
決策樹示例:功能和實現 [逐步]
已發表: 2020-12-28目錄
介紹
決策樹是用於回歸和分類任務的最強大和最流行的算法之一。 它們是類似結構的流程圖,屬於監督算法的範疇。 決策樹像流程圖一樣可視化的能力使它們能夠輕鬆模仿人類的思維水平,這就是這些決策樹易於理解和解釋的原因。
什麼是決策樹?
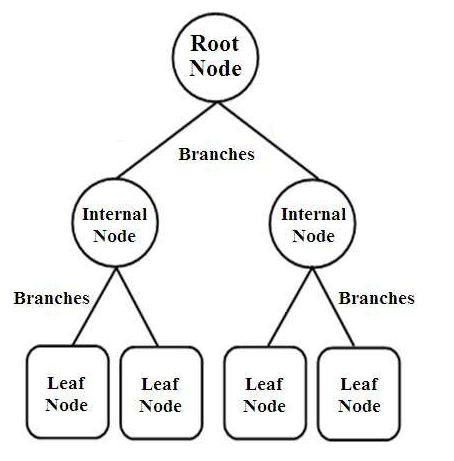
決策樹是一種樹形結構的分類器。 它們具有三種類型的節點,它們是,
- 根節點
- 內部節點
- 葉節點
圖片來源
根節點是代表整個樣本的主要節點,該樣本進一步分為幾個其他節點。 內部節點代表對屬性的測試,而分支代表測試的決定。 最後,葉子節點表示標籤的類別,這是所有屬性編譯後做出的決定。 了解有關決策樹學習的更多信息。
決策樹如何工作?
決策樹通過從根節點到葉節點對整個樹結構進行排序來用於分類。 決策樹使用的這種方法稱為自頂向下方法。 一旦一個特定的數據點被輸入到決策樹中,它就會通過回答是/否問題來通過樹的每個節點,直到它到達特定的指定葉節點。
決策樹中的每個節點代表一個屬性的測試用例,每個下降(分支)到一個新節點對應於該測試用例的可能答案之一。 這樣,通過多次迭代,決策樹預測回歸任務的值或在分類任務中對對象進行分類。

決策樹實現
現在我們已經了解了決策樹的基礎知識,讓我們繼續了解它在 Python 編程中的執行。
問題分析
在下面的示例中,我們將使用著名的“鳶尾花”數據集。 這個小型數據集最初於 1936 年在 UCI 機器學習存儲庫(鏈接: https ://archive.ics.uci.edu/ml/datasets/Iris )上發布,廣泛用於測試機器學習算法和可視化。
其中,共有 150 行 5 列,其中 4 列是屬性或特徵,最後一列是鳶尾花種類。 鳶尾花是植物學中開花植物的一個屬。 cm中的四個屬性是,
- 萼片長度
- 萼片寬度
- 花瓣長度
- 花瓣寬度
這四個特徵用於根據大小和形狀來定義和分類鳶尾花的類型。 第 5列或最後一列由鳶尾花類組成,分別是 Iris Setosa、Iris Versicolor 和 Iris Virginica。
對於我們的問題,我們必須利用決策樹算法構建一個機器學習模型來學習特徵並根據鳶尾花類對其進行分類。
讓我們一步一步地在python中實現它:
第 1 步:導入庫
在 Python 中構建任何機器學習模型的第一步是導入必要的庫,例如 Numpy、Pandas 和 Matplotlib。 樹模塊是從 sklearn 庫中導入的,最後將決策樹模型可視化。
第 2 步:導入數據集
導入 Iris 數據集後,我們將 .csv 文件存儲到 Pandas DataFrame 中,我們可以從中輕鬆訪問表格的列和行。 數據框的前四列是自變量或決策樹分類器要理解的特徵,並存儲在變量 X 中。
由 3 個物種組成的鳶尾花類的因變量存儲在變量 y 中。 通過打印前 5 行來可視化數據集。


另請閱讀:決策樹分類
步驟 3:將數據集拆分為訓練集和測試集
在接下來的步驟中,在讀取數據集後,我們必須將整個數據集拆分為訓練集,用於訓練分類器模型和測試集,將在其上實現訓練模型。 將比較在測試集上獲得的結果,以檢查訓練模型的準確性。
在這裡,我們使用了 0.25 的測試大小,這表示整個數據集的 25% 將被隨機拆分為測試集,其餘 75% 將包含用於訓練模型的訓練集。 因此,在 150 個數據點中,保留 38 個隨機數據點作為測試集,其餘 112 個樣本用於訓練集。

第 4 步:在訓練集上訓練決策樹分類模型
一旦模型被分割並準備好用於訓練目的,DecisionTreeClassifier 模塊將從 sklearn 庫中導入,並將訓練變量(X_train 和 y_train)安裝在分類器上以構建模型。 在這個訓練過程中,分類器經過梯度下降和反向傳播等多種優化方法,最終建立決策樹分類器模型。

第 5 步:預測測試集結果
既然我們已經準備好了模型,我們不應該在測試集上檢查它的準確性嗎? 此步驟涉及在先前拆分的測試集上測試使用決策樹算法構建的模型。 這些結果存儲在變量“y_pred”中。
![]()
第 6 步:將實際值與預測值進行比較
這是另一個簡單的步驟,我們將在其中構建另一個簡單的數據框,該數據框由兩列組成,一側是測試集的真實值,另一側是預測值。 這一步使我們能夠比較所建立的模型所獲得的結果。
![]()
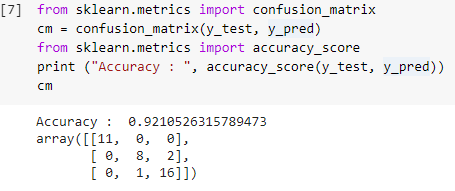
第 7 步:混淆矩陣和準確性
現在我們有了測試集的真實值和預測值,讓我們構建一個簡單的分類矩陣併計算使用 sklearn 中的簡單庫函數構建的模型的準確性。 準確度分數是通過輸入測試集的真實值和預測值來計算的。 使用上述步驟構建的模型為我們提供了 92.1% 的準確度,在下面的步驟中表示為 0.92105。
混淆矩陣是一個表格,用於顯示對分類問題的正確和錯誤預測。 為簡單起見,對角線上的值表示正確的預測,對角線之外的其他值表示不正確的預測。
在計算 38 個測試集數據點的數量時,我們得到 35 個正確的預測和 3 個錯誤的預測,準確率為 92%。 在訓練模型之前,可以通過優化超參數來提高準確性,這些超參數可以作為分類器的參數。
第 8 步:可視化決策樹分類器
最後,在最後一步中,我們將可視化構建的決策樹。 在註意到根節點時,可以看到“樣本”的數量為 112,這與之前拆分的訓練集樣本是同步的。 GINI 指數在決策樹算法的每個步驟中計算,並且 3 個類被拆分,如決策樹中的“值”參數所示。

必讀:決策樹面試問答
結論
因此,通過這種方式,我們了解了決策樹算法的概念,並構建了一個簡單的分類器來使用該算法解決分類問題。
如果您有興趣了解有關決策樹、機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為在職專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業,IIIT-B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
使用決策樹有什麼缺點?
雖然決策樹有助於數據的分類或排序,但它們的使用有時也會產生一些問題。 通常,決策樹會導致數據過度擬合,從而進一步使最終結果非常不准確。 在大型數據集的情況下,不建議使用單個決策樹,因為它會導致複雜性。 此外,決策樹是高度不穩定的,這意味著如果您對給定數據集造成很小的變化,決策樹的結構就會發生很大變化。
隨機森林算法如何工作?
隨機森林本質上是不同決策樹的集合,就像森林是由許多樹組成的一樣。 隨機森林算法的結果實際上取決於決策樹的預測。 隨機森林技術還可以最大限度地減少數據過度擬合的可能性。 為了獲得所需的結果,隨機森林分類採用了集成方法。 訓練數據用於訓練各種決策樹。 當節點分離時,該數據集包含將隨機挑選的觀察值和屬性。
決策表與決策樹有何不同?
決策表可以從決策樹生成,但反過來不行。 決策樹由節點和分支組成,而決策表由行和列組成。 在決策表中,可以插入多個 or 條件。 在決策樹中,情況並非如此。 決策表僅在僅顯示少數屬性時才有用; 另一方面,決策樹可以有效地與大量屬性和復雜的邏輯一起使用。