
ตัวอย่างแผนผังการตัดสินใจ: ฟังก์ชัน & การนำไปใช้ [ทีละขั้นตอน]
เผยแพร่แล้ว: 2020-12-28สารบัญ
บทนำ
Decision Trees เป็นหนึ่งในอัลกอริธึมที่ทรงพลังและได้รับความนิยมมากที่สุดสำหรับงานถดถอยและการจัดหมวดหมู่ พวกเขาเป็นผังงานเหมือนโครงสร้างและอยู่ภายใต้หมวดหมู่ของอัลกอริธึมภายใต้การดูแล ความสามารถของแผนผังการตัดสินใจที่มองเห็นได้เหมือนกับแผนผังลำดับงานช่วยให้สามารถเลียนแบบระดับการคิดของมนุษย์ได้อย่างง่ายดาย และนี่คือเหตุผลที่ว่าทำไมแผนผังการตัดสินใจเหล่านี้จึงเข้าใจและตีความได้ง่าย
ต้นไม้การตัดสินใจคืออะไร?
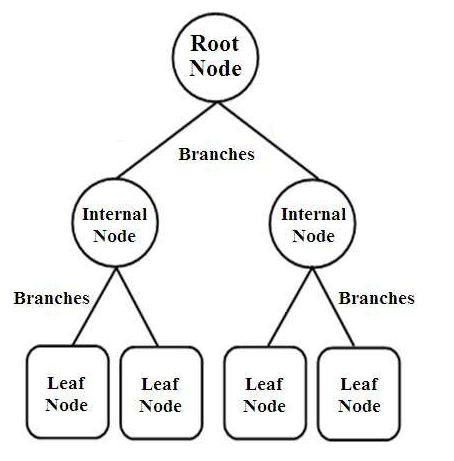
Decision Trees เป็นประเภทของตัวแยกประเภทที่มีโครงสร้างเป็นต้นไม้ มีโหนดสามประเภทคือ
- โหนดราก
- โหนดภายใน
- โหนดใบ
ที่มาของภาพ
โหนดรูทเป็นโหนดหลักที่แสดงตัวอย่างทั้งหมด ซึ่งถูกแยกออกเป็นโหนดอื่นๆ อีกหลายโหนด โหนดภายในแสดงถึงการทดสอบในแอตทริบิวต์ในขณะที่สาขาแสดงถึงการตัดสินใจของการทดสอบ สุดท้าย โหนดปลายสุดแสดงถึงคลาสของป้ายกำกับ ซึ่งเป็นการตัดสินใจหลังจากการรวบรวมแอตทริบิวต์ทั้งหมด เรียนรู้เพิ่มเติมเกี่ยวกับการเรียนรู้แผนผังการตัดสินใจ
ต้นไม้การตัดสินใจทำงานอย่างไร
ต้นไม้ตัดสินใจใช้ในการจำแนกประเภทโดยเรียงลำดับโครงสร้างต้นไม้ทั้งหมดจากโหนดรากไปยังโหนดใบ แนวทางนี้ใช้โดยแผนผังการตัดสินใจเรียกว่าวิธีการจากบนลงล่าง เมื่อจุดข้อมูลใดจุดหนึ่งถูกป้อนเข้าไปในแผนผังการตัดสินใจ จุดข้อมูลนั้นจะต้องผ่านแต่ละโหนดของทรีด้วยการตอบคำถามใช่/ไม่ใช่จนกว่าจะถึงโหนดปลายสุดที่กำหนด
แต่ละโหนดในแผนผังการตัดสินใจแสดงถึงกรณีทดสอบสำหรับแอตทริบิวต์ และแต่ละโหนด (สาขา) ไปยังโหนดใหม่จะสอดคล้องกับหนึ่งในคำตอบที่เป็นไปได้สำหรับกรณีทดสอบนั้น ด้วยวิธีนี้ ด้วยการวนซ้ำหลายครั้ง ต้นไม้การตัดสินใจจะทำนายค่าสำหรับงานถดถอยหรือจัดประเภทวัตถุในงานจำแนกประเภท

การดำเนินการต้นไม้การตัดสินใจ
ตอนนี้เรามีพื้นฐานของโครงสร้างการตัดสินใจแล้ว ให้เราดำเนินการต่อไปในการเขียนโปรแกรม Python
การวิเคราะห์ปัญหา
ในตัวอย่างต่อไปนี้ เราจะใช้ชุดข้อมูล “Iris Flower” ที่มีชื่อเสียง เผยแพร่ครั้งแรกในปี 1936 ที่ UCI Machine Learning Repository (ลิงก์: https://archive.ics.uci.edu/ml/datasets/Iris ) ชุดข้อมูลขนาดเล็กนี้ใช้กันอย่างแพร่หลายสำหรับการทดสอบอัลกอริธึมการเรียนรู้ของเครื่องและการแสดงภาพ
ในนี้มีทั้งหมด 150 แถว 5 คอลัมน์ โดย 4 คอลัมน์เป็นคุณลักษณะหรือคุณลักษณะ และคอลัมน์สุดท้ายเป็นชนิดพันธุ์ดอกไอริส ไอริสเป็นพืชสกุลไม้ดอกในพฤกษศาสตร์ คุณลักษณะสี่ประการในหน่วยซมคือ
- ความยาวของ Sepal
- ความกว้างของ Sepal
- ความยาวของกลีบดอก
- ความกว้างของกลีบดอก
คุณลักษณะทั้งสี่นี้ใช้เพื่อกำหนดและจำแนกประเภทของดอกไอริสตามขนาดและรูปร่าง คอลัมน์ ที่ 5 หรือคอลัมน์สุดท้ายประกอบด้วยชั้นดอกไอริส ได้แก่ Iris Setosa, Iris Versicolor และ Iris Virginica
สำหรับปัญหาของเรา เราต้องสร้างโมเดล Machine Learning โดยใช้ Decision Tree Algorithm เพื่อเรียนรู้คุณสมบัติและจำแนกตามคลาสดอกไอริส
ให้เราดำเนินการใช้งานใน python ทีละขั้นตอน:
ขั้นตอนที่ 1: การนำเข้าไลบรารี
ขั้นตอนแรกในการสร้างโมเดลแมชชีนเลิร์นนิงใน Python คือการนำเข้าไลบรารีที่จำเป็น เช่น Numpy, Pandas และ Matplotlib โมดูลทรีถูกนำเข้าจากไลบรารี sklearn เพื่อแสดงภาพโมเดลทรีการตัดสินใจในตอนท้าย
ขั้นตอนที่ 2: การนำเข้าชุดข้อมูล
เมื่อเรานำเข้าชุดข้อมูล Iris แล้ว เราจะเก็บไฟล์ .csv ไว้ใน Pandas DataFrame ซึ่งเราสามารถเข้าถึงคอลัมน์และแถวของตารางได้อย่างง่ายดาย สี่คอลัมน์แรกของ dataframe เป็นตัวแปรอิสระหรือคุณลักษณะที่ตัวแยกประเภทการตัดสินใจจะเข้าใจและถูกเก็บไว้ในตัวแปร X
ตัวแปรตามซึ่งเป็นชั้นดอกไอริสประกอบด้วย 3 สายพันธุ์ถูกเก็บไว้ในตัวแปร y ชุดข้อมูลแสดงให้เห็นโดยการพิมพ์ 5 แถวแรก

อ่านเพิ่มเติม: การจำแนกต้นไม้การตัดสินใจ
ขั้นตอนที่ 3: แยกชุดข้อมูลออกเป็นชุดการฝึกและชุดทดสอบ
ในขั้นตอนต่อไปนี้ หลังจากอ่านชุดข้อมูลแล้ว เราต้องแยกชุดข้อมูลทั้งหมดออกเป็นชุดการฝึก โดยใช้แบบจำลองตัวแยกประเภทที่ได้รับการฝึกและชุดทดสอบ ซึ่งจะนำแบบจำลองที่ได้รับการฝึกไปใช้ ผลลัพธ์ที่ได้จากชุดทดสอบจะถูกเปรียบเทียบเพื่อตรวจสอบความถูกต้องของแบบจำลองที่ได้รับการฝึกอบรม

ในที่นี้ เราใช้ขนาดการทดสอบ 0.25 ซึ่งแสดงว่า 25% ของชุดข้อมูลทั้งหมดจะถูกสุ่มแยกเป็นชุดทดสอบ และอีก 75% ที่เหลือจะประกอบด้วยชุดการฝึกที่จะใช้ในการฝึกโมเดล ดังนั้น จากจุดข้อมูล 150 จุด จุดข้อมูลสุ่ม 38 จุดจะถูกเก็บไว้เป็นชุดทดสอบ และส่วนที่เหลืออีก 112 ตัวอย่างจะถูกใช้ในชุดการฝึก

ขั้นตอนที่ 4: ฝึกอบรมแบบจำลองการจัดลำดับต้นไม้การตัดสินใจในชุดการฝึก
เมื่อโมเดลถูกแยกออกและพร้อมสำหรับการฝึกอบรมแล้ว โมดูล DecisionTreeClassifier จะถูกนำเข้าจากไลบรารี sklearn และตัวแปรการฝึกอบรม (X_train และ y_train) จะถูกติดตั้งบนตัวแยกประเภทเพื่อสร้างโมเดล ในระหว่างกระบวนการฝึกอบรมนี้ ตัวแยกประเภทจะผ่านวิธีการเพิ่มประสิทธิภาพหลายวิธี เช่น Gradient Descent และ Backpropagation และในที่สุดก็สร้างแบบจำลอง Decision Tree Classifier

ขั้นตอนที่ 5: การทำนายผลชุดทดสอบ
เนื่องจากเรามีแบบจำลองของเราพร้อมแล้ว เราควรตรวจสอบความถูกต้องของชุดทดสอบหรือไม่ ขั้นตอนนี้เกี่ยวข้องกับการทดสอบโมเดลที่สร้างขึ้นโดยใช้อัลกอริธึมทรีการตัดสินใจในชุดการทดสอบที่แยกออกมาก่อนหน้านี้ ผลลัพธ์เหล่านี้ถูกเก็บไว้ในตัวแปร “y_pred”
![]()
ขั้นตอนที่ 6: การเปรียบเทียบมูลค่าจริงกับค่าที่คาดการณ์
นี่เป็นขั้นตอนง่ายๆ อีกขั้นตอนหนึ่ง ซึ่งเราจะสร้าง dataframe แบบง่ายอีกอันซึ่งจะประกอบด้วยสองคอลัมน์ ค่าจริงของชุดการทดสอบที่ด้านหนึ่ง และค่าที่คาดการณ์ไว้อีกด้านหนึ่ง ขั้นตอนนี้ช่วยให้เราสามารถเปรียบเทียบผลลัพธ์ที่ได้จากแบบจำลองที่สร้างขึ้น
![]()
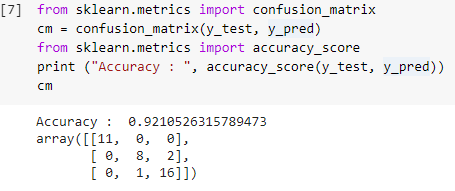
ขั้นตอนที่ 7: เมทริกซ์ความสับสนและความแม่นยำ
ตอนนี้ เรามีทั้งค่าจริงและค่าที่คาดการณ์ไว้ของชุดการทดสอบแล้ว ให้เราสร้างเมทริกซ์การจำแนกประเภทอย่างง่ายและคำนวณความถูกต้องของแบบจำลองของเราที่สร้างขึ้นโดยใช้ฟังก์ชันไลบรารีอย่างง่ายภายใน sklearn คะแนนความแม่นยำคำนวณโดยการป้อนค่าจริงและค่าที่คาดการณ์ไว้ของชุดทดสอบ โมเดลที่สร้างขึ้นโดยใช้ขั้นตอนข้างต้นทำให้เรามีความแม่นยำ 92.1% ซึ่งแสดงเป็น 0.92105 ในขั้นตอนด้านล่าง
เมทริกซ์ความสับสนคือตารางที่ใช้แสดงการคาดคะเนปัญหาการจำแนกประเภทที่ถูกต้องและไม่ถูกต้อง สำหรับการใช้งานอย่างง่าย ค่าในแนวทแยงแสดงถึงการคาดคะเนที่ถูกต้อง และค่าอื่นๆ นอกแนวทแยงเป็นการคาดคะเนที่ไม่ถูกต้อง
ในการคำนวณจำนวนจากจุดข้อมูลชุดทดสอบ 38 จุด เราได้รับการคาดการณ์ที่ถูกต้อง 35 ครั้งและการคาดคะเนที่ไม่ถูกต้อง 3 ครั้ง ซึ่งสะท้อนให้เห็นว่ามีความถูกต้อง 92% สามารถปรับปรุงความแม่นยำได้โดยการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ ซึ่งสามารถกำหนดเป็นอาร์กิวเมนต์ให้กับตัวแยกประเภทก่อนฝึกโมเดล
ขั้นตอนที่ 8: การแสดงภาพ Decision Tree Classifier
สุดท้าย ในขั้นตอนสุดท้าย เราจะเห็นภาพแผนผังการตัดสินใจที่สร้างขึ้น เมื่อสังเกตโหนดรูท จะเห็นว่าจำนวน “ตัวอย่าง” มี 112 รายการ ซึ่งสอดคล้องกับชุดตัวอย่างที่แบ่งก่อน ดัชนี GINI ถูกคำนวณในแต่ละขั้นตอนของอัลกอริทึมแผนผังการตัดสินใจ และแบ่ง 3 คลาสตามที่แสดงในพารามิเตอร์ "ค่า" ในแผนผังการตัดสินใจ

ต้องอ่าน: คำถามและคำตอบในการสัมภาษณ์ต้นไม้ตัดสินใจ
บทสรุป
ดังนั้น ด้วยวิธีนี้ เราจึงเข้าใจแนวคิดของอัลกอริธึม Decision Tree และได้สร้างตัวแยกประเภทอย่างง่ายเพื่อแก้ปัญหาการจำแนกประเภทโดยใช้อัลกอริทึมนี้
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแผนผังการตัดสินใจ แมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ , สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
อะไรคือข้อเสียของการใช้ต้นไม้ตัดสินใจ?
แม้ว่าแผนผังการตัดสินใจจะช่วยในการจัดประเภทหรือจัดเรียงข้อมูล แต่บางครั้งการใช้งานก็สร้างปัญหาบางอย่างได้เช่นกัน บ่อยครั้ง โครงสร้างการตัดสินใจนำไปสู่การใช้ข้อมูลมากเกินไป ซึ่งทำให้ผลลัพธ์สุดท้ายมีความคลาดเคลื่อนอย่างมาก ในกรณีของชุดข้อมูลขนาดใหญ่ ไม่แนะนำให้ใช้แผนผังการตัดสินใจเดียว เนื่องจากจะทำให้เกิดความซับซ้อน นอกจากนี้ แผนผังการตัดสินใจยังมีความไม่เสถียรอย่างมาก ซึ่งหมายความว่าหากคุณทำให้เกิดการเปลี่ยนแปลงเล็กน้อยในชุดข้อมูลที่กำหนด โครงสร้างของแผนผังการตัดสินใจจะเปลี่ยนไปอย่างมาก
อัลกอริทึมฟอเรสต์แบบสุ่มทำงานอย่างไร
ป่าสุ่มเป็นกลุ่มของต้นไม้ตัดสินใจที่หลากหลาย เช่นเดียวกับป่าที่ประกอบด้วยต้นไม้จำนวนมาก ผลลัพธ์ของอัลกอริธึมแบบสุ่มของฟอเรสต์นั้นขึ้นอยู่กับการคาดการณ์ของแผนผังการตัดสินใจ เทคนิคการสุ่มฟอเรสต์ยังช่วยลดโอกาสที่ข้อมูลจะเกินพอดี เพื่อให้ได้ผลลัพธ์ที่ต้องการ การจำแนกประเภทป่าสุ่มใช้วิธีการทั้งมวล ข้อมูลการฝึกอบรมใช้เพื่อฝึกต้นไม้การตัดสินใจต่างๆ เมื่อแยกโหนด ชุดข้อมูลนี้จะมีการสังเกตและแอตทริบิวต์ที่จะสุ่มเลือก
ตารางการตัดสินใจแตกต่างจากแผนผังการตัดสินใจอย่างไร
ตารางการตัดสินใจอาจสร้างจากแผนผังการตัดสินใจ แต่ไม่ใช่ในทางกลับกัน โครงสร้างการตัดสินใจประกอบด้วยโหนดและกิ่งก้าน ในขณะที่ตารางการตัดสินใจประกอบด้วยแถวและคอลัมน์ ในตารางการตัดสินใจ สามารถแทรกได้มากกว่าหนึ่งเงื่อนไขหรือเงื่อนไข ในต้นไม้ตัดสินใจ นี่ไม่ใช่กรณี ตารางการตัดสินใจจะมีประโยชน์ก็ต่อเมื่อมีการนำเสนอคุณสมบัติเพียงไม่กี่อย่างเท่านั้น ในทางกลับกัน ต้นไม้การตัดสินใจสามารถใช้อย่างมีประสิทธิภาพด้วยคุณสมบัติจำนวนมากและตรรกะที่ซับซ้อน