
Przykład drzewa decyzyjnego: funkcja i implementacja [krok po kroku]
Opublikowany: 2020-12-28Spis treści
Wstęp
Drzewa decyzyjne to jeden z najpotężniejszych i najpopularniejszych algorytmów zarówno do zadań regresji, jak i klasyfikacji. Mają one strukturę podobną do schematu blokowego i należą do kategorii algorytmów nadzorowanych. Możliwość wizualizacji drzew decyzyjnych jako schematu blokowego umożliwia im łatwe naśladowanie poziomu myślenia ludzi i to jest powód, dla którego te drzewa decyzyjne są łatwe do zrozumienia i interpretacji.
Co to jest drzewo decyzyjne?
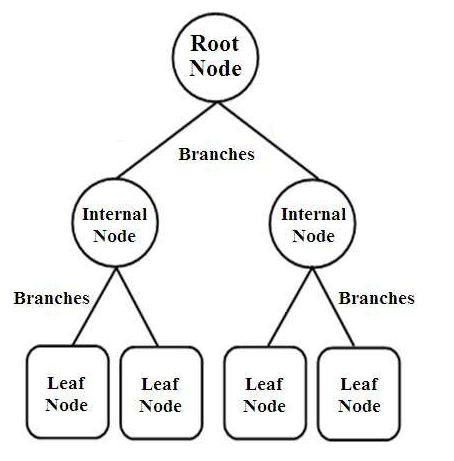
Drzewa decyzyjne to rodzaj klasyfikatorów o strukturze drzewa. Mają trzy rodzaje węzłów, które są,
- Węzły główne
- Węzły wewnętrzne
- Węzły liściowe
Źródło obrazu
Węzły główne to węzły podstawowe reprezentujące całą próbkę, która jest dalej podzielona na kilka innych węzłów. Węzły wewnętrzne reprezentują test na atrybucie, podczas gdy gałęzie reprezentują decyzję testu. Wreszcie węzły liści oznaczają klasę etykiety, która jest decyzją podjętą po skompilowaniu wszystkich atrybutów. Dowiedz się więcej o uczeniu się drzewa decyzyjnego.
Jak działają drzewa decyzyjne?
Drzewa decyzyjne są używane w klasyfikacji poprzez sortowanie ich w dół całej struktury drzewa od węzła głównego do węzła liścia. To podejście używane przez drzewo decyzyjne nazywa się podejściem odgórnym. Gdy określony punkt danych zostanie wprowadzony do drzewa decyzyjnego, przechodzi on przez każdy węzeł drzewa, odpowiadając na pytania Tak/Nie, aż dotrze do określonego wyznaczonego węzła liścia.
Każdy węzeł w drzewie decyzyjnym reprezentuje przypadek testowy dla atrybutu, a każde zejście (gałąź) do nowego węzła odpowiada jednej z możliwych odpowiedzi na ten przypadek testowy. W ten sposób w przypadku wielu iteracji drzewo decyzyjne przewiduje wartość zadania regresji lub klasyfikuje obiekt w zadaniu klasyfikacji.

Implementacja drzewa decyzyjnego
Teraz, gdy znamy już podstawy drzewa decyzyjnego, przejdźmy przez jego wykonanie w programowaniu w Pythonie.
Analiza problemu
W poniższym przykładzie użyjemy słynnego zestawu danych „Iris Flower”. Pierwotnie opublikowany w 1936 r. w UCI Machine Learning Repository (Link: https://archive.ics.uci.edu/ml/datasets/Iris ), ten mały zestaw danych jest szeroko stosowany do testowania algorytmów uczenia maszynowego i wizualizacji.
W tym jest w sumie 150 wierszy i 5 kolumn, z których 4 kolumny to atrybuty lub cechy, a ostatnia kolumna to rodzaj gatunku kwiatu tęczówki. Iris to rodzaj roślin kwitnących w botanice. Cztery atrybuty w cm to:
- Długość działki
- Szerokość działki
- Długość płatka
- Szerokość płatka
Te cztery cechy są używane do definiowania i klasyfikowania rodzaju kwiatu tęczówki w zależności od wielkości i kształtu. Piąta lub ostatnia kolumna składa się z klasy kwiatów Iris, którymi są Iris Setosa, Iris Versicolor i Iris Virginica .
W przypadku naszego problemu musimy zbudować model uczenia maszynowego wykorzystujący algorytm drzewa decyzyjnego, aby poznać funkcje i sklasyfikować je na podstawie klasy kwiatu tęczówki.
Przejdźmy przez jego implementację w Pythonie, krok po kroku:
Krok 1: Importowanie bibliotek
Pierwszym krokiem w budowaniu dowolnego modelu uczenia maszynowego w Pythonie będzie zaimportowanie niezbędnych bibliotek, takich jak Numpy, Pandas i Matplotlib. Moduł drzewa jest importowany z biblioteki sklearn, aby na końcu zwizualizować model drzewa decyzyjnego.
Krok 2: Importowanie zbioru danych
Po zaimportowaniu zestawu danych Iris przechowujemy plik .csv w Pandas DataFrame, z którego możemy łatwo uzyskać dostęp do kolumn i wierszy tabeli. Pierwsze cztery kolumny ramki danych to zmienne niezależne lub cechy, które mają być rozumiane przez klasyfikator drzewa decyzyjnego i są przechowywane w zmiennej X.
Zmienna zależna, którą jest klasa kwiatów irysa składająca się z 3 gatunków, jest przechowywana w zmiennej y. Zestaw danych jest wizualizowany poprzez wydrukowanie pierwszych 5 wierszy.

Przeczytaj także: Klasyfikacja drzewa decyzyjnego
Krok 3: Dzielenie zbioru danych na zbiór treningowy i zbiór testowy
W kolejnym kroku, po odczytaniu zestawu danych, musimy podzielić cały zestaw danych na zestaw uczący, za pomocą którego zostanie przeszkolony model klasyfikatora oraz zestaw testowy, na którym zostanie zaimplementowany uczony model. Wyniki uzyskane na zbiorze testowym zostaną porównane w celu sprawdzenia dokładności wytrenowanego modelu.

W tym przypadku użyliśmy rozmiaru testu 0,25, co oznacza, że 25% całego zbioru danych zostanie losowo podzielonych jako zbiór testowy, a pozostałe 75% będzie składać się ze zbioru uczącego, który ma być użyty w uczeniu modelu. W związku z tym ze 150 punktów danych 38 losowych punktów danych jest zachowywanych jako zestaw testowy, a pozostałe 112 próbek jest używanych w zestawie uczącym.

Krok 4: Uczenie modelu klasyfikacji drzew decyzyjnych w zestawie uczącym
Gdy model zostanie podzielony i jest gotowy do celów szkoleniowych, moduł DecisionTreeClassifier jest importowany z biblioteki sklearn, a zmienne szkoleniowe (X_train i y_train) są dopasowywane do klasyfikatora w celu zbudowania modelu. Podczas tego procesu szkoleniowego klasyfikator przechodzi kilka metod optymalizacji, takich jak Gradient Descent i Backpropagation, a ostatecznie buduje model klasyfikatora drzewa decyzyjnego.

Krok 5: Przewidywanie wyników zestawu testowego
Skoro mamy gotowy model, czy nie powinniśmy sprawdzić jego dokładności na zestawie testowym? Ten krok obejmuje testowanie modelu zbudowanego za pomocą algorytmu drzewa decyzyjnego na zestawie testowym, który został wcześniej podzielony. Wyniki te są przechowywane w zmiennej „y_pred”.
![]()
Krok 6: Porównanie wartości rzeczywistych z przewidywanymi
To kolejny prosty krok, w którym zbudujemy kolejną prostą ramkę danych, która będzie składać się z dwóch kolumn, z jednej strony wartości rzeczywistych zestawu testowego, a z drugiej wartości przewidywanych. Ten krok umożliwia nam porównanie wyników uzyskanych przez zbudowany model.
![]()
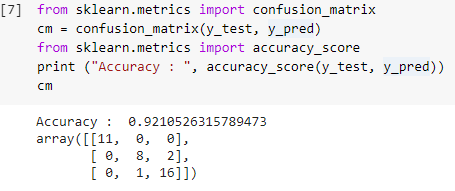
Krok 7: Macierz pomyłek i dokładność
Teraz, gdy mamy zarówno rzeczywiste, jak i przewidywane wartości zbiorów testowych, zbudujmy prostą macierz klasyfikacji i obliczmy dokładność naszego modelu zbudowanego przy użyciu prostych funkcji bibliotecznych w sklearn. Wynik dokładności jest obliczany przez wprowadzenie zarówno rzeczywistych, jak i przewidywanych wartości zestawu testowego. Model zbudowany przy użyciu powyższych kroków daje nam dokładność 92,1%, co w kroku poniżej oznaczono jako 0,92105.
Macierz pomyłek to tabela, która służy do pokazywania poprawnych i niepoprawnych prognoz dotyczących problemu klasyfikacji. Dla uproszczenia, wartości na przekątnej reprezentują prawidłowe przewidywania, a inne wartości poza przekątną są niepoprawnymi przewidywaniami.
Obliczając liczbę z 38 punktów danych zestawu testowego, otrzymujemy 35 poprawnych prognoz i 3 nieprawidłowe prognozy, które są odzwierciedlone jako 92% trafne. Dokładność można poprawić, optymalizując hiperparametry, które można podać jako argumenty klasyfikatorowi przed uczeniem modelu.
Krok 8: Wizualizacja klasyfikatora drzewa decyzyjnego
Na koniec w ostatnim kroku zwizualizujemy zbudowane Drzewo Decyzyjne. Po zauważeniu węzła głównego można zauważyć, że liczba „próbek” wynosi 112, co jest zsynchronizowane z wcześniej podzielonymi próbkami zestawu uczącego. Indeks GINI jest obliczany na każdym kroku algorytmu drzewa decyzyjnego, a 3 klasy są dzielone, jak pokazano w parametrze „value” w drzewie decyzyjnym.

Trzeba przeczytać: Pytania i odpowiedzi dotyczące drzewa decyzyjnego podczas rozmowy kwalifikacyjnej
Wniosek
Dlatego w ten sposób zrozumieliśmy pojęcie algorytmu drzewa decyzyjnego i zbudowaliśmy prosty klasyfikator, aby rozwiązać problem klasyfikacji przy użyciu tego algorytmu.
Jeśli chcesz dowiedzieć się więcej o drzewach decyzyjnych, uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań , status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jakie są wady korzystania z drzew decyzyjnych?
Chociaż drzewa decyzyjne pomagają w klasyfikacji lub sortowaniu danych, ich użycie czasami stwarza również kilka problemów. Często drzewa decyzyjne prowadzą do nadmiernego dopasowania danych, co dodatkowo sprawia, że ostateczny wynik jest bardzo niedokładny. W przypadku dużych zbiorów danych nie zaleca się stosowania pojedynczego drzewa decyzyjnego, ponieważ powoduje to złożoność. Ponadto drzewa decyzyjne są wysoce niestabilne, co oznacza, że jeśli wprowadzisz niewielką zmianę w danym zbiorze danych, struktura drzewa decyzyjnego bardzo się zmieni.
Jak działa algorytm losowego lasu?
Losowy las jest zasadniczo zbiorem różnorodnych drzew decyzyjnych, tak jak las składa się z wielu drzew. Wyniki algorytmu losowego lasu są w rzeczywistości zależne od przewidywań drzew decyzyjnych. Technika losowego lasu również minimalizuje prawdopodobieństwo nadmiernego dopasowania danych. Aby uzyskać wymagany wynik, losowa klasyfikacja lasów wykorzystuje podejście zespołowe. Dane treningowe są wykorzystywane do trenowania różnych drzew decyzyjnych. Gdy węzły są rozdzielone, ten zbiór danych zawiera obserwacje i atrybuty, które będą wybierane losowo.
Czym różni się tabela decyzyjna od drzewa decyzyjnego?
Tablicę decyzyjną można utworzyć z drzewa decyzyjnego, ale nie na odwrót. Drzewo decyzyjne składa się z węzłów i gałęzi, podczas gdy tabela decyzyjna składa się z wierszy i kolumn. W tabelach decyzyjnych można wstawić więcej niż jeden warunek. W drzewach decyzyjnych tak nie jest. Tabele decyzyjne są przydatne tylko wtedy, gdy prezentowanych jest tylko kilka właściwości; Z drugiej strony drzewa decyzyjne mogą być skutecznie wykorzystywane z dużą liczbą właściwości i wyrafinowaną logiką.