
Go and the Challenge to Artificial General Intelligence
公開: 2018-02-15この記事は、ゲーム「囲碁」と人工知能の関係を探ることを目的としています。 目的は質問に答えることです–囲碁のゲームを特別なものにしているのは何ですか? 囲碁のゲームをコンピューターでマスターするのが難しいのはなぜですか? コンピュータプログラムが1997年にチェスのグランドマスターを打ち負かすことができたのはなぜですか? Goをクラックするのに20年近くかかったのはなぜですか?
「紳士は些細なゲームに時間を無駄にすべきではありません–彼らは囲碁を勉強するべきです」
–孔子
実際、人工知能の専門家は、コンピューターは2027年までに囲碁の世界チャンピオンを打ち負かすことができると考えていました。Google傘下の人工知能企業であるDeepMindのおかげで、この手ごわい仕事は10年前に達成されました。 この記事では、囲碁の世界チャンピオンを打ち負かすためにDeepMindが使用するテクノロジーについて説明します。 最後に、この投稿では、このテクノロジーを使用して、複雑な現実の問題を解決する方法について説明します。
目次
行く–それはなんですか?
Goは3000年前の中国の戦略ボードゲームで、長年にわたって人気を維持しています。 世界中の何千万人もの人々がプレイするGoは、シンプルなルールと直感的な戦略を備えた2人用ボードゲームです。 このゲームをプレイするためにさまざまなボードサイズが使用されています。 専門家は19×19のボードを使用します。

ゲームは空のボードから始まります。 次に、各プレーヤーが交代で黒と白の石(黒が最初になります)を線の交点に配置します(正方形に駒を配置するチェスとは異なります)。 プレイヤーは、敵の石を四方から囲むことで、相手の石を捕らえることができます。 捕獲された石ごとに、いくつかのポイントがプレーヤーに与えられます。 ゲームの目的は、対戦相手の石を捕獲するとともに、ボード上の最大の領域を占めることです。
破壊に関するチェスとは異なり、囲碁は創造に関するものです。 Goには、ゲームをマスターするための自由、創造性、直感、バランス、戦略、および知的深さが必要です。 Goをプレイするには、脳の両側が関係します。 実際、Goプレーヤーの脳スキャンは、Goが両方の大脳半球間の接続を改善することによって脳の発達に役立つことを明らかにしました。
ダミーのためのニューラルネットワーク:包括的なガイド
Go and the Challenge to Artificial Intelligence(AI)
コンピューターは1952年にTic-Tac-Toeを習得することができました。 ディープブルーは1997年にチェスのグランドマスターであるギャリーカスパロフを倒すことができました。 コンピュータプログラムは、 2001年にジェパディ(人気のあるアメリカのゲーム)で世界チャンピオンに勝つことができました。 DeepMindのAlphaGoは、 2016年に囲碁の世界チャンピオンを打ち負かすことができました。 コンピュータプログラムが囲碁のゲームをマスターするのはなぜ難しいと考えられているのですか?
チェスは8×8のボードでプレイされますが、Goは19×19のサイズのボードを使用します。 チェスゲームのオープニングでは、プレーヤーは20の可能な動きを持ちます。 囲碁のオープニングでは、プレーヤーは361の可能な動きを持つことができます。可能な囲碁ボードの位置の数は10の170乗に等しくなります。 私たちの宇宙の原子の数よりも! ボードポジションの潜在的な数は、Go googol回(10の100乗)をチェスよりも複雑にします。
チェスでは、各ステップで、プレーヤーは35の動きの選択肢に直面します。 平均して、囲碁プレーヤーは各ステップで250の可能な動きを持ちます。 チェスでは、どの位置でも、コンピューターがブルートフォース検索を実行し、勝つ可能性を最大化する可能な限り最良の動きを選択するのは比較的簡単です。 Goの場合、各ステップで許可される合法的な移動の潜在的な数が膨大であるため、ブルートフォース検索は不可能です。
コンピューターがチェスをマスターする場合、ボードから駒が取り除かれるため、ゲームが進むにつれて簡単になります。 囲碁では、ゲームが進むにつれて石がボードに追加されるため、コンピュータプログラムはより困難になります。 通常、囲碁ゲームはチェスのゲームより3倍長く続きます。
これらすべての理由により、トップコンピューターのGoプログラムは、新しい機械学習技術が爆発的に増加した後、2016年にGoの世界チャンピオンに追いつくことができました。 DeepMindで働いている科学者たちは、世界チャンピオンのLeeSeedolを打ち負かしたAlphaGoというコンピュータープログラムを思いつくことができました。 タスクを達成することは容易ではありませんでした。 DeepMindの研究者は、AlphaGoを作成する過程で多くの斬新なイノベーションを思いつきました。
「囲碁のルールは非常にエレガントで、有機的で、厳密に論理的であるため、インテリジェントな生命体が宇宙の他の場所に存在する場合、それらはほぼ確実に囲碁を演じます。」
–エドワード・ラスカー
ニューラルネットワーク:実世界でのアプリケーション
AlphaGoのしくみ
AlphaGoは汎用アルゴリズムです。つまり、他のタスクの解決にも使用できます。 たとえば、IBMのDeep Blueは、チェスをするために特別に設計されています。 チェスのルールは、何世紀にもわたってゲームをプレイしてきた蓄積された知識とともに、プログラムの頭脳にプログラムされています。 ディープブルーは、Tic-Tac-Toeのような些細なゲームをプレイする場合でも使用できません。 それは、チェスをするという非常に得意な特定のことを1つだけ行うことができます。 AlphaGoは、囲碁以外のゲームのプレイ方法も学ぶことができます。 これらの汎用アルゴリズムは、人工知能と呼ばれる新しい研究分野を構成します。
AlphaGoは、最先端の手法を使用しています– Deep Neural Networks(DNN)、Reinforcement Learning(RL)、Monte Carlo Tree Search(MCTS)、Deep Q Networks(DQN)(DeepMindによって導入され、普及した新しい手法で、ニューラルネットワークを組み合わせています強化学習を備えたネットワーク)、いくつか例を挙げると。 次に、これらすべての方法を革新的に組み合わせて、囲碁のゲームで超人レベルの習得を達成します。
手元のタスクを達成するためにこれらのピースがどのように結び付けられているかを説明する前に、まずこのパズルの個々のピースを見てみましょう。
ディープニューラルネットワーク
DNNは、人間の脳の機能に大まかに触発された機械学習を実行する手法です。 DNNのアーキテクチャは、ニューロンの層で構成されています。 DNNは、明示的にプログラムされていなくても、データ内のパターンを認識できます。
誰も特別にプログラミングしなくても、入力を出力にマッピングします。 例として、たくさんの猫と犬の写真をネットワークに供給したと仮定します。 同時に、特定の画像が猫か犬かを(ラベルの形で)伝えることでシステムをトレーニングしています(これは教師あり学習と呼ばれます)。 DNNは、写真からパターンを認識して、猫と犬をうまく区別することを学習します。 トレーニングの主な目的は、DNNが犬または猫の新しい写真を見ると、それを正しく分類できるようにすることです。つまり、それが猫か犬かを予測できるようにする必要があります。
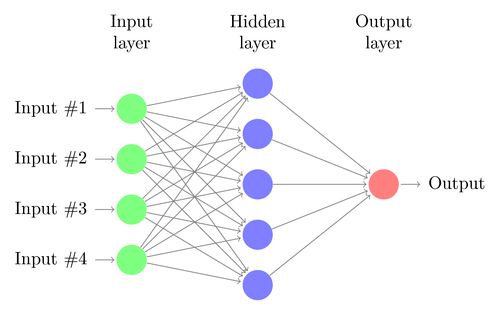
単純なDNNのアーキテクチャを理解しましょう。 入力層のニューロンの数は、入力のサイズに対応します。 猫と犬の写真が28×28の画像であると仮定します。 各行と列はそれぞれ28ピクセルで構成され、各画像の合計は784ピクセルになります。 このような場合、入力層は各ピクセルに1つずつ、784個のニューロンで構成されます。 出力層のニューロンの数は、出力を分類する必要があるクラスの数によって異なります。 この場合、出力層は2つのニューロンで構成されます。1つは「cat」に対応し、もう1つは「dog」に対応します。
次の大きなものに目を光らせてください:機械学習
入力層と出力層の間に多くのニューロン層があります(これは、「ディープニューラルネットワーク」で「ディープ」という用語を使用することの由来です)。 これらは「隠しレイヤー」と呼ばれます。 隠れ層の数と各層のニューロンの数は固定されていません。 実際、これらの値を変更することは、まさにパフォーマンスの最適化につながるものです。 これらの値はハイパーパラメータと呼ばれ、目前の問題に応じて調整する必要があります。 ニューラルネットワークを取り巻く実験は、主にハイパーパラメータの最適な数を見つけることを含みます。
DNNのトレーニングフェーズは、フォワードパスとバックワードパスで構成されます。 まず、ニューロン間のすべての接続がランダムな重みで初期化されます。 フォワードパスの間、ネットワークには単一の画像が供給されます。 入力(画像からのピクセルデータ)は、ネットワークのパラメーター(重み、バイアス、および活性化関数)と組み合わされ、非表示のレイヤーを介してフィードフォワードされ、出力に到達します。これにより、それぞれに属する写真の確率が返されます。クラスの。
次に、この確率が実際のクラスラベルと比較され、「エラー」が計算されます。 この時点で、バックワードパスが実行されます。このエラー情報は、「バックプロパゲーション」と呼ばれる手法を介してネットワークを介して返されます。 トレーニングの初期段階では、このエラーは高くなり、優れたトレーニングメカニズムによってこのエラーは徐々に減少します。
DNNは、重みの変化が停止するまで、順方向パスと逆方向パスを使用してこのようにトレーニングされます(これは収束と呼ばれます)。 そうすれば、DNNは画像を高精度で予測および分類できるようになります。つまり、画像に猫がいるのか犬がいるのかがわかります。

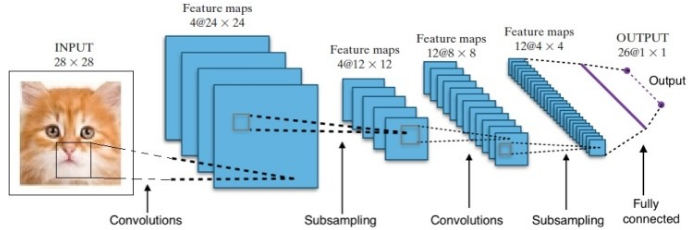
研究により、さまざまなディープニューラルネットワークアーキテクチャが提供されました。 コンピュータビジョンの問題(つまり、画像に関連する問題)の場合、畳み込みニューラルネットワーク(CNN)は伝統的に良い結果をもたらしてきました。 シーケンス(音声認識または言語翻訳)に関連する問題の場合、リカレントニューラルネットワーク(RNN)は優れた結果を提供します。
自然言語理解の初心者向けガイド
AlphaGoの場合、プロセスは次のとおりでした。最初に、畳み込みニューラルネットワーク(CNN)は、取締役会の位置の何百万もの画像でトレーニングされました。 次に、ネットワークは、ネットワークのトレーニングフェーズ中にそれぞれの場合に人間の専門家によって行われたその後の動きについて通知されました。 前述と同じ方法で、実際の値を出力と比較し、ある種の「エラー」メトリックが見つかりました。
トレーニングの最後に、DNNは、エキスパートの人間のプレーヤーによってプレイされる可能性が高い確率とともに、次の動きを出力します。 この種のネットワークは、人間のエキスパートプレーヤーによって実行されるステップを思い付くことができるだけです。 DeepMindは、人間が行う動きを予測する際に60%の精度を達成することができました。 しかし、囲碁で人間の専門家を打ち負かすには、これだけでは不十分です。 DNNからの出力は、DeepMindによって考案されたアプローチであるDeep Reinforcement Networkによってさらに処理されます。これは、ディープニューラルネットワークと強化学習を組み合わせたものです。

深層強化学習
強化学習(RL)は新しい概念ではありません。 ノーベル賞受賞者のイワン・パブロフは、犬の古典的条件付けを実験し、1902年に強化学習の原理を発見しました。RLは、人間が新しいスキルを学ぶ方法の1つでもあります。 ショーのイルカが水からこんなに高いところにジャンプするようにどのように訓練されているのか疑問に思ったことはありませんか? それはRLの助けを借りています。 まず、イルカの準備に使用するロープをプールに沈めます。 イルカがケーブルを上から横切るたびに、餌が与えられます。 それがロープを越えないとき、報酬は撤回されます。 ゆっくりとイルカは、上からコードを通過するたびに支払われることを学習します。 イルカを訓練するためにロープの高さを徐々に上げていきます。 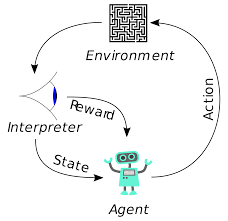
自然言語生成:知っておくべき重要事項
強化学習のエージェントも同じ原則を使用してトレーニングされます。 エージェントはアクションを実行し、環境と対話します。 エージェントが実行するアクションにより、環境が変化します。 さらに、エージェントは環境に関するフィードバックを受け取りました。 エージェントは、その行動と目前の目的に応じて、報酬を受け取るかどうかを決定します。 重要な点は、当面のこの目的はエージェントに対して明確に述べられていないということです。 十分な時間が与えられると、エージェントは将来の報酬を最大化する方法を学びます。
これをDNNと組み合わせて、DeepMindはDeep Reinforcement Learning(DRL)またはDeep Q Networks(DQN)を発明しました。ここで、Qは得られる最大の将来の報酬を表します。 DQNは最初にAtariゲームに適用されました。 DQNは、箱から出してすぐにさまざまな種類のAtariゲームをプレイする方法を学びました。 画期的なことは、さまざまな種類のAtariゲームを表現するために明示的なプログラミングが必要ないことでした。 単一のプログラムは、ゲームのさまざまな環境すべてについて学ぶのに十分賢く、セルフプレイを通じて、それらの多くを習得することができました。
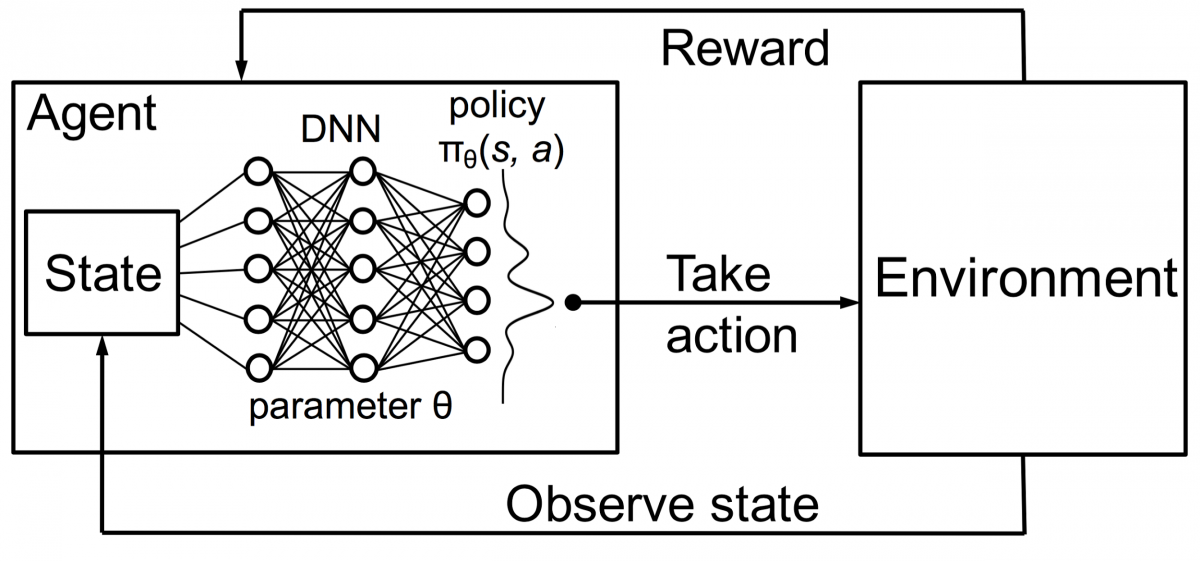
2014年、DQNは49ゲーム中43ゲームで以前の機械学習手法を上回りました(現在、70以上のゲームでテストされています)。 実際、ゲームの半分以上で、プロの人間プレーヤーのレベルの75%以上でパフォーマンスを発揮しました。 特定のゲームでは、DQNは、達成可能な最大スコアを達成できるようにする驚くほど先見の明のある戦略を考え出しました。たとえば、ブレイクアウトでは、最初にレンガの壁の一方の端にトンネルを掘ることを学び、ボールが跳ね返ります。後ろからレンガをノックアウトします。
ポリシーとバリューネットワーク
AlphaGo内のネットワークには主に2つのタイプがあります。
AlphaGoのDQNの目的の1つは、人間の専門家のプレイを超えて、何百万回も対戦し、それによって重みを段階的に改善することによって、新しい革新的な動きを模倣することです。 このDQNは、一般的なDNNに対して80%の勝率を示しました。 DeepMindは、これら2つのニューラルネットワーク(DNNとDQN)を組み合わせて、最初のタイプのネットワークである「ポリシーネットワーク」を形成することを決定しました。 簡単に言えば、ポリシーネットワークの仕事は、次の動きの検索の幅を狭め、さらに調査する価値のあるいくつかの良い動きを考え出すことです。
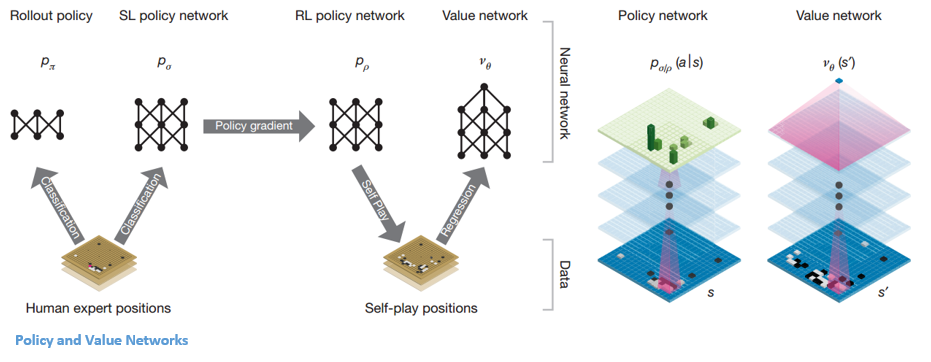 ポリシーネットワークが凍結されると、それ自体が何百万回も対戦します。 これらのゲームは、さまざまなボードの位置とゲームの結果で構成される新しいGoデータセットを生成します。 このデータセットは、評価関数を作成するために使用されます。 2番目のタイプの関数–「バリューネットワーク」は、ゲームの結果を予測するために使用されます。 さまざまなボードの位置を入力として受け取り、ゲームの結果とその測定値を予測することを学習します。
ポリシーネットワークが凍結されると、それ自体が何百万回も対戦します。 これらのゲームは、さまざまなボードの位置とゲームの結果で構成される新しいGoデータセットを生成します。 このデータセットは、評価関数を作成するために使用されます。 2番目のタイプの関数–「バリューネットワーク」は、ゲームの結果を予測するために使用されます。 さまざまなボードの位置を入力として受け取り、ゲームの結果とその測定値を予測することを学習します。
ポリシーとバリューネットワークの組み合わせ
このすべてのトレーニングの後、DeepMindは最終的に2つのニューラルネットワーク(ポリシーネットワークとバリューネットワーク)になりました。 ポリシーネットワークは、ボードの位置を入力として受け取り、その位置での各移動の可能性として確率分布を出力します。 バリューネットワークは再びボードの位置を入力として取り、0から1までの単一の実数を出力します。ネットワークの出力がゼロの場合、白が完全に勝っていることを意味し、1は黒のプレーヤーが完全に勝ったことを示します石。
ポリシーネットワークは現在の位置を評価し、バリューネットワークは将来の動きを評価します。 DeepMindによるこれら2つのネットワークへのタスクの分割は、AlphaGoの成功の背後にある主な理由の1つでした。
ポリシーおよびバリューネットワークとモンテカルロ木探索(MCTS)およびロールアウトの組み合わせ
ニューラルネットワークだけでは十分ではありません。 囲碁のゲームに勝つためには、もう少し戦略が必要です。 この計画は、MCTSの助けを借りて達成されます。 モンテカルロ木探索は、革新的な方法で2つのニューラルネットワークをつなぎ合わせるのにも役立ちます。 ニューラルネットワークは、次善の策を効率的に検索するのに役立ちます。
これらすべてをよりよく視覚化するのに役立つ例を作成してみましょう。 ゲームがこれまでに遭遇したことのない新しい位置にあると想像してみてください。 このような状況では、現在の状況と将来の可能性のある道筋を評価するために、政策ネットワークが求められます。 モンテカルロロールアウトでサポートされている、バリューネットワークによるパスの望ましさと各移動の価値。
ポリシーネットワークは、考えられるすべての「良い」動きを見つけ、バリューネットワークはそれぞれの結果を評価します。 モンテカルロロールアウトでは、ポリシーネットワークによって認識された位置から数千のランダムなゲームがプレイされます。 モンテカルロロールアウトに対するバリューネットワークの相対的な重要性を判断するための実験が行われました。 この実験の結果、DeepMindはバリューネットワークに80%の重みを割り当て、モンテカルロロールアウト評価関数に20%の重みを割り当てました。
ポリシーネットワークは、検索の幅を200回の可能な移動から4回または5回の最良の移動に減らします。 ポリシーネットワークは、考慮が必要なこれらの4つまたは5つのステップからツリーを拡張します。 バリューネットワークは、ゲームの結果をその位置から即座に返すことにより、ツリー検索の深さを減らすのに役立ちます。 最後に、Q値が最も高い移動、つまり最大の利益をもたらすステップが選択されます。
「ゲームは主に直感と感覚でプレイされ、その美しさ、繊細さ、知的な深さのために、何世紀にもわたって人間の想像力を捉えてきました。」
–デミス・ハサビス
AlphaGoの実際の問題への適用
彼らのウェブサイトからのDeepMindのビジョンは、非常にわかりやすいものです。 この知識を使って、世界をより良い場所にしてください。」 このアルゴリズムの最終目標は、複雑な実世界の問題を解決するために使用できるように、それを汎用にすることです。 DeepMindのAlphaGoは、AGIの探求における重要な前進です。 DeepMindは、そのテクノロジーを使用して実際の問題を解決しました。いくつかの例を見てみましょう。
エネルギー消費量の削減
DeepMindのAIは、Googleのデータセンターの冷却コストを40%削減するためにうまく利用されました。 大規模なエネルギー消費環境では、この改善は驚異的な前進です。 データセンターの主なエネルギー消費源の1つは、冷却です。 サーバーの稼働を維持するには、サーバーの実行によって発生する多くの熱を取り除く必要があります。 これは、ポンプ、チラー、冷却塔などの大規模な産業機器によって実現されます。 データセンターの環境は非常に動的であるため、最適なエネルギー効率で運用することは困難です。 DeepMindのAIは、この問題に取り組むために使用されました。
まず、データセンター内の何千ものセンサーによって収集された履歴データを使用して続行しました。 このデータを使用して、彼らはDNNのアンサンブルを平均的な将来の電力使用効率(PUE)でトレーニングしました。 これは汎用アルゴリズムであるため、データセンター環境における他の課題にも適用される予定です。
このテクノロジーの可能なアプリケーションには、同じ入力単位からより多くのエネルギーを取得すること、半導体製造エネルギーと水の使用量を減らすことなどが含まれます。DeepMindはブログ投稿で、この知識が将来の出版物で共有され、他のデータセンター、産業用オペレーター、そして最終的には環境は、この重要なステップから大きな恩恵を受けることができます。
頭頸部がんの放射線治療計画
DeepMindは、癌治療の世界的リーダーであるユニバーシティカレッジロンドンホスピタルのNHSFoundationTrustの放射線治療部門と協力しています。
ビッグデータと機械学習が癌に対してどのように統合されているか
男性75人に1人、女性150人に1人が生涯に口腔がんと診断されています。 頭頸部の構造や臓器は敏感な性質を持っているため、放射線科医はそれらを治療する際に細心の注意を払う必要があります。
放射線治療を行う前に、治療する領域と避けるべき領域を含む詳細なマップを作成する必要があります。 これはセグメンテーションとして知られています。 このセグメント化されたマップはX線撮影装置に送られ、X線撮影装置は健康な細胞に害を与えることなく癌細胞を標的にします。
頭頸部の癌の場合、これは非常に敏感な臓器を含むため、放射線科医にとって骨の折れる仕事です。 放射線科医がこの地域のセグメント化された地図を作成するのに約4時間かかります。 DeepMindは、そのアルゴリズムを通じて、セグメント化されたマップの生成に必要な時間を4時間から1時間に短縮することを目指しています。 これにより、放射線科医の時間が大幅に解放されます。 さらに重要なことに、このセグメンテーションアルゴリズムは体の他の部分に利用できます。
要約すると、AlphaGoは2016年のベストオブファイブトーナメントで18回の囲碁チャンピオンであるリーシードルを4回破りました。2017年には、世界最高の選手のチームをも破りました。 DNNとDQNの組み合わせをポリシーネットワークとして使用して次善の策を考え出し、1つのDNNをバリューネットワークとして使用してゲームの結果を評価します。 モンテカルロ木探索は、ポリシーネットワークとバリューネットワークの両方とともに使用され、検索の幅と深さを減らします。これらは、評価関数を改善するために使用されます。 このアルゴリズムの最終的な目的は、ボードゲームを解決することではなく、人工知能アルゴリズムを発明することです。 AlphaGoは間違いなくその方向への大きな一歩です。
データサイエンス、機械学習、ビッグデータの違い!
もちろん、他の効果もあります。 AlphaGo対LeeSeedolのニュースが広まるにつれて、Goボードの需要は10倍に急増しました。 多くの店舗で囲碁の在庫がなくなったとの報告があり、囲碁の購入が難しくなりました。
幸いなことに、私はそれを見つけて、自分と子供のために注文しました。 ボードを購入してGoを学ぶ予定ですか?
世界のトップ大学からMLコースを学びましょう。 マスター、エグゼクティブPGP、または高度な証明書プログラムを取得して、キャリアを迅速に追跡します。
深層強化学習の制限は何ですか?
DLは、新しいデータや情報が導入されたときに以前に得た知識を忘れてしまうため、それに異議を唱えることはありません。 強化が多すぎると、状態が過剰になり、効果が低下する場合があります。 データモデルは複雑であるため、トレーニングには非常にコストがかかります。 ディープラーニングでは、高価なGPUと数百台のワークステーションを使用する必要もあります。 その結果、使用するのが経済的ではなくなります。
モンテカルロ木探索を使用することの短所は何ですか?
MCTSは実行するのが簡単なアルゴリズムですが、いくつかの欠点があります。 数回の反復後にツリーが大きくなると、大量のメモリが必要になります。 ターン制のゲームに適用される場合、特定の条件で対戦相手に対して損失をもたらす単一のブランチまたはパスが存在する場合があります。 結果として、それは少し信頼性が低くなります。 何度も繰り返した後、モンテカルロ木探索は最も効果的なパスを決定するのに長い時間がかかります。
AlphaZeroはAlphaGoZeroとどう違うのですか?
AlphaGoの以前のバージョンには、少数の手作業による機能が組み込まれていましたが、AlphaGo Zeroは、Goボードの黒と白の石を入力として使用します。 AlphaGoの以前のバージョンは、ポリシーネットワークを使用して次の動きを選択し、バリューネットワークを使用して各ポジションからゲームの勝者を推定していました。 これらはAlphaGoZeroに統合され、より効率的なトレーニングと評価が可能になります。 これらの違いはすべて、システムのパフォーマンスと一般化の向上に貢献します。 一方、アルゴリズムによる調整により、システムははるかに強力で効率的になります。