
Exemplo de árvore de decisão: função e implementação [passo a passo]
Publicados: 2020-12-28Índice
Introdução
As Árvores de Decisão são um dos algoritmos mais poderosos e populares para tarefas de regressão e classificação. Eles são um fluxograma como estrutura e se enquadram na categoria de algoritmos supervisionados. A capacidade das árvores de decisão de serem visualizadas como um fluxograma permite que elas imitem facilmente o nível de pensamento dos humanos e esta é a razão pela qual essas árvores de decisão são facilmente compreendidas e interpretadas.
O que é uma árvore de decisão?
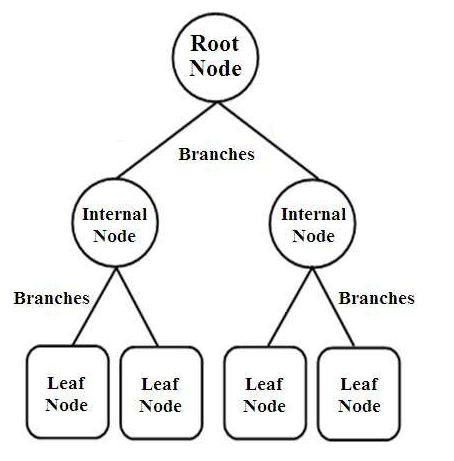
Árvores de decisão são um tipo de classificador estruturado em árvore. Eles têm três tipos de nós que são,
- Nós Raiz
- Nós internos
- Nós Folha
Fonte da imagem
Os nós Raiz são os nós primários que representam toda a amostra que é dividida em vários outros nós. Os nós internos representam o teste em um atributo enquanto os ramos representam a decisão do teste. Por fim, os nós folha denotam a classe do rótulo, que é a decisão tomada após a compilação de todos os atributos. Saiba mais sobre o aprendizado da árvore de decisão.
Como funcionam as Árvores de Decisão?
As árvores de decisão são usadas na classificação classificando-as em toda a estrutura da árvore, do nó raiz até o nó folha. Essa abordagem usada pela árvore de decisão é chamada de abordagem Top-Down. Uma vez que um determinado ponto de dados é alimentado na árvore de decisão, ele é feito para passar por cada nó da árvore respondendo a perguntas Sim/Não até atingir o nó folha específico designado.
Cada nó na árvore de decisão representa um caso de teste para um atributo e cada descida (ramificação) para um novo nó corresponde a uma das possíveis respostas para aquele caso de teste. Dessa forma, com várias iterações, a árvore de decisão prevê um valor para a tarefa de regressão ou classifica o objeto em uma tarefa de classificação.

Implementação da Árvore de Decisão
Agora que temos o básico de uma árvore de decisão, vamos passar por sua execução na programação Python.
Analise de problemas
No exemplo a seguir vamos usar o famoso Dataset “Iris Flower”. Originalmente publicado em 1936 no UCI Machine Learning Repository, (Link: https://archive.ics.uci.edu/ml/datasets/Iris ), este pequeno conjunto de dados é amplamente usado para testar algoritmos e visualizações de aprendizado de máquina.
Neste, há um total de 150 linhas e 5 colunas das quais 4 colunas são os atributos ou características e a última coluna é o tipo de espécie de flor íris. Iris é um gênero de plantas com flores em botânica. Os quatro atributos em cm são,
- Comprimento da Sépala
- Largura da Sépala
- Comprimento da pétala
- Largura da pétala
Esses quatro recursos são usados para definir e classificar o tipo de flor de íris, dependendo do tamanho e da forma. A 5ª ou última coluna consiste na classe de flores Iris, que são Iris Setosa, Iris Versicolor e Iris Virginica .
Para o nosso problema, temos que construir um modelo de Machine Learning utilizando o algoritmo de árvore de decisão para aprender os recursos e classificá-los com base na classe flor Iris.
Vamos passar por sua implementação em python, passo a passo:
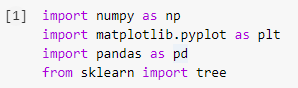
Etapa 1: importando as bibliotecas
O primeiro passo na construção de qualquer modelo de aprendizado de máquina em Python será importar as bibliotecas necessárias, como Numpy, Pandas e Matplotlib. O módulo de árvore é importado da biblioteca sklearn para visualizar o modelo de Árvore de Decisão ao final.
Etapa 2: importar o conjunto de dados
Depois de importar o conjunto de dados Iris, armazenamos o arquivo .csv em um Pandas DataFrame a partir do qual podemos acessar facilmente as colunas e linhas da tabela. As primeiras quatro colunas do dataframe são as variáveis independentes ou os recursos que devem ser entendidos pelo classificador da árvore de decisão e são armazenados na variável X.
A variável dependente que é a classe de flores Iris composta por 3 espécies é armazenada na variável y. O conjunto de dados é visualizado imprimindo as primeiras 5 linhas.

Leia também: Classificação da árvore de decisão
Etapa 3: dividir o conjunto de dados em conjunto de treinamento e conjunto de teste
Na etapa seguinte, após a leitura do conjunto de dados, temos que dividir todo o conjunto de dados no conjunto de treinamento, usando o qual o modelo classificador será treinado e o conjunto de teste, no qual o modelo treinado será implementado. Os resultados obtidos no conjunto de teste serão comparados para verificar a precisão do modelo treinado.

Aqui, usamos um tamanho de teste de 0,25, o que denota que 25% de todo o conjunto de dados será dividido aleatoriamente como o conjunto de teste e os 75% restantes consistirão no conjunto de treinamento a ser usado no treinamento do modelo. Assim, de 150 pontos de dados, 38 pontos de dados aleatórios são retidos como o conjunto de teste e as 112 amostras restantes são usadas no conjunto de treinamento.

Etapa 4: Treinar o modelo de Classificação da Árvore de Decisão no Conjunto de Treinamento
Uma vez que o modelo foi dividido e está pronto para fins de treinamento, o módulo DecisionTreeClassifier é importado da biblioteca sklearn e as variáveis de treinamento (X_train e y_train) são ajustadas no classificador para construir o modelo. Durante este processo de treinamento, o classificador passa por diversos métodos de otimização como o Gradient Descent e Backpropagation e finalmente constrói o modelo do Classificador de Árvore de Decisão.

Etapa 5: Previsão dos resultados do conjunto de testes
Como temos nosso modelo pronto, não deveríamos verificar sua precisão no conjunto de teste? Esta etapa envolve o teste do modelo construído usando o algoritmo de árvore de decisão no conjunto de teste que foi dividido anteriormente. Esses resultados são armazenados em uma variável, “y_pred”.
![]()
Etapa 6: Comparando os valores reais com os valores previstos
Este é outro passo simples, onde construiremos outro dataframe simples que consistirá em duas colunas, os valores reais do conjunto de teste de um lado e os valores previstos do outro lado. Esta etapa permite comparar os resultados obtidos pelo modelo construído.
![]()
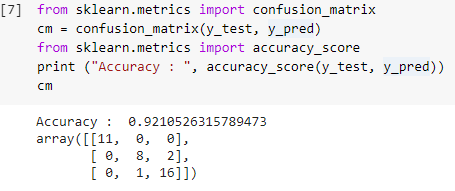
Etapa 7: Matriz de confusão e precisão
Agora que temos os valores reais e previstos dos conjuntos de teste, vamos construir uma matriz de classificação simples e calcular a precisão do nosso modelo construído usando funções de biblioteca simples dentro do sklearn. A pontuação de precisão é calculada inserindo os valores reais e previstos do conjunto de teste. O modelo construído usando as etapas acima nos dá uma precisão de 92,1% que é denotada como 0,92105 na etapa abaixo.
A matriz de confusão é uma tabela usada para mostrar as previsões corretas e incorretas em um problema de classificação. Para uso simples, os valores na diagonal representam as previsões corretas e os outros valores fora da diagonal são previsões incorretas.
Ao calcular o número de 38 pontos de dados do conjunto de teste, obtemos 35 previsões corretas e 3 previsões incorretas, que são refletidas como 92% precisas. A precisão pode ser melhorada otimizando os hiperparâmetros que podem ser dados como argumentos ao classificador antes de treinar o modelo.
Etapa 8: Visualizando o classificador da árvore de decisão
Por fim, na última etapa visualizaremos a Árvore de Decisão construída. Ao perceber o nó raiz, percebe-se que o número de “amostras” são 112, que estão em sincronia com as amostras do conjunto de treinamento divididas anteriormente. O índice GINI é calculado durante cada passo do algoritmo da árvore de decisão e as 3 classes são divididas conforme mostrado no parâmetro “valor” na árvore de decisão.

Deve ler: Perguntas e respostas da entrevista da árvore de decisão
Conclusão
Assim, desta forma, entendemos o conceito de algoritmo Árvore de Decisão e construímos um Classificador simples para resolver um problema de classificação usando este algoritmo.
Se você estiver interessado em saber mais sobre árvores de decisão, aprendizado de máquina, confira o Diploma PG do IIIT-B e do upGrad em aprendizado de máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições , IIIT-B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Quais são os contras de usar árvores de decisão?
Embora as árvores de decisão ajudem na classificação ou classificação de dados, seu uso às vezes também cria alguns problemas. Muitas vezes, as árvores de decisão levam ao overfitting dos dados, o que torna o resultado final altamente impreciso. No caso de grandes conjuntos de dados, o uso de uma única árvore de decisão não é recomendado porque causa complexidade. Além disso, as árvores de decisão são altamente instáveis, o que significa que, se você causar uma pequena alteração no conjunto de dados fornecido, a estrutura da árvore de decisão muda muito.
Como funciona um algoritmo de floresta aleatória?
Uma floresta aleatória é essencialmente uma coleção de diversas árvores de decisão, assim como uma floresta é composta de muitas árvores. Os resultados do algoritmo de floresta aleatória são, na verdade, dependentes das previsões das árvores de decisão. A técnica de floresta aleatória também minimiza a probabilidade de ajuste excessivo de dados. Para obter o resultado necessário, a classificação de floresta aleatória emprega uma abordagem de conjunto. Os dados de treinamento são usados para treinar várias árvores de decisão. Quando os nós são separados, esse conjunto de dados contém observações e atributos que serão escolhidos aleatoriamente.
Como uma tabela de decisão é diferente de uma árvore de decisão?
Uma tabela de decisão pode ser produzida a partir de uma árvore de decisão, mas não o contrário. Uma árvore de decisão é composta de nós e ramos, enquanto uma tabela de decisão é composta de linhas e colunas. Nas tabelas de decisão, mais de uma condição ou pode ser inserida. Em árvores de decisão, este não é o caso. As tabelas de decisão só são úteis quando apenas algumas propriedades são apresentadas; As árvores de decisão, por outro lado, podem ser usadas efetivamente com um grande número de propriedades e lógica sofisticada.