
مثال على شجرة القرار: الوظيفة والتنفيذ [خطوة بخطوة]
نشرت: 2020-12-28جدول المحتويات
مقدمة
تعد أشجار القرار واحدة من أقوى الخوارزميات وأكثرها شيوعًا لكل من مهام الانحدار والتصنيف. إنها مخطط انسيابي مثل الهيكل وتقع ضمن فئة الخوارزميات الخاضعة للإشراف. إن قدرة أشجار القرار على تصور مثل مخطط انسيابي تمكنهم من محاكاة مستوى تفكير البشر بسهولة وهذا هو السبب في سهولة فهم أشجار القرار وتفسيرها.
ما هي شجرة القرار؟
أشجار القرار هي نوع من المصنفات ذات الهيكل الشجري. لديهم ثلاثة أنواع من العقد وهي ،
- عقد الجذر
- العقد الداخلية
- العقد الورقية
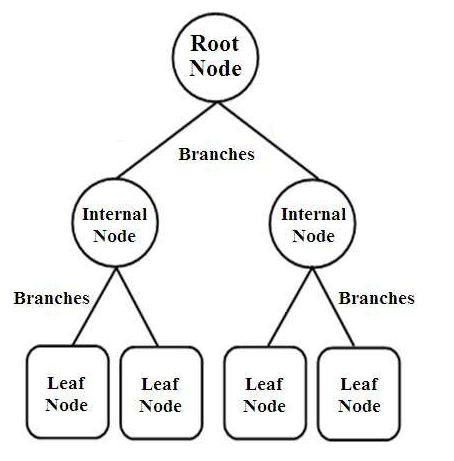
مصدر الصورة
العقد الجذرية هي العقد الأولية التي تمثل العينة بأكملها والتي يتم تقسيمها إلى عدة عقد أخرى. تمثل العقد الداخلية الاختبار على سمة بينما تمثل الفروع قرار الاختبار. أخيرًا ، تشير العقد الطرفية إلى فئة الملصق ، وهو القرار الذي يتم اتخاذه بعد تجميع جميع السمات. تعرف على المزيد حول تعلم شجرة القرار.
كيف تعمل أشجار القرار؟
تُستخدم أشجار القرار في التصنيف بفرزها أسفل بنية الشجرة بأكملها من عقدة الجذر إلى عقدة الورقة. يسمى هذا النهج الذي تستخدمه شجرة القرار بالنهج من أعلى إلى أسفل. بمجرد إدخال نقطة بيانات معينة في شجرة القرار ، يتم إجراؤها للمرور عبر كل عقدة في الشجرة من خلال الإجابة على أسئلة نعم / لا حتى تصل إلى العقدة الورقية المعينة المحددة.
تمثل كل عقدة في شجرة القرار حالة اختبار لسمة وكل نزول (فرع) إلى عقدة جديدة يتوافق مع إحدى الإجابات المحتملة لحالة الاختبار هذه. بهذه الطريقة ، مع التكرارات المتعددة ، تتوقع شجرة القرار قيمة لمهمة الانحدار أو تصنف الكائن في مهمة تصنيف.

تنفيذ شجرة القرار
الآن بعد أن أصبح لدينا أساسيات شجرة القرار ، دعنا ننتقل إلى تنفيذها في برمجة Python.
تحليل المشكلة
في المثال التالي سنستخدم مجموعة بيانات "زهرة القزحية" الشهيرة. نُشرت هذه المجموعة الصغيرة في الأصل عام 1936 في UCI Machine Learning Repository ، (الرابط: https://archive.ics.uci.edu/ml/datasets/Iris ) ، وتُستخدم على نطاق واسع لاختبار خوارزميات التعلم الآلي والتصورات.
في هذا ، يوجد إجمالي 150 صفًا و 5 أعمدة ، منها 4 أعمدة تمثل سمات أو ميزات والعمود الأخير هو نوع أنواع زهور السوسن. القزحية هي جنس من النباتات المزهرة في علم النبات. السمات الأربعة في سم هي ،
- طول سيبال
- عرض Sepal
- طول البتلة
- عرض البتلة
تُستخدم هذه الميزات الأربع لتحديد نوع زهرة القزحية وتصنيفها حسب الحجم والشكل. يتكون العمود الخامس أو الأخير من فئة زهرة السوسن ، وهي Iris Setosa و Iris Versicolor و Iris Virginica .
بالنسبة لمشكلتنا ، يتعين علينا بناء نموذج التعلم الآلي باستخدام خوارزمية شجرة القرار لتعلم الميزات وتصنيفها بناءً على فئة زهرة القزحية.
دعونا ننتقل إلى تنفيذه في لغة بيثون ، خطوة بخطوة:
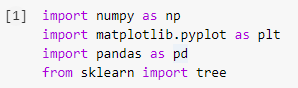
الخطوة 1: استيراد المكتبات
ستكون الخطوة الأولى في بناء أي نموذج للتعلم الآلي في Python هي استيراد المكتبات الضرورية مثل Numpy و Pandas و Matplotlib. يتم استيراد وحدة الشجرة من مكتبة sklearn لتصور نموذج شجرة القرار في النهاية.
الخطوة 2: استيراد مجموعة البيانات
بمجرد استيراد مجموعة بيانات Iris ، نقوم بتخزين ملف .csv في Pandas DataFrame يمكننا من خلاله الوصول بسهولة إلى أعمدة وصفوف الجدول. الأعمدة الأربعة الأولى من إطار البيانات هي المتغيرات المستقلة أو الميزات التي يجب أن يفهمها مصنف شجرة القرار ويتم تخزينها في المتغير X.
يتم تخزين المتغير التابع وهو فئة زهرة السوسن المكون من 3 أنواع في المتغير y. يتم تصور مجموعة البيانات عن طريق طباعة أول 5 صفوف.


اقرأ أيضًا: تصنيف شجرة القرار
الخطوة 3: تقسيم مجموعة البيانات إلى مجموعة التدريب ومجموعة الاختبار
في الخطوة التالية ، بعد قراءة مجموعة البيانات ، يتعين علينا تقسيم مجموعة البيانات بأكملها إلى مجموعة التدريب ، والتي سيتم تدريب نموذج المصنف عليها ومجموعة الاختبار التي سيتم تنفيذ النموذج المدرب عليها. ستتم مقارنة النتائج التي تم الحصول عليها في مجموعة الاختبار للتحقق من دقة النموذج المدرب.
هنا ، استخدمنا حجم اختبار يبلغ 0.25 ، مما يدل على أن 25٪ من مجموعة البيانات بأكملها سيتم تقسيمها عشوائيًا كمجموعة اختبار وستتكون نسبة 75٪ المتبقية من مجموعة التدريب التي سيتم استخدامها في تدريب النموذج. وبالتالي ، من بين 150 نقطة بيانات ، يتم الاحتفاظ بـ 38 نقطة بيانات عشوائية كمجموعة اختبار ويتم استخدام 112 عينة المتبقية في مجموعة التدريب.

الخطوة 4: تدريب نموذج تصنيف شجرة القرار على مجموعة التدريب
بمجرد تقسيم النموذج وأصبح جاهزًا لغرض التدريب ، يتم استيراد وحدة DecisionTreeClassifier من مكتبة sklearn ويتم تركيب متغيرات التدريب (X_train و y_train) على المصنف لبناء النموذج. خلال عملية التدريب هذه ، يخضع المصنف للعديد من طرق التحسين مثل Gradient Descent و Backpropagation وأخيراً يبني نموذج Decision Tree Classifier.

الخطوة 5: توقع نتائج مجموعة الاختبار
نظرًا لأن نموذجنا جاهز ، ألا يجب أن نتحقق من دقته في مجموعة الاختبار؟ تتضمن هذه الخطوة اختبار النموذج الذي تم إنشاؤه باستخدام خوارزمية شجرة القرار على مجموعة الاختبار التي تم تقسيمها مسبقًا. يتم تخزين هذه النتائج في متغير "y_pred".
![]()
الخطوة السادسة: مقارنة القيم الحقيقية بالقيم المتنبأ بها
هذه خطوة بسيطة أخرى ، حيث سنقوم ببناء إطار بيانات بسيط آخر يتكون من عمودين ، والقيم الحقيقية لمجموعة الاختبار من جانب والقيم المتوقعة على الجانب الآخر. تمكننا هذه الخطوة من مقارنة النتائج التي تم الحصول عليها بواسطة النموذج المبني.
![]()
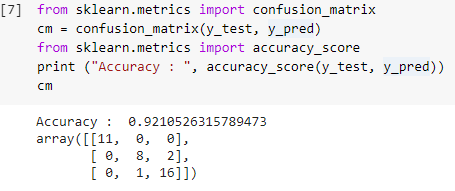
الخطوة 7: مصفوفة الارتباك والدقة
الآن بعد أن أصبح لدينا القيم الحقيقية والمتوقعة لمجموعات الاختبار ، دعونا نبني مصفوفة تصنيف بسيطة ونحسب دقة نموذجنا المبني باستخدام وظائف المكتبة البسيطة داخل sklearn. يتم حساب درجة الدقة عن طريق إدخال القيم الحقيقية والمتوقعة لمجموعة الاختبار. يمنحنا النموذج الذي تم إنشاؤه باستخدام الخطوات المذكورة أعلاه دقة تبلغ 92.1٪ والتي يُشار إليها بـ 0.92105 في الخطوة أدناه.
مصفوفة الارتباك عبارة عن جدول يستخدم لإظهار التنبؤات الصحيحة وغير الصحيحة حول مشكلة التصنيف. للاستخدام البسيط ، تمثل القيم عبر القطر التنبؤات الصحيحة والقيم الأخرى خارج القطر تمثل تنبؤات غير صحيحة.
عند حساب العدد من 38 نقطة بيانات مجموعة اختبار ، نحصل على 35 تنبؤًا صحيحًا و 3 تنبؤات غير صحيحة ، والتي تنعكس بدقة 92٪. يمكن تحسين الدقة عن طريق تحسين المعلمات الفائقة التي يمكن تقديمها كوسيطات للمصنف قبل تدريب النموذج.
الخطوة 8: تصور مصنف شجرة القرار
أخيرًا ، في الخطوة الأخيرة ، يجب أن نتخيل بناء شجرة القرار. عند ملاحظة عقدة الجذر ، يتضح أن عدد "العينات" هو 112 ، والتي تكون متزامنة مع عينات مجموعة التدريب التي تم تقسيمها من قبل. يتم حساب مؤشر GINI أثناء كل خطوة من خوارزمية شجرة القرار ويتم تقسيم الفئات الثلاث كما هو موضح في معلمة "القيمة" في شجرة القرار.

يجب أن تقرأ: أسئلة وأجوبة مقابلة شجرة القرار
خاتمة
ومن ثم ، بهذه الطريقة ، فهمنا مفهوم خوارزمية شجرة القرار وقمنا ببناء مصنف بسيط لحل مشكلة التصنيف باستخدام هذه الخوارزمية.
إذا كنت مهتمًا بمعرفة المزيد عن أشجار القرار ، والتعلم الآلي ، فراجع IIIT-B & upGrad's دبلوم PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، حالة خريجي IIIT-B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع كبرى الشركات.
ما هي سلبيات استخدام أشجار القرار؟
بينما تساعد أشجار القرار في تصنيف البيانات أو فرزها ، يؤدي استخدامها أحيانًا إلى حدوث بعض المشاكل أيضًا. في كثير من الأحيان ، تؤدي أشجار القرار إلى الإفراط في تجهيز البيانات ، مما يجعل النتيجة النهائية غير دقيقة للغاية. في حالة مجموعات البيانات الكبيرة ، لا يوصى باستخدام شجرة قرار واحدة لأنها تسبب التعقيد. أيضًا ، تعتبر أشجار القرار غير مستقرة إلى حد كبير ، مما يعني أنه إذا أحدثت تغييرًا بسيطًا في مجموعة البيانات المحددة ، فإن هيكل شجرة القرار يتغير بشكل كبير.
كيف تعمل خوارزمية الغابة العشوائية؟
الغابة العشوائية هي في الأساس مجموعة من أشجار القرار المتنوعة ، تمامًا مثل الغابة التي تتكون من العديد من الأشجار. تعتمد نتائج خوارزمية الغابة العشوائية في الواقع على تنبؤات أشجار القرار. تقلل تقنية الغابة العشوائية أيضًا من احتمالية الإفراط في ملاءمة البيانات. للحصول على النتيجة المطلوبة ، يستخدم التصنيف العشوائي للغابات نهج المجموعة. يتم استخدام بيانات التدريب لتدريب أشجار القرار المختلفة. عند فصل العقد ، تحتوي مجموعة البيانات هذه على ملاحظات وسمات سيتم انتقاؤها عشوائيًا.
كيف يختلف جدول القرار عن شجرة القرار؟
قد يتم إنتاج جدول القرار من شجرة القرار ، ولكن ليس العكس. تتكون شجرة القرار من عقد وفروع ، بينما يتكون جدول القرار من صفوف وأعمدة. في جداول القرار ، يمكن إدراج أكثر من شرط أو شرط. في أشجار القرار ، هذا ليس هو الحال. تكون جداول القرار مفيدة فقط عند تقديم عدد قليل من الخصائص ؛ من ناحية أخرى ، يمكن استخدام أشجار القرار بشكل فعال مع عدد كبير من الخصائص والمنطق المعقد.