
Git ve Yapay Genel Zekaya Meydan Okuma
Yayınlanan: 2018-02-15Bu makale, 'Go' oyunu ile yapay zeka arasındaki bağlantıyı keşfetmeyi amaçlamaktadır. Amaç şu soruları cevaplamaktır: Go oyununu özel yapan nedir? Go oyununda ustalaşmak bir bilgisayar için neden zordu? Neden bir bilgisayar programı 1997'de bir satranç büyükustasını yenebildi? Go'yu kırmak neden yirmi yıla yakın sürdü?
"Beyler önemsiz oyunlarla zaman kaybetmemeli - Go çalışmalılar"
– Konfüçyüs
Aslında yapay zeka uzmanları, bilgisayarların yalnızca 2027 yılına kadar bir dünya Go şampiyonunu yenebileceğini düşündüler. Google çatısı altındaki bir yapay zeka şirketi olan DeepMind sayesinde, bu zorlu görev on yıl önce başarıldı. Bu makale DeepMind tarafından dünya Go şampiyonunu yenmek için kullanılan teknolojiler hakkında konuşacak. Son olarak, bu yazı, bu teknolojinin bazı karmaşık, gerçek dünya sorunlarını çözmek için nasıl kullanılabileceğini tartışıyor.
İçindekiler
Git - bu nedir?
Go, popülerliğini çağlar boyunca koruyan 3000 yıllık bir Çin strateji masa oyunudur. Dünya çapında on milyonlarca insan tarafından oynanan Go, basit kuralları ve sezgisel stratejisi olan iki oyunculu bir masa oyunudur. Bu oyunu oynamak için farklı tahta boyutları kullanılıyor; profesyoneller 19×19 tahta kullanır.

Oyun boş bir tahta ile başlar. Daha sonra her oyuncu sırayla siyah ve beyaz taşları (siyah önce gelir) çizgilerin kesiştiği yere (satrançtan farklı olarak, parçaları karelere yerleştirdiğiniz) tahtaya yerleştirir. Bir oyuncu, rakibin taşlarını her yönden kuşatarak ele geçirebilir. Yakalanan her taş için oyuncuya bazı puanlar verilir. Oyunun amacı, rakiplerinizin taşlarını ele geçirmekle birlikte tahtada maksimum alanı işgal etmektir.
Go, yıkımla ilgili olan Satrançtan farklı olarak yaratma ile ilgilidir. Go, oyunda ustalaşmak için özgürlük, yaratıcılık, sezgi, denge, strateji ve entelektüel derinlik gerektirir. Go oynamak beynin her iki tarafını da içerir. Aslında, Go oyuncularının beyin taramaları, Go'nun her iki beyin yarıküresi arasındaki bağlantıları geliştirerek beyin gelişimine yardımcı olduğunu ortaya çıkardı.
Aptallar için Sinir Ağları: Kapsamlı Bir Kılavuz
Git ve Yapay Zekanın (AI) Mücadelesi
Bilgisayarlar 1952'de Tic-Tac-Toe'da ustalaşmayı başardılar . Deep Blue, 1997'de Satranç ustası Garry Kasparov'u yenmeyi başardı . Bilgisayar programı, 2001 yılında Jeopardy'de (popüler bir Amerikan oyunu) dünya şampiyonuna karşı kazanmayı başardı . DeepMind'ın AlphaGo'su 2016'da bir dünya Go şampiyonunu yenmeyi başardı . Bir bilgisayar programının Go oyununda ustalaşması neden zor kabul edilir?
Satranç 8×8 tahtada oynanırken Go 19×19 boyutunda bir tahta kullanır. Bir satranç oyununun açılışında, bir oyuncunun olası 20 hamlesi olacaktır. Bir Go açılışında, bir oyuncu 361 olası hamleye sahip olabilir. Olası Go tahtası pozisyonlarının sayısı 10 üzeri 170'e eşittir; evrenimizdeki atom sayısından daha fazla! Tahta pozisyonlarının potansiyel sayısı Googol zamanlarını (10 üzeri 100) satrançtan daha karmaşık hale getirir.
Satrançta, her adım için bir oyuncu 35 hamle seçeneği ile karşı karşıyadır. Ortalama olarak, bir Go oyuncusunun her adımda 250 olası hareketi olacaktır. Satrançta, herhangi bir pozisyonda, bir bilgisayarın kaba kuvvet araması yapması ve kazanma şansını en üst düzeye çıkaran mümkün olan en iyi hamleyi seçmesi nispeten kolaydır. Her adım için izin verilen olası yasal hamle sayısı çok büyük olduğundan, Go durumunda kaba kuvvet araması mümkün değildir.
Bir bilgisayarın satrançta ustalaşması, taşlar tahtadan kaldırıldığı için oyun ilerledikçe daha kolay hale gelir. Go'da oyun ilerledikçe tahtaya taşlar eklendiğinden bilgisayar programı için daha zor hale geliyor. Tipik olarak, bir Go oyunu bir satranç oyunundan 3 kat daha uzun sürer.
Tüm bu nedenlerden dolayı, en iyi bilgisayar Go programı, yeni makine öğrenimi tekniklerinde büyük bir patlamanın ardından 2016 yılında Go dünya şampiyonunu yakalayabildi. DeepMind'de çalışan bilim adamları , dünya şampiyonu Lee Seedol'u mağlup eden AlphaGo adlı bir bilgisayar programı ortaya çıkarmayı başardılar . Görevi başarmak kolay değildi. DeepMind'deki araştırmacılar, AlphaGo'yu yaratma sürecinde birçok yeni yenilik buldular.
"Go'nun kuralları o kadar zarif, organik ve kesinlikle mantıklı ki, eğer evrenin başka yerlerinde akıllı yaşam formları varsa, neredeyse kesinlikle Go oynuyorlar."
-Edward Laskar
Sinir Ağları: Gerçek Dünyadaki Uygulamalar
AlphaGo Nasıl Çalışır?
AlphaGo genel amaçlı bir algoritmadır, yani diğer görevleri çözmek için de kullanılabilir. Örneğin, IBM'den Deep Blue özellikle satranç oynamak için tasarlanmıştır. Satranç kuralları, oyun oynamanın yüzyıllar boyunca biriktirdiği bilgilerle birlikte programın beynine programlanmıştır. Deep Blue, Tic-Tac-Toe gibi önemsiz oyunları oynamak için bile kullanılamaz. Çok iyi olduğu tek bir şey yapabilir, yani satranç oynamak. AlphaGo, Go dışında başka oyunları da oynamayı öğrenebilir. Bu genel amaçlı algoritmalar, Yapay Genel Zeka adı verilen yeni bir araştırma alanı oluşturmaktadır.
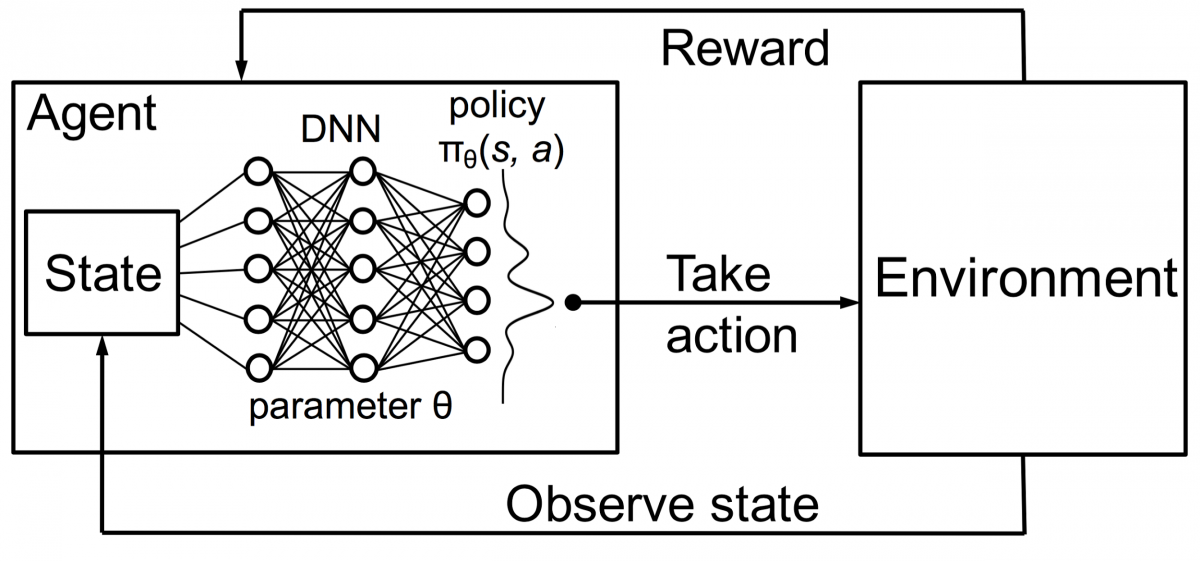
AlphaGo son teknoloji yöntemleri kullanır – Derin Sinir Ağları (DNN), Güçlendirme Öğrenimi (RL), Monte Carlo Ağaç Araması (MCTS), Derin Q Ağları (DQN) (DeepMind tarafından tanıtılan ve popüler hale getirilen ve sinirsel ağları birleştiren yeni bir tekniktir. pekiştirmeli öğrenme ile ağlar), birkaç isim. Daha sonra Go oyununda insanüstü düzeyde ustalık elde etmek için tüm bu yöntemleri yenilikçi bir şekilde birleştirir.
Eldeki görevi başarmak için bu parçaların nasıl birbirine bağlandığına geçmeden önce, bu yapbozun her bir parçasına bir göz atalım.
Derin Sinir Ağları
DNN'ler, insan beyninin işleyişinden gevşek bir şekilde esinlenerek makine öğrenimi gerçekleştirmek için bir tekniktir. Bir DNN'nin mimarisi nöron katmanlarından oluşur. DNN, bunun için açıkça programlanmadan verilerdeki kalıpları tanıyabilir.
Girdileri çıktılara eşler, aynısı için özel olarak programlamadan. Örnek olarak, ağı çok sayıda kedi ve köpek fotoğrafı ile beslediğimizi varsayalım. Aynı zamanda, belirli bir görüntünün bir kediye mi yoksa bir köpeğe mi ait olduğunu söyleyerek (etiketler şeklinde) sistemi eğitiyoruz (buna denetimli öğrenme denir). Bir DNN, bir kedi ve bir köpek arasında başarılı bir şekilde ayrım yapmak için fotoğraflardan deseni tanımayı öğrenecektir. Eğitimin temel amacı, bir DNN'nin bir köpeğin veya bir kedinin yeni bir resmini gördüğünde, onu doğru bir şekilde sınıflandırabilmesi, yani onun bir kedi mi yoksa bir köpek mi olduğunu tahmin edebilmesidir.
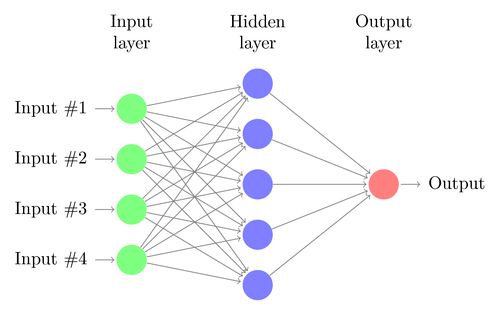
Basit bir DNN'nin mimarisini anlayalım. Giriş katmanındaki nöron sayısı, girişin boyutuna karşılık gelir. Kedi ve köpek fotoğraflarımızın 28×28 bir resim olduğunu varsayalım. Her satır ve sütun, her biri 28 pikselden oluşacak ve bu da her resim için toplam 784 piksel olacak. Böyle bir durumda giriş katmanı, her piksel için bir tane olmak üzere 784 nörondan oluşacaktır. Çıktı katmanındaki nöronların sayısı, çıktının sınıflandırılması gereken sınıfların sayısına bağlı olacaktır. Bu durumda, çıktı katmanı, biri 'kedi'ye, diğeri 'köpek'e karşılık gelen iki nörondan oluşacaktır.
Bir Sonraki Büyük Şeye Dikkat Edin: Makine Öğrenimi
Giriş ve çıkış katmanları arasında ('Derin Sinir Ağı'nda 'Derin' teriminin kullanılmasının kökeni olan) birçok nöron katmanı olacaktır. Bunlara “gizli katmanlar” denir. Gizli katman sayısı ve her katmandaki nöron sayısı sabit değildir. Aslında, bu değerleri değiştirmek tam olarak performansın optimizasyonuna yol açan şeydir. Bu değerlere hiper parametreler denir ve eldeki probleme göre ayarlanmaları gerekir. Sinir ağlarını çevreleyen deneyler, büyük ölçüde optimal hiperparametre sayısını bulmayı içerir.
DNN'lerin eğitim aşaması, bir ileri geçiş ve bir geri geçişten oluşacaktır. İlk olarak, nöronlar arasındaki tüm bağlantılar rastgele ağırlıklarla başlatılır. İleri geçiş sırasında ağ tek bir görüntü ile beslenir. Girdiler (görüntüden alınan piksel verileri) ağın parametreleriyle (ağırlıklar, önyargılar ve etkinleştirme işlevleri) birleştirilir ve gizli katmanlar aracılığıyla, her birine ait bir fotoğraf olasılığını döndüren çıkışa kadar tüm yol boyunca iletilir. sınıflardan.
Daha sonra bu olasılık gerçek sınıf etiketi ile karşılaştırılır ve bir “hata” hesaplanır. Bu noktada geriye doğru geçiş yapılır – bu hata bilgisi “geri yayılım” adı verilen bir teknikle ağ üzerinden geri iletilir. Eğitimin ilk aşamalarında bu hata yüksek olacak ve iyi bir eğitim mekanizması bu hatayı kademeli olarak azaltacaktır.
DNN'ler, ağırlıkların değişmesi durana kadar ileri ve geri geçişle bu şekilde eğitilir (bu, yakınsama olarak bilinir). Daha sonra DNN'ler görüntüleri yüksek bir doğruluk derecesi ile tahmin edebilecek ve sınıflandırabilecektir, yani resmin bir kedisi mi yoksa bir köpeği mi olduğu gibi.

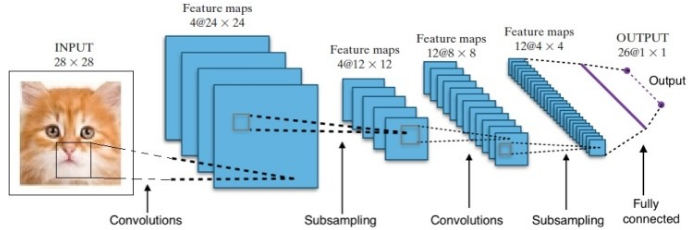
Araştırma bize birçok farklı Derin Sinir Ağı Mimarisi verdi. Bilgisayarla Görme sorunları için (yani görüntüleri içeren sorunlar), Evrişim Sinir Ağları (CNN'ler) geleneksel olarak iyi sonuçlar vermiştir. Bir dizi içeren sorunlar için - konuşma tanıma veya dil çevirisi - Tekrarlayan Sinir Ağları (RNN) mükemmel sonuçlar sağlar.
Doğal Dil Anlayışına Yeni Başlayanlar Kılavuzu
AlphaGo durumunda, süreç şu şekildeydi: ilk olarak, Evrişim Sinir Ağı (CNN) milyonlarca pano pozisyonu görüntüsü üzerinde eğitildi. Daha sonra, ağın eğitim aşaması sırasında her durumda insan uzmanların oynadığı sonraki hamle hakkında ağ bilgilendirildi. Daha önce bahsedildiği gibi, gerçek değer çıktı ile karşılaştırıldı ve bir çeşit "hata" ölçüsü bulundu.
Eğitimin sonunda, DNN, uzman bir insan oyuncu tarafından oynanması muhtemel olasılıklarla birlikte sonraki hamleleri çıkaracaktır. Bu tür bir ağ, ancak uzman bir insan oyuncunun oynadığı bir adımla ortaya çıkabilir. DeepMind, insanın yapacağı hareketi tahmin etmede %60'lık bir doğruluk elde etmeyi başardı. Ancak, Go'da bir insan uzmanı yenmek için bu yeterli değildir. DNN'den elde edilen çıktı, DeepMind tarafından tasarlanan ve derin sinir ağları ile pekiştirmeli öğrenmeyi birleştiren bir yaklaşım olan Deep Reinforcement Network tarafından daha fazla işlenir.
Derin Takviyeli Öğrenme
Pekiştirmeli öğrenme (RL) yeni bir kavram değildir. Nobel ödüllü Ivan Pavlov, köpekler üzerinde klasik koşullanma üzerinde deney yaptı ve 1902'de pekiştirmeli öğrenmenin ilkelerini keşfetti. RL aynı zamanda insanların yeni beceriler öğrendiği yöntemlerden biridir. Yunusların gösterilerdeki sudan bu kadar büyük yüksekliklere atlamak için nasıl eğitildiğini hiç merak ettiniz mi? RL yardımı ile yapılır. İlk olarak yunusları hazırlamak için kullanılan ip havuza daldırılır. Yunus, kabloyu yukarıdan geçtiğinde, yiyecekle ödüllendirilir. İpi geçmediği zaman ödül geri alınır. Yavaş yavaş yunus, ipi yukarıdan her geçtiğinde ödendiğini öğrenecektir. Yunusu eğitmek için ipin yüksekliği kademeli olarak artırılır. 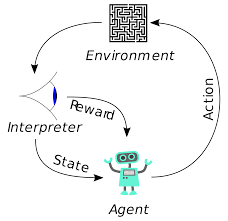
Doğal Dil Üretimi: Bilmeniz Gereken En Önemli Şeyler
Takviyeli öğrenmedeki ajanlar da aynı prensip kullanılarak eğitilir. Ajan harekete geçecek ve çevre ile etkileşime girecektir. Etmen tarafından yapılan eylem ortamın değişmesine neden olur. Ayrıca, temsilci çevre hakkında geri bildirim aldı. Ajan, eylemine ve eldeki amaca bağlı olarak ödüllendirilir veya ödüllendirilmez. Önemli olan nokta, eldeki bu hedefin vekil için açıkça belirtilmemesidir. Yeterli zaman verildiğinde, temsilci gelecekteki ödülleri nasıl en üst düzeye çıkaracağını öğrenecektir.

Bunu DNN'lerle birleştiren DeepMind, Derin Güçlendirme Öğrenimi (DRL) veya Q'nun elde edilen maksimum gelecekteki ödülleri temsil ettiği Derin Q Ağlarını (DQN) icat etti. DQN'ler ilk olarak Atari oyunlarına uygulandı. DQN, kutudan çıktığı anda farklı Atari oyunlarının nasıl oynanacağını öğrendi. Buluş, farklı Atari oyunlarını temsil etmek için açık bir programlamanın gerekmemesiydi. Tek bir program, oyunun tüm farklı ortamlarını öğrenecek kadar akıllıydı ve kendi kendine oynama yoluyla birçoğunda ustalaşmayı başardı.
2014'te DQN, 49 oyunun 43'ünde önceki makine öğrenimi yöntemlerinden daha iyi performans gösterdi (şimdi 70'den fazla oyunda test edildi). Aslında, oyunların yarısından fazlasında, profesyonel bir insan oyuncunun seviyesinin %75'inden fazlasında performans gösterdi. Hatta bazı oyunlarda DQN, ulaşılabilecek maksimum puanı elde etmesini sağlayan şaşırtıcı derecede ileri görüşlü stratejiler bile geliştirdi; örneğin Breakout'ta , topun zıplaması için önce tuğla duvarın bir ucunda bir tünel kazmayı öğrendi. arkadan çevreleyin ve arkadan tuğlaları nakavt edin.
Politika ve Değer Ağları
AlphaGo içinde iki ana ağ türü vardır:
AlphaGo'nun DQN'lerinin hedeflerinden biri, insan uzman oyununun ötesine geçmek ve milyonlarca kez kendine karşı oynayarak ve böylece ağırlıkları aşamalı olarak geliştirerek yeni yenilikçi hareketleri taklit etmektir. Bu DQN, yaygın DNN'lere karşı %80 kazanma oranına sahipti. DeepMind, bu iki sinir ağını (DNN ve DQN) ilk ağ türünü oluşturmak için birleştirmeye karar verdi - bir 'Politika Ağı'. Kısaca, bir politika ağının işi, bir sonraki hamle arayışının genişliğini azaltmak ve daha fazla araştırmaya değer birkaç iyi hamle bulmaktır.
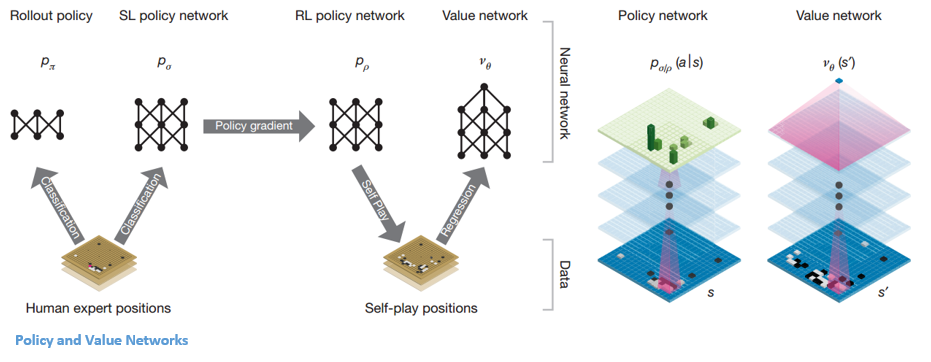 Politika ağı bir kez dondurulduğunda, milyonlarca kez kendisine karşı oynar. Bu oyunlar, çeşitli tahta pozisyonlarından ve oyunların sonuçlarından oluşan yeni bir Go veri seti oluşturur. Bu veri seti, bir değerlendirme fonksiyonu oluşturmak için kullanılır. İkinci tür işlev – 'Değer Ağı' oyunun sonucunu tahmin etmek için kullanılır. Girdi olarak çeşitli tahta pozisyonlarını almayı ve oyunun sonucunu ve ölçüsünü tahmin etmeyi öğrenir.
Politika ağı bir kez dondurulduğunda, milyonlarca kez kendisine karşı oynar. Bu oyunlar, çeşitli tahta pozisyonlarından ve oyunların sonuçlarından oluşan yeni bir Go veri seti oluşturur. Bu veri seti, bir değerlendirme fonksiyonu oluşturmak için kullanılır. İkinci tür işlev – 'Değer Ağı' oyunun sonucunu tahmin etmek için kullanılır. Girdi olarak çeşitli tahta pozisyonlarını almayı ve oyunun sonucunu ve ölçüsünü tahmin etmeyi öğrenir.
Politika ve Değer Ağlarını Birleştirme
Tüm bu eğitimlerden sonra, DeepMind sonunda iki sinir ağı ile sonuçlandı: Politika ve Değer Ağları. Politika ağı, tahta pozisyonunu bir girdi olarak alır ve o pozisyondaki her bir hareketin olasılığı olarak olasılık dağılımını verir. Değer ağı yine tahtanın pozisyonunu girdi olarak alır ve 0 ile 1 arasında tek bir gerçek sayı çıkarır. taşlar.
Politika ağı mevcut pozisyonları değerlendirir ve değer ağı gelecekteki hareketleri değerlendirir. DeepMind tarafından görevlerin bu iki ağa bölünmesi, AlphaGo'nun başarısının arkasındaki ana nedenlerden biriydi.
Politika ve Değer ağlarını Monte Carlo Ağaç Arama (MCTS) ve Kullanıma Sunma ile birleştirme
Sinir ağları tek başına yeterli olmayacaktır. Go oyununu kazanmak için biraz daha strateji gerekiyor. Bu plan, MCTS'nin yardımıyla gerçekleştirilir. Monte Carlo Ağaç Arama ayrıca iki sinir ağını yenilikçi bir şekilde birleştirmeye yardımcı olur. Sinir ağları, bir sonraki en iyi hamle için verimli bir aramaya yardımcı olur.
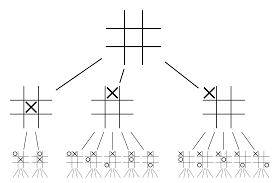
Tüm bunları çok daha iyi görselleştirmenize yardımcı olacak bir örnek oluşturmaya çalışalım. Oyunun daha önce karşılaşılmamış yeni bir konumda olduğunu hayal edin. Böyle bir durumda, mevcut durumu ve gelecekteki olası yolları değerlendirmek için bir politika ağı çağrılır; Monte Carlo sunumları tarafından desteklenen Değer ağları tarafından yolların arzu edilirliği ve her hareketin değeri.
Politika ağı olası tüm “iyi” hamleleri bulur ve değer ağları bunların her bir sonucunu değerlendirir. Monte Carlo sunumlarında, politika ağı tarafından tanınan pozisyonlardan birkaç bin rastgele oyun oynanır. Değer ağlarının Monte Carlo sunumlarına göre göreli önemini belirlemek için deneyler yapıldı. Bu deneyin sonucunda DeepMind, Value ağlarına %80 ağırlık ve Monte Carlo kullanıma sunma değerlendirme işlevine %20 ağırlık atadı.
Politika ağı, aramanın genişliğini 200 küsur olası hamleden 4 veya 5 en iyi hamleye düşürür. Politika ağı, dikkate alınması gereken bu 4 veya 5 adımdan ağacı genişletir. Değer ağı, oyunun sonucunu o konumdan anında döndürerek ağaç aramasının derinliğini azaltmaya yardımcı olur. Son olarak Q değeri en yüksek olan hareket yani maksimum fayda sağlayan adım seçilir.
“ Oyun öncelikle sezgi ve his yoluyla oynanır ve güzelliği, inceliği ve entelektüel derinliği nedeniyle yüzyıllardır insanın hayal gücünü ele geçirmiştir.”
– Demis Hassabis
AlphaGo'nun gerçek dünya problemlerine uygulanması
DeepMind'ın web sitesindeki vizyonu çok şey anlatıyor: “Zekayı çözün. Bu bilgiyi dünyayı daha iyi bir yer haline getirmek için kullanın”. Bu algoritmanın nihai amacı, karmaşık gerçek dünya problemlerini çözmek için kullanılabilmesi için onu genel amaçlı yapmaktır. DeepMind'ın AlphaGo'su, AGI arayışında ileriye doğru atılmış önemli bir adımdır. DeepMind, teknolojisini gerçek dünyadaki sorunları çözmek için başarıyla kullandı – hadi bazı örneklere bakalım:
Enerji tüketiminde azalma
DeepMind'ın yapay zekası, Google'ın veri merkezi soğutma maliyetini %40 oranında azaltmak için başarıyla kullanıldı. Herhangi bir büyük ölçekli enerji tüketen ortamda bu gelişme, ileriye doğru olağanüstü bir adımdır. Bir veri merkezi için birincil enerji tüketimi kaynaklarından biri soğutmadır. Sunucuların çalıştırılmasından kaynaklanan çok fazla ısının, çalışır durumda kalması için çıkarılması gerekir. Bu, pompalar, soğutucular ve soğutma kuleleri gibi büyük ölçekli endüstriyel ekipmanlarla gerçekleştirilir. Veri merkezinin ortamı çok dinamik olduğundan, optimum enerji verimliliğinde çalışmak zordur. DeepMind'ın yapay zekası bu sorunu çözmek için kullanıldı.
İlk olarak, veri merkezindeki binlerce sensör tarafından toplanan geçmiş verileri kullanmaya başladılar. Bu verileri kullanarak, gelecekteki ortalama Güç Kullanım Etkinliği (PUE) konusunda bir grup DNN'yi eğittiler. Bu genel amaçlı bir algoritma olduğu için veri merkezi ortamında diğer zorluklara da uygulanması planlanmaktadır.
Bu teknolojinin olası uygulamaları arasında, aynı girdi biriminden daha fazla enerji elde etmek, yarı iletken üretim enerjisini ve su kullanımını azaltmak vb. sayılabilir. DeepMind, blog yazısında bu bilginin gelecekteki bir yayında paylaşılacağını ve böylece diğer veri merkezlerinin, endüstriyel operatörler ve nihayetinde çevre bu önemli adımdan büyük ölçüde yararlanabilir.
Baş ve boyun kanserlerinde radyoterapi planlaması
DeepMind, kanser tedavisinde dünya lideri olan University College London Hospital'ın NHS Foundation Trust'taki radyoterapi bölümü ile işbirliği yaptı.
Büyük Veri ve Makine Öğrenimi Kansere Karşı Nasıl Birleşiyor?
75 erkekten biri ve 150 kadından biri yaşamları boyunca ağız kanserine yakalanmaktadır. Baş ve boyun bölgesindeki yapıların ve organların hassas yapısı nedeniyle radyologların tedavileri sırasında çok dikkatli olmaları gerekir.
Radyoterapi uygulanmadan önce tedavi edilecek alanlar ve kaçınılması gereken alanların ayrıntılı bir haritasının hazırlanması gerekir. Bu, segmentasyon olarak bilinir. Bu parçalı harita, sağlıklı hücrelere zarar vermeden kanser hücrelerini hedefleyecek olan radyografi makinesine beslenir.
Baş veya boyun bölgesi kanseri durumunda, bu çok hassas organları içerdiğinden radyologlar için zahmetli bir iştir. Radyologların bu alan için bölümlere ayrılmış bir harita oluşturması yaklaşık dört saat sürer. DeepMind, algoritmaları aracılığıyla, bölümlere ayrılmış haritaların oluşturulması için gereken süreyi dört saatten bir saate indirmeyi hedefliyor. Bu, radyoloğun zamanını önemli ölçüde boşaltacaktır. Daha da önemlisi, bu segmentasyon algoritması vücudun diğer kısımları için kullanılabilir.
Özetlemek gerekirse, AlphaGo 2016'da 18 kez dünya Go şampiyonu Lee Seedol'u beşin en iyisi turnuvasında dört kez başarılı bir şekilde yendi. 2017'de dünyanın en iyi oyuncularından oluşan bir takımı bile yendi. Bir sonraki en iyi hamleyi bulmak için bir politika ağı olarak DNN ve DQN'nin bir kombinasyonunu ve oyunun sonucunu değerlendirmek için bir değer ağı olarak bir DNN'yi kullanır. Monte Carlo ağaç araması, aramanın genişliğini ve derinliğini azaltmak için hem politika hem de değer ağlarıyla birlikte kullanılır - bunlar değerlendirme işlevini geliştirmek için kullanılır. Bu algoritmanın nihai amacı, masa oyunlarını çözmek değil, bir Yapay Genel Zeka algoritması icat etmektir. AlphaGo, şüphesiz bu yönde büyük bir adım önde.
Veri Bilimi, Makine Öğrenimi ve Büyük Veri Arasındaki Fark!
Elbette başka etkiler de oldu. AlphaGo Vs Lee Seedol haberi viral hale geldikçe, Go panolarına olan talep on kat arttı. Birçok mağaza Go panolarının stoklarının tükendiğini bildirdi ve bir Go panosu satın almak zorlaştı.
Neyse ki, bir tane buldum ve kendim ve çocuğum için sipariş ettim. Tahtayı satın alıp Go'yu öğrenmeyi mi planlıyorsunuz?
Dünyanın en iyi Üniversitelerinden ML kursları öğrenin. Kariyerinizi hızlandırmak için Master, Executive PGP veya Advanced Certificate Programları kazanın.
Derin pekiştirmeli öğrenmenin sınırlamaları nelerdir?
DL, yeni veriler veya bilgiler sunulduğunda önceden edinilmiş bilgileri unutur, bu nedenle ona meydan okumaz. Çok fazla pekiştirme bazen çok fazla durumla sonuçlanarak etkinliği düşürür. Veri modellerinin karmaşıklığı nedeniyle eğitim son derece maliyetlidir. Derin öğrenme ayrıca pahalı GPU'ların ve yüzlerce iş istasyonunun kullanılmasını gerektirir. Sonuç olarak, kullanımı daha az ekonomik hale gelir.
Monte Carlo Ağaç Aramayı kullanmanın eksileri nelerdir?
MCTS, yürütülmesi basit bir algoritma olmasına rağmen, bazı dezavantajları vardır. Ağaç birkaç yinelemeden sonra büyüdüğünde, çok fazla bellek gerekir. Sıra tabanlı oyunlara uygulandığında, belirli koşullarda rakibe karşı kaybetmeye yol açan tek bir dal veya yol olabilir. Sonuç olarak, biraz daha az güvenilirdir. Birçok yinelemeden sonra, Monte Carlo Ağaç Aramanın en etkili yolu belirlemesi uzun zaman alır.
AlphaZero'nun AlphaGo Zero'dan farkı nedir?
AlphaGo'nun önceki sürümleri, az sayıda elle tasarlanmış özellik içeriyordu, ancak AlphaGo Zero, yalnızca Go kartındaki siyah ve beyaz taşları girdi olarak kullanıyor. AlphaGo'nun önceki sürümleri, bir sonraki hamleyi seçmek için bir politika ağına ve her pozisyondan oyunun kazananını tahmin etmek için bir değer ağına güveniyordu. Bunlar AlphaGo Zero ile birleşerek daha verimli eğitim ve değerlendirme sağlar. Tüm bu farklılıklar, sistemin geliştirilmiş performansına ve genelleştirilmesine katkıda bulunur. Algoritmik ayarlama ise sistemi çok daha güçlü ve verimli hale getirir.