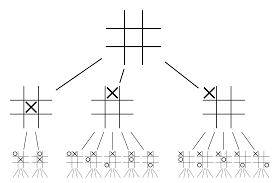
Давайте попробуем построить пример, который поможет вам визуализировать все это намного лучше. Представьте, что игра находится в новой позиции, с которой раньше не приходилось сталкиваться. В такой ситуации политическая сеть призвана оценить текущую ситуацию и возможные будущие пути; а также желательность путей и ценность каждого движения по сетям ценности, поддерживаемым развертываниями Монте-Карло.
Политическая сеть находит все возможные «хорошие» ходы, а сети ценности оценивают каждый из их результатов. В развертываниях Монте-Карло несколько тысяч случайных игр разыгрываются с позиций, распознаваемых сетью политик. Были проведены эксперименты, чтобы определить относительную важность сетей создания стоимости по сравнению с внедрением Монте-Карло. В результате этого эксперимента DeepMind присвоил 80% веса сетям создания ценности и 20% веса функции оценки развертывания Монте-Карло.
Сеть политик уменьшает ширину поиска с 200 с лишним возможных ходов до 4 или 5 лучших ходов. Сеть политик расширяет дерево из этих 4 или 5 шагов, которые требуют рассмотрения. Сеть значений помогает сократить глубину поиска по дереву, мгновенно возвращая результат игры из этой позиции. Наконец, выбирается ход с наибольшим значением Q, т. е. шаг с максимальной выгодой.
« В эту игру играют главным образом благодаря интуиции и ощущениям, и благодаря своей красоте, тонкости и интеллектуальной глубине она на протяжении веков захватывает человеческое воображение».
— Демис Хассабис
Применение AlphaGo к реальным задачам
Видение DeepMind с их веб-сайта очень красноречиво: «Решите интеллект. Используйте эти знания, чтобы сделать мир лучше». Конечная цель этого алгоритма — сделать его универсальным, чтобы его можно было использовать для решения сложных реальных задач. AlphaGo от DeepMind — это значительный шаг вперед в поисках ОИИ. DeepMind успешно использовала свою технологию для решения реальных проблем — давайте рассмотрим несколько примеров:
Снижение энергопотребления
Искусственный интеллект DeepMind был успешно использован для снижения затрат на охлаждение центра обработки данных Google на 40%. В любой крупномасштабной энергоемкой среде это улучшение является феноменальным шагом вперед. Одним из основных источников энергопотребления центра обработки данных является охлаждение. Для поддержания работоспособности необходимо отводить много тепла, выделяемого при работе серверов. Это достигается за счет крупномасштабного промышленного оборудования, такого как насосы, чиллеры и градирни. Поскольку среда центра обработки данных очень динамична, работать с оптимальной энергоэффективностью сложно. Для решения этой проблемы использовался искусственный интеллект DeepMind.
Сначала они использовали исторические данные, собранные тысячами датчиков в центре обработки данных. Используя эти данные, они обучили ансамбль DNN средней будущей эффективности использования энергии (PUE). Поскольку это алгоритм общего назначения, планируется, что он будет применяться и к другим задачам в среде центра обработки данных.
Возможные применения этой технологии включают в себя получение большего количества энергии от той же единицы входных данных, снижение потребления энергии и воды при производстве полупроводников и т. д. DeepMind объявила в своем блоге, что эти знания будут опубликованы в будущей публикации, чтобы другие центры обработки данных, промышленные операторы и, в конечном счете, окружающая среда могут извлечь большую выгоду из этого важного шага.
Планирование лучевой терапии рака головы и шеи
DeepMind сотрудничает с отделением лучевой терапии больницы Лондонского университетского колледжа NHS Foundation Trust, мирового лидера в области лечения рака.
Как большие данные и машинное обучение объединяются в борьбе с раком
У одного из 75 мужчин и одной из 150 женщин в течение жизни диагностируют рак ротовой полости. Из-за чувствительности структур и органов в области головы и шеи радиологам необходимо проявлять крайнюю осторожность при их лечении.
Перед проведением лучевой терапии необходимо подготовить подробную карту с областями, подлежащими лечению, и областями, которых следует избегать. Это известно как сегментация. Эта сегментированная карта загружается в рентгенографический аппарат, который затем нацеливается на раковые клетки, не повреждая здоровые клетки.
В случае рака области головы или шеи это кропотливая работа рентгенологов, так как затрагиваются очень чувствительные органы. Рентгенологам требуется около четырех часов, чтобы создать сегментированную карту для этой области. DeepMind с помощью своих алгоритмов стремится сократить время, необходимое для создания сегментированных карт, с четырех до одного часа. Это значительно высвободит время врача-рентгенолога. Что еще более важно, этот алгоритм сегментации можно использовать для других частей тела.
Подводя итог, AlphaGo четыре раза успешно обыграла 18-кратного чемпиона мира по го Ли Сидола в турнире до пяти побед в 2016 году. В 2017 году она даже обыграла команду лучших игроков мира. Он использует комбинацию DNN и DQN в качестве сети политик для разработки следующего лучшего хода и одну DNN в качестве сети ценности для оценки результата игры. Поиск по дереву Монте-Карло используется вместе с политиками и сетями ценности, чтобы уменьшить ширину и глубину поиска — они используются для улучшения функции оценки. Конечной целью этого алгоритма является не решение настольных игр, а изобретение алгоритма общего искусственного интеллекта. AlphaGo, несомненно, является большим шагом вперед в этом направлении.
Разница между наукой о данных, машинным обучением и большими данными!
Конечно, были и другие эффекты. Когда новость об игре AlphaGo против Ли Сидола стала вирусной, спрос на доски для го подскочил в десять раз. Многие магазины сообщали о случаях, когда доски Go заканчивались, и купить доску Go стало сложно.
К счастью, я только что нашел один и заказал его для себя и своего ребенка. Планируете купить доску и изучать Го?
Изучайте курсы машинного обучения в лучших университетах мира. Заработайте программы Masters, Executive PGP или Advanced Certificate Programs, чтобы ускорить свою карьеру.
Каковы ограничения глубокого обучения с подкреплением?
DL забывает о ранее полученных знаниях, когда вводятся новые данные или информация, поэтому не оспаривает их. Слишком сильное подкрепление иногда может привести к избытку состояний, что снижает эффективность. Из-за сложности моделей данных обучение обходится чрезвычайно дорого. Глубокое обучение также требует использования дорогих графических процессоров и сотен рабочих станций. В результате его использование становится менее экономичным.
Каковы недостатки использования поиска по дереву Монте-Карло?
Хотя MCTS является простым для выполнения алгоритмом, у него есть определенные недостатки. Когда дерево становится больше после нескольких итераций, требуется много памяти. Применительно к пошаговым играм может быть одна ветвь или путь, который ведет к проигрышу противнику в определенных условиях. В результате, он немного менее надежен. После многих итераций поиск по дереву Монте-Карло занимает много времени, чтобы определить наиболее эффективный путь.
Чем AlphaZero отличается от AlphaGo Zero?
Предыдущие версии AlphaGo включали небольшое количество функций, разработанных вручную, но AlphaGo Zero просто использует в качестве входных данных черные и белые камни с доски Go. Более ранние версии AlphaGo полагались на сеть политик для выбора следующего хода и сеть значений для оценки победителя игры с каждой позиции. Они объединены в AlphaGo Zero, что позволяет повысить эффективность обучения и оценки. Все эти различия способствуют повышению производительности и универсальности системы. Алгоритмическая корректировка, с другой стороны, делает систему намного более мощной и эффективной.