
Pergi dan Tantangan Kecerdasan Umum Buatan
Diterbitkan: 2018-02-15Artikel ini bertujuan untuk mengeksplorasi hubungan antara game 'Go' dan kecerdasan buatan. Tujuannya adalah untuk menjawab pertanyaan – Apa yang membuat game Go istimewa? Mengapa menguasai permainan Go sulit untuk komputer? Mengapa sebuah program komputer mampu mengalahkan grandmaster catur pada tahun 1997? Mengapa butuh hampir dua dekade untuk memecahkan Go?
“Tuan-tuan tidak boleh membuang waktu mereka untuk permainan sepele – mereka harus belajar Go”
– Konfusius
Faktanya, pakar kecerdasan buatan berpikir komputer hanya akan mampu mengalahkan juara dunia Go pada tahun 2027. Berkat DeepMind, sebuah perusahaan kecerdasan buatan di bawah payung Google, tugas berat ini dicapai satu dekade sebelumnya. Artikel ini akan berbicara tentang teknologi yang digunakan oleh DeepMind untuk mengalahkan juara dunia Go. Akhirnya, posting ini membahas bagaimana teknologi ini dapat digunakan untuk menyelesaikan beberapa masalah dunia nyata yang kompleks.
Daftar isi
Pergi - Apa itu?
Go adalah permainan papan strategi Tiongkok berusia 3000 tahun, yang telah mempertahankan popularitasnya selama berabad-abad. Dimainkan oleh puluhan juta orang di seluruh dunia, Go adalah permainan papan dua pemain dengan aturan sederhana dan strategi intuitif. Ukuran papan yang berbeda digunakan untuk memainkan game ini; profesional menggunakan papan 19x19.

Permainan dimulai dengan papan kosong. Setiap pemain kemudian bergiliran menempatkan batu hitam dan putih (hitam duluan) di papan, di persimpangan garis (tidak seperti catur, di mana Anda menempatkan bidak di kotak). Seorang pemain dapat menangkap batu lawan dengan mengelilinginya dari semua sisi. Untuk setiap batu yang ditangkap, beberapa poin diberikan kepada pemain. Tujuan permainan ini adalah untuk menempati wilayah maksimum di papan bersama dengan menangkap batu lawan Anda.
Go adalah tentang penciptaan, tidak seperti Catur, yang tentang kehancuran. Go membutuhkan kebebasan, kreativitas, intuisi, keseimbangan, strategi, dan kedalaman intelektual untuk menguasai permainan. Bermain Go melibatkan kedua sisi otak. Faktanya, pemindaian otak pemain Go telah mengungkapkan bahwa Go membantu perkembangan otak dengan meningkatkan koneksi antara kedua belahan otak.
Neural Networks for Dummies: Panduan Komprehensif
Pergi dan Tantangan Kecerdasan Buatan (AI)
Komputer mampu menguasai Tic-Tac-Toe pada tahun 1952 . Deep Blue mampu mengalahkan grandmaster Catur Garry Kasparov pada tahun 1997 . Program komputer mampu menang melawan juara dunia di Jeopardy (permainan Amerika yang populer) pada tahun 2001 . AlphaGo DeepMind mampu mengalahkan juara dunia Go pada tahun 2016 . Mengapa program komputer dianggap menantang untuk menguasai permainan Go?
Catur dimainkan di papan berukuran 8×8 sedangkan Go menggunakan papan berukuran 19×19. Dalam pembukaan permainan catur, seorang pemain akan memiliki 20 kemungkinan gerakan. Dalam pembukaan Go, seorang pemain dapat memiliki 361 kemungkinan gerakan. Jumlah kemungkinan posisi papan Go sama dengan 10 pangkat 170; lebih dari jumlah atom di alam semesta kita! Potensi jumlah posisi papan membuat waktu googol (10 pangkat 100) lebih kompleks daripada catur.
Dalam catur, untuk setiap langkah, seorang pemain dihadapkan pada pilihan 35 langkah. Rata-rata, pemain Go akan memiliki 250 kemungkinan gerakan di setiap langkah. Dalam Catur, pada posisi apa pun, relatif mudah bagi komputer untuk melakukan pencarian brute force dan memilih langkah terbaik yang memaksimalkan peluang untuk menang. Pencarian brute force tidak dimungkinkan dalam kasus Go, karena jumlah potensi langkah hukum yang diizinkan untuk setiap langkah sangat besar.
Bagi komputer untuk menguasai catur, menjadi lebih mudah saat permainan berlangsung karena potongan-potongannya dikeluarkan dari papan. Di Go, program komputer menjadi lebih sulit karena batu ditambahkan ke papan saat permainan berlangsung. Biasanya, permainan Go akan berlangsung 3 kali lebih lama dari permainan catur.
Karena semua alasan ini, program komputer Go teratas hanya mampu mengejar juara dunia Go pada tahun 2016, setelah ledakan besar teknik pembelajaran mesin baru. Para ilmuwan yang bekerja di DeepMind berhasil membuat program komputer bernama AlphaGo yang mengalahkan juara dunia Lee Seedol . Mencapai tugas itu tidak mudah. Para peneliti di DeepMind menemukan banyak inovasi baru dalam proses pembuatan AlphaGo.
"Aturan Go sangat elegan, organik, dan sangat logis sehingga jika bentuk kehidupan cerdas ada di tempat lain di alam semesta, mereka hampir pasti memainkan Go."
– Edward Laskar
Neural Networks: Aplikasi di Dunia Nyata
Bagaimana AlphaGo Bekerja
AlphaGo adalah algoritma tujuan umum, yang berarti dapat digunakan untuk menyelesaikan tugas-tugas lain juga. Misalnya, Deep Blue dari IBM dirancang khusus untuk bermain catur. Aturan catur bersama dengan akumulasi pengetahuan dari berabad-abad bermain game diprogram ke dalam otak program. Deep Blue tidak bisa digunakan bahkan untuk bermain game sepele seperti Tic-Tac-Toe. Ia hanya dapat melakukan satu hal tertentu, yang sangat ia kuasai, yaitu bermain catur. AlphaGo juga bisa belajar bermain game lain selain Go. Algoritma tujuan umum ini merupakan bidang penelitian baru, yang disebut Artificial General Intelligence.
AlphaGo menggunakan metode canggih – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (teknik baru yang diperkenalkan dan dipopulerkan oleh DeepMind yang menggabungkan saraf jaringan dengan pembelajaran penguatan), untuk beberapa nama. Kemudian menggabungkan semua metode ini secara inovatif untuk mencapai penguasaan tingkat manusia super dalam game Go.
Pertama-tama mari kita lihat masing-masing potongan teka-teki ini sebelum membahas bagaimana potongan-potongan ini diikat bersama untuk mencapai tugas yang ada.
Jaringan Saraf Dalam
DNN adalah teknik untuk melakukan pembelajaran mesin, yang secara longgar terinspirasi oleh fungsi otak manusia. Arsitektur DNN terdiri dari lapisan neuron. DNN dapat mengenali pola dalam data tanpa secara eksplisit diprogram untuk itu.
Ini memetakan input ke output tanpa ada yang secara khusus memprogramnya untuk hal yang sama. Sebagai contoh, mari kita asumsikan bahwa kita telah memberi makan jaringan dengan banyak foto kucing dan anjing. Pada saat yang sama, kami juga melatih sistem dengan memberi tahu (dalam bentuk label) jika gambar tertentu adalah kucing atau anjing (ini disebut pembelajaran terawasi). DNN akan belajar mengenali pola dari foto agar berhasil membedakan antara kucing dan anjing. Tujuan utama pelatihan ini adalah ketika DNN melihat gambar baru anjing atau kucing, ia harus dapat mengklasifikasikannya dengan benar, yaitu memprediksi apakah itu kucing atau anjing.
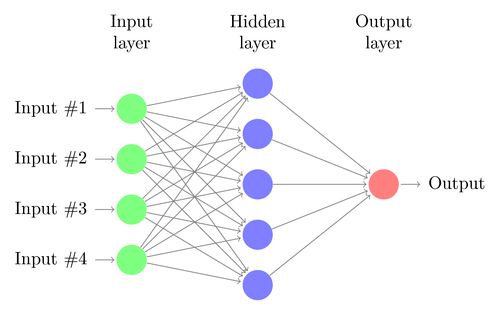
Mari kita memahami arsitektur DNN sederhana. Jumlah neuron di lapisan input sesuai dengan ukuran input. Mari kita asumsikan foto kucing dan anjing kita adalah gambar 28x28. Setiap baris dan kolom akan terdiri dari masing-masing 28 piksel, yang menjadikannya total 784 piksel untuk setiap gambar. Dalam kasus seperti itu lapisan input akan terdiri dari 784 neuron, satu untuk setiap piksel. Jumlah neuron di lapisan output akan tergantung pada jumlah kelas di mana output perlu diklasifikasikan. Dalam hal ini, lapisan keluaran akan terdiri dari dua neuron – satu sesuai dengan 'kucing', yang lain untuk 'anjing'.
Perhatikan Hal Besar Berikutnya: Pembelajaran Mesin
Akan ada banyak lapisan neuron di antara lapisan input dan output (yang merupakan asal mula penggunaan istilah 'Deep' dalam 'Deep Neural Network'). Ini disebut "lapisan tersembunyi". Jumlah lapisan tersembunyi dan jumlah neuron di setiap lapisan tidak tetap. Faktanya, mengubah nilai-nilai ini adalah apa yang mengarah pada optimalisasi kinerja. Nilai-nilai ini disebut hyper-parameter, dan mereka perlu disetel sesuai dengan masalah yang dihadapi. Eksperimen seputar jaringan saraf sebagian besar melibatkan pencarian jumlah hiperparameter yang optimal.
Fase pelatihan DNN akan terdiri dari umpan maju dan umpan mundur. Pertama, semua koneksi antar neuron diinisialisasi dengan bobot acak. Selama forward pass, jaringan diumpankan dengan satu gambar. Input (data piksel dari gambar) digabungkan dengan parameter jaringan (bobot, bias, dan fungsi aktivasi) dan diteruskan melalui lapisan tersembunyi, hingga ke output, yang mengembalikan probabilitas foto milik masing-masing dari kelas-kelas.
Kemudian, probabilitas ini dibandingkan dengan label kelas yang sebenarnya, dan "kesalahan" dihitung. Pada titik ini, umpan balik dilakukan – informasi kesalahan ini diteruskan kembali melalui jaringan melalui teknik yang disebut “propagasi balik”. Selama fase awal pelatihan, kesalahan ini akan tinggi, dan mekanisme pelatihan yang baik secara bertahap akan mengurangi kesalahan ini.
DNN dilatih dengan cara ini dengan umpan maju dan mundur sampai bobot berhenti berubah (ini dikenal sebagai konvergensi). Kemudian DNN akan dapat memprediksi dan mengklasifikasikan gambar dengan tingkat akurasi yang tinggi, yaitu apakah gambar tersebut memiliki kucing atau anjing.

Penelitian telah memberi kita banyak Arsitektur Jaringan Saraf Dalam yang berbeda. Untuk masalah Computer Vision (yaitu masalah yang melibatkan gambar), Convolution Neural Networks (CNNs) secara tradisional memberikan hasil yang baik. Untuk masalah yang melibatkan urutan – pengenalan suara atau terjemahan bahasa – Recurrent Neural Networks (RNN) memberikan hasil yang sangat baik.
Panduan Pemula Untuk Pemahaman Bahasa Alami
Dalam kasus AlphaGo, prosesnya adalah sebagai berikut: pertama, Convolution Neural Network (CNN) dilatih pada jutaan gambar posisi papan. Selanjutnya, jaringan diberitahu tentang langkah selanjutnya yang dimainkan oleh para ahli manusia dalam setiap kasus selama fase pelatihan jaringan. Dengan cara yang sama seperti yang disebutkan sebelumnya, nilai aktual dibandingkan dengan output dan semacam metrik "kesalahan" ditemukan.
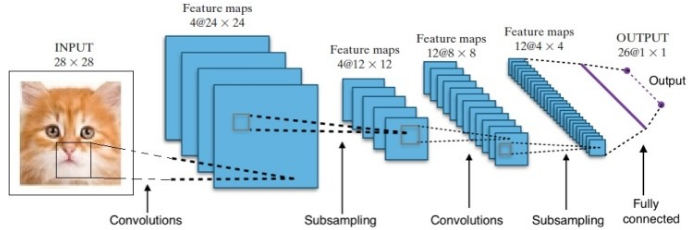
Di akhir pelatihan, DNN akan menampilkan gerakan selanjutnya beserta probabilitas yang kemungkinan akan dimainkan oleh pemain manusia yang ahli. Jaringan semacam ini hanya bisa muncul dengan langkah yang dimainkan oleh pemain ahli manusia. DeepMind mampu mencapai akurasi 60% dalam memprediksi langkah yang akan dilakukan manusia. Namun, untuk mengalahkan seorang ahli manusia di Go, ini tidak cukup. Output dari DNN diproses lebih lanjut oleh Deep Reinforcement Network, sebuah pendekatan yang disusun oleh DeepMind, yang menggabungkan jaringan saraf dalam dan pembelajaran penguatan.
Pembelajaran Penguatan Mendalam
Reinforcement learning (RL) bukanlah konsep baru. Pemenang hadiah Nobel Ivan Pavlov bereksperimen pada pengkondisian klasik pada anjing dan menemukan prinsip-prinsip pembelajaran penguatan pada tahun 1902. RL juga merupakan salah satu metode yang digunakan manusia untuk mempelajari keterampilan baru. Pernah bertanya-tanya bagaimana Lumba-lumba dalam pertunjukan dilatih untuk melompat ke ketinggian yang begitu tinggi dari air? Hal ini dengan bantuan RL. Pertama, tali yang digunakan untuk mempersiapkan lumba-lumba ditenggelamkan di kolam. Setiap kali lumba-lumba melintasi kabel dari atas, ia diberi hadiah makanan. Ketika tidak melewati tali, hadiah ditarik. Pelan-pelan lumba-lumba akan belajar bahwa ia dibayar setiap kali ia melewati kabelnya dari atas. Ketinggian tali dinaikkan secara bertahap untuk melatih lumba-lumba. 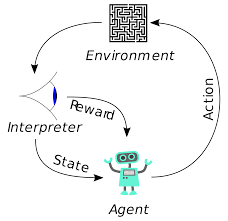
Generasi Bahasa Alami: Hal Teratas yang Perlu Anda Ketahui
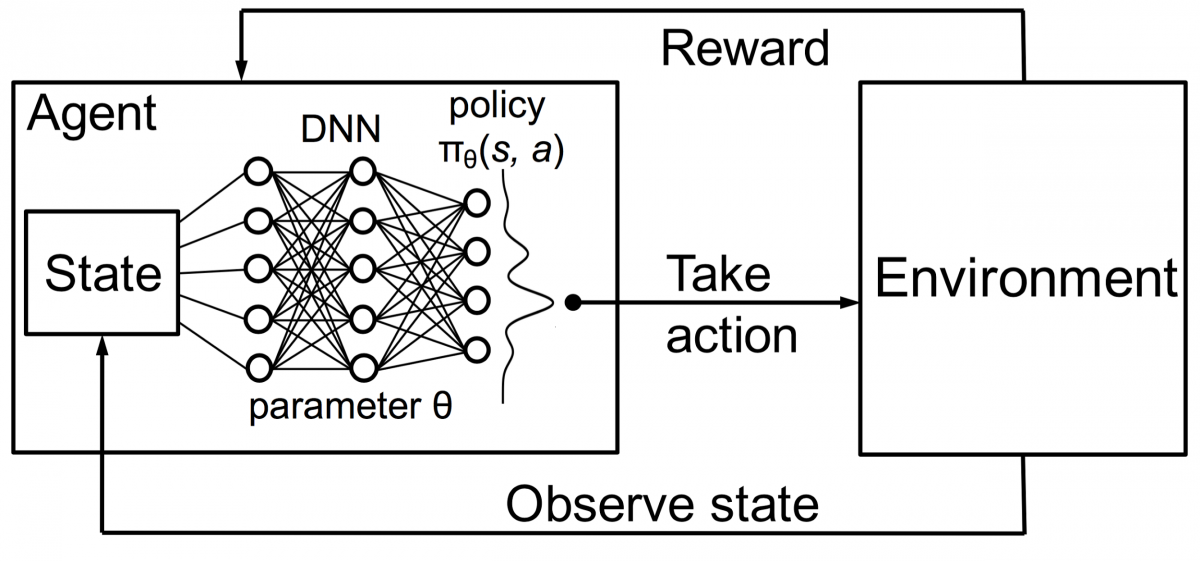
Agen dalam pembelajaran penguatan juga dilatih menggunakan prinsip yang sama. Agen akan mengambil tindakan dan berinteraksi dengan lingkungan. Tindakan yang diambil oleh agen menyebabkan lingkungan berubah. Selanjutnya, agen menerima umpan balik tentang lingkungan. Agen itu dihargai atau tidak, tergantung pada tindakannya dan tujuan yang ada. Poin pentingnya adalah, tujuan yang ada tidak secara eksplisit dinyatakan untuk agen. Dengan waktu yang cukup, agen akan belajar bagaimana memaksimalkan imbalan di masa depan.

Menggabungkan ini dengan DNN, DeepMind menemukan Deep Reinforcement Learning (DRL) atau Deep Q Networks (DQN) di mana Q adalah singkatan dari imbalan masa depan maksimum yang diperoleh. DQN pertama kali diterapkan pada game Atari . DQN belajar cara memainkan berbagai jenis game Atari secara langsung. Terobosannya adalah bahwa tidak ada pemrograman eksplisit yang diperlukan untuk mewakili berbagai jenis game Atari. Satu program cukup pintar untuk mempelajari semua lingkungan permainan yang berbeda, dan melalui permainan sendiri, mampu menguasai banyak dari mereka.
Pada tahun 2014, DQN mengungguli metode pembelajaran mesin sebelumnya di 43 dari 49 game (sekarang telah diuji di lebih dari 70 game). Faktanya, di lebih dari setengah permainan, ia tampil di lebih dari 75% level pemain manusia profesional. Dalam permainan tertentu, DQN bahkan datang dengan strategi jauh ke depan yang memungkinkannya mencapai skor maksimum yang dapat dicapai—misalnya, di Breakout , ia belajar menggali terowongan di salah satu ujung dinding bata terlebih dahulu, sehingga bola akan memantul. di belakang dan melumpuhkan batu bata dari belakang.
Jaringan Kebijakan dan Nilai
Ada dua jenis jaringan utama di dalam AlphaGo:
Salah satu tujuan DQN AlphaGo adalah melampaui permainan ahli manusia dan meniru gerakan inovatif baru, dengan bermain melawan dirinya sendiri jutaan kali dan dengan demikian meningkatkan bobot secara bertahap. DQN ini memiliki tingkat kemenangan 80% terhadap DNN umum. DeepMind memutuskan untuk menggabungkan dua jaringan saraf ini (DNN dan DQN) untuk membentuk jenis jaringan pertama – 'Jaringan Kebijakan'. Secara singkat, tugas jaringan kebijakan adalah mengurangi luasnya pencarian langkah selanjutnya dan menghasilkan beberapa langkah bagus yang layak untuk dieksplorasi lebih lanjut.
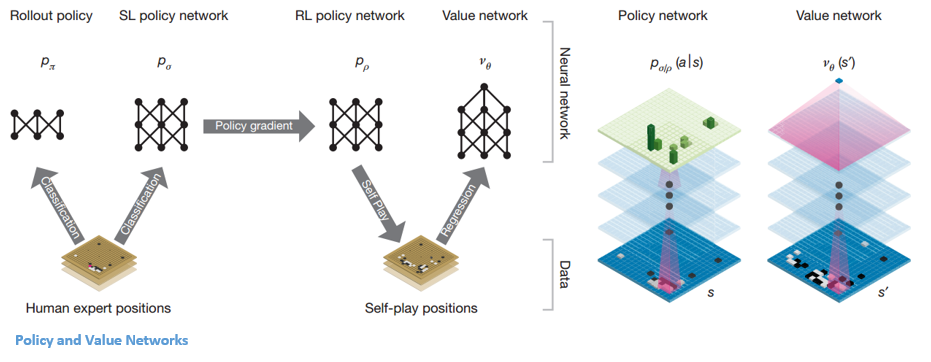 Setelah jaringan kebijakan dibekukan, ia bermain melawan dirinya sendiri jutaan kali. Game-game ini menghasilkan kumpulan data Go baru, yang terdiri dari berbagai posisi papan dan hasil game. Dataset ini digunakan untuk membuat fungsi evaluasi. Jenis fungsi kedua – 'Value Network' digunakan untuk memprediksi hasil permainan. Ia belajar untuk mengambil berbagai posisi papan sebagai input dan memprediksi hasil permainan dan ukurannya.
Setelah jaringan kebijakan dibekukan, ia bermain melawan dirinya sendiri jutaan kali. Game-game ini menghasilkan kumpulan data Go baru, yang terdiri dari berbagai posisi papan dan hasil game. Dataset ini digunakan untuk membuat fungsi evaluasi. Jenis fungsi kedua – 'Value Network' digunakan untuk memprediksi hasil permainan. Ia belajar untuk mengambil berbagai posisi papan sebagai input dan memprediksi hasil permainan dan ukurannya.
Menggabungkan Jaringan Kebijakan dan Nilai
Setelah semua pelatihan ini, DeepMind akhirnya mendapatkan dua jaringan saraf – Jaringan Kebijakan dan Jaringan Nilai. Jaringan kebijakan mengambil posisi dewan sebagai input dan output distribusi probabilitas sebagai kemungkinan setiap pergerakan di posisi itu. Jaringan nilai kembali mengambil posisi papan sebagai input dan output bilangan real tunggal antara 0 dan 1. Jika output dari jaringan adalah nol, itu berarti putih benar-benar menang dan 1 menunjukkan kemenangan lengkap untuk pemain dengan hitam batu.
Jaringan Kebijakan mengevaluasi posisi saat ini, dan jaringan nilai mengevaluasi pergerakan di masa mendatang. Pembagian tugas ke dalam dua jaringan ini oleh DeepMind adalah salah satu alasan utama di balik kesuksesan AlphaGo.
Menggabungkan jaringan Kebijakan dan Nilai dengan Monte Carlo Tree Search (MCTS) dan Peluncuran
Jaringan saraf sendiri tidak akan cukup. Untuk memenangkan permainan Go, diperlukan beberapa strategi lagi. Rencana ini dicapai dengan bantuan MCTS. Pencarian Pohon Monte Carlo juga membantu menyatukan dua jaringan saraf dengan cara yang inovatif. Jaringan saraf membantu dalam pencarian yang efisien untuk langkah terbaik berikutnya.
Mari kita coba membuat contoh yang akan membantu Anda memvisualisasikan semua ini dengan lebih baik. Bayangkan bahwa permainan berada di posisi baru, yang belum pernah ditemui sebelumnya. Dalam situasi seperti itu, jaringan kebijakan dipanggil untuk mengevaluasi situasi saat ini dan kemungkinan jalan di masa depan; serta keinginan jalur dan nilai setiap gerakan oleh jaringan Nilai, yang didukung oleh peluncuran Monte Carlo.
Jaringan kebijakan menemukan semua kemungkinan gerakan “baik” dan jaringan nilai mengevaluasi setiap hasil mereka. Dalam peluncuran Monte Carlo, beberapa ribu permainan acak dimainkan dari posisi yang diakui oleh jaringan kebijakan. Eksperimen dilakukan untuk menentukan kepentingan relatif jaringan nilai terhadap peluncuran Monte Carlo. Sebagai hasil dari eksperimen ini, DeepMind menetapkan bobot 80% ke jaringan Nilai dan bobot 20% ke fungsi evaluasi peluncuran Monte Carlo.
Jaringan kebijakan mengurangi lebar pencarian dari 200 kemungkinan gerakan menjadi 4 atau 5 gerakan terbaik. Jaringan kebijakan memperluas pohon dari 4 atau 5 langkah ini yang perlu dipertimbangkan. Jaringan nilai membantu mengurangi kedalaman pencarian pohon dengan segera mengembalikan hasil permainan dari posisi itu. Akhirnya dipilih langkah dengan nilai Q tertinggi, yaitu langkah dengan manfaat maksimal.
“ Permainan ini dimainkan terutama melalui intuisi dan perasaan, dan karena keindahan, kehalusan, dan kedalaman intelektualnya, ia telah menangkap imajinasi manusia selama berabad-abad.”
– Demis Hassabis
Penerapan AlphaGo untuk masalah dunia nyata
Visi DeepMind, dari situs web mereka, sangat jitu – “Memecahkan kecerdasan. Gunakan pengetahuan ini untuk membuat dunia menjadi tempat yang lebih baik”. Tujuan akhir dari algoritma ini adalah untuk menjadikannya tujuan umum sehingga dapat digunakan untuk memecahkan masalah dunia nyata yang kompleks. AlphaGo DeepMind adalah langkah maju yang signifikan dalam pencarian AGI. DeepMind telah berhasil menggunakan teknologinya untuk memecahkan masalah dunia nyata – mari kita lihat beberapa contoh:
Pengurangan konsumsi energi
AI DeepMind berhasil digunakan untuk mengurangi biaya pendinginan pusat data Google hingga 40%. Dalam lingkungan konsumsi energi skala besar mana pun, peningkatan ini merupakan langkah maju yang fenomenal. Salah satu sumber utama konsumsi energi untuk pusat data adalah pendinginan. Banyak panas yang dihasilkan dari menjalankan server perlu dihilangkan agar tetap beroperasi. Hal ini dicapai dengan peralatan industri skala besar seperti pompa, pendingin dan menara pendingin. Karena lingkungan pusat data sangat dinamis, maka sulit untuk beroperasi pada efisiensi energi yang optimal. AI DeepMind digunakan untuk mengatasi masalah ini.
Pertama, mereka melanjutkan menggunakan data historis, yang dikumpulkan oleh ribuan sensor di dalam pusat data. Dengan menggunakan data ini, mereka melatih ansambel DNN tentang rata-rata Efektivitas Penggunaan Daya (PUE) di masa mendatang. Karena ini adalah algoritme tujuan umum, direncanakan bahwa itu akan diterapkan pada tantangan lain juga, di lingkungan pusat data.
Kemungkinan penerapan teknologi ini termasuk mendapatkan lebih banyak energi dari unit input yang sama, mengurangi energi manufaktur semikonduktor dan penggunaan air, dll. DeepMind mengumumkan dalam posting blognya bahwa pengetahuan ini akan dibagikan dalam publikasi masa depan sehingga pusat data lainnya, industri operator dan pada akhirnya lingkungan dapat sangat diuntungkan dari langkah signifikan ini.
Perencanaan radioterapi untuk kanker kepala dan leher
DeepMind telah bekerja sama dengan departemen radioterapi di NHS Foundation Trust dari University College London Hospital, pemimpin dunia dalam pengobatan kanker.
Bagaimana Big Data dan Pembelajaran Mesin Bersatu Melawan Kanker
Satu dari 75 pria dan satu dari 150 wanita didiagnosis menderita kanker mulut dalam hidup mereka. Karena sifat sensitif dari struktur dan organ di daerah kepala dan leher, ahli radiologi perlu sangat berhati-hati saat merawatnya.
Sebelum radioterapi diberikan, peta rinci perlu disiapkan dengan area yang akan dirawat dan area yang harus dihindari. Ini dikenal sebagai segmentasi. Peta tersegmentasi ini dimasukkan ke dalam mesin radiografi, yang kemudian akan menargetkan sel kanker tanpa merusak sel sehat.
Dalam kasus kanker di daerah kepala atau leher, ini adalah pekerjaan yang melelahkan bagi ahli radiologi karena melibatkan organ yang sangat sensitif. Dibutuhkan sekitar empat jam bagi ahli radiologi untuk membuat peta tersegmentasi untuk area ini. DeepMind, melalui algoritmenya, bertujuan untuk mengurangi waktu yang diperlukan untuk menghasilkan peta yang tersegmentasi, dari empat menjadi satu jam. Ini akan secara signifikan membebaskan waktu ahli radiologi. Lebih penting lagi, algoritma segmentasi ini dapat digunakan untuk bagian tubuh lainnya.
Ringkasnya, AlphaGo berhasil mengalahkan juara dunia Go 18 kali, Lee Seedol, empat kali dalam turnamen best-of-five pada 2016. Pada 2017, bahkan mengalahkan tim pemain terbaik dunia. Ini menggunakan kombinasi DNN dan DQN sebagai jaringan kebijakan untuk menghasilkan langkah terbaik berikutnya, dan satu DNN sebagai jaringan nilai untuk mengevaluasi hasil permainan. Pencarian pohon Monte Carlo digunakan bersama dengan jaringan kebijakan dan nilai untuk mengurangi lebar dan kedalaman pencarian – keduanya digunakan untuk meningkatkan fungsi evaluasi. Tujuan akhir dari algoritme ini bukanlah untuk memecahkan permainan papan tetapi untuk menciptakan algoritme Kecerdasan Umum Buatan. AlphaGo tidak diragukan lagi merupakan langkah besar ke depan ke arah itu.
Perbedaan antara Ilmu Data, Pembelajaran Mesin, dan Data Besar!
Tentu saja, ada efek lain. Saat berita tentang AlphaGo Vs Lee Seedol menjadi viral, permintaan untuk papan Go melonjak sepuluh kali lipat. Banyak toko melaporkan contoh papan Go kehabisan stok, dan menjadi sulit untuk membeli papan Go.
Untungnya, saya baru saja menemukan satu dan memesannya untuk saya dan anak saya. Apakah Anda berencana untuk membeli papan dan belajar Go?
Pelajari kursus ML dari Universitas top dunia. Dapatkan Master, PGP Eksekutif, atau Program Sertifikat Tingkat Lanjut untuk mempercepat karier Anda.
Apa keterbatasan pembelajaran penguatan dalam?
DL melupakan pengetahuan yang diperoleh sebelumnya ketika data atau informasi baru diperkenalkan, sehingga tidak menantangnya. Terlalu banyak penguatan terkadang dapat mengakibatkan kelebihan status, menurunkan efektivitas. Karena kompleksitas model data, pelatihan sangat mahal. Pembelajaran mendalam juga memerlukan penggunaan GPU yang mahal dan ratusan workstation. Akibatnya, menjadi kurang ekonomis untuk digunakan.
Apa kerugian menggunakan Pencarian Pohon Monte Carlo?
Meskipun MCTS adalah algoritme sederhana untuk dieksekusi, ia memiliki kelemahan tertentu. Ketika pohon tumbuh lebih besar setelah beberapa iterasi, banyak memori yang dibutuhkan. Saat diterapkan pada permainan berbasis giliran, mungkin ada satu cabang atau jalur yang menyebabkan kekalahan melawan lawan dalam kondisi tertentu. Akibatnya, itu sedikit kurang bisa diandalkan. Setelah banyak iterasi, Pencarian Pohon Monte Carlo membutuhkan waktu lama untuk menentukan jalur yang paling efektif.
Apa perbedaan AlphaZero dengan AlphaGo Zero?
Versi sebelumnya dari AlphaGo memasukkan sejumlah kecil fitur buatan tangan, tetapi AlphaGo Zero hanya menggunakan batu hitam dan putih dari papan Go sebagai masukan. Versi sebelumnya dari AlphaGo mengandalkan jaringan kebijakan untuk memilih langkah selanjutnya dan jaringan nilai untuk memperkirakan pemenang permainan dari setiap posisi. Ini digabungkan ke dalam AlphaGo Zero, memungkinkan pelatihan dan evaluasi yang lebih efisien. Semua perbedaan ini berkontribusi pada peningkatan kinerja dan generalisasi sistem. Penyesuaian algoritmik, di sisi lain, membuat sistem jauh lebih kuat dan efisien.