
Ejemplo de árbol de decisiones: función e implementación [paso a paso]
Publicado: 2020-12-28Tabla de contenido
Introducción
Los árboles de decisión son uno de los algoritmos más potentes y populares tanto para tareas de regresión como de clasificación. Son una estructura similar a un diagrama de flujo y entran en la categoría de algoritmos supervisados. La capacidad de los árboles de decisión para visualizarse como un diagrama de flujo les permite imitar fácilmente el nivel de pensamiento de los humanos y esta es la razón por la cual estos árboles de decisión se entienden e interpretan fácilmente.
¿Qué es un árbol de decisión?
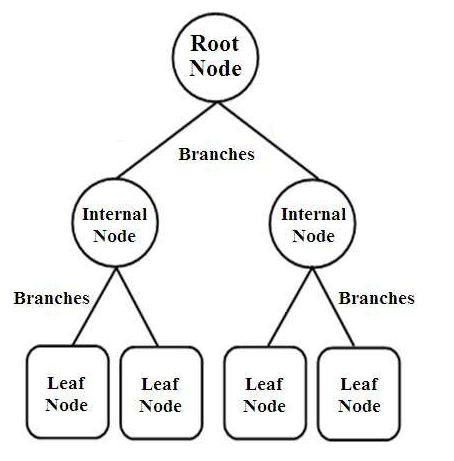
Los árboles de decisión son un tipo de clasificadores estructurados en árbol. Tienen tres tipos de nodos que son,
- Nodos raíz
- Nodos Internos
- Nodos de hoja
Fuente de imagen
Los nodos raíz son los nodos principales que representan la muestra completa, que se divide en varios otros nodos. Los nodos internos representan la prueba sobre un atributo, mientras que las ramas representan la decisión de la prueba. Finalmente, los nodos hoja denotan la clase de la etiqueta, que es la decisión tomada después de la compilación de todos los atributos. Obtenga más información sobre el aprendizaje del árbol de decisiones.
¿Cómo funcionan los árboles de decisión?
Los árboles de decisión se utilizan en la clasificación ordenándolos por toda la estructura del árbol desde el nodo raíz hasta el nodo hoja. Este enfoque utilizado por el árbol de decisiones se denomina enfoque de arriba hacia abajo. Una vez que un punto de datos en particular se introduce en el árbol de decisión, se hace pasar a través de todos y cada uno de los nodos del árbol respondiendo preguntas de Sí/No hasta que llega al nodo de hoja designado en particular.
Cada nodo del árbol de decisión representa un caso de prueba para un atributo y cada descenso (rama) a un nuevo nodo corresponde a una de las posibles respuestas a ese caso de prueba. De esta forma, con múltiples iteraciones, el árbol de decisión predice un valor para la tarea de regresión o clasifica el objeto en una tarea de clasificación.

Implementación del árbol de decisión
Ahora que tenemos los conceptos básicos de un árbol de decisión, repasemos su ejecución en la programación de Python.
Análisis del problema
En el siguiente ejemplo vamos a utilizar el famoso conjunto de datos “Iris Flower”. Publicado originalmente en 1936 en UCI Machine Learning Repository (Enlace: https://archive.ics.uci.edu/ml/datasets/Iris ), este pequeño conjunto de datos se usa ampliamente para probar visualizaciones y algoritmos de aprendizaje automático.
En esto, hay un total de 150 filas y 5 columnas de las cuales 4 columnas son los atributos o características y la última columna es el tipo de especie de flor de Iris. Iris es un género de plantas con flores en botánica. Los cuatro atributos en cm son,
- Longitud del sépalo
- Ancho del sépalo
- Longitud del pétalo
- Ancho del pétalo
Estas cuatro características se utilizan para definir y clasificar el tipo de flor de Iris según el tamaño y la forma. La quinta o última columna consiste en la clase de flores Iris, que son Iris Setosa, Iris Versicolor e Iris Virginica.
Para nuestro problema, tenemos que construir un modelo de aprendizaje automático utilizando el algoritmo del árbol de decisiones para aprender las características y clasificarlas en función de la clase de flor de Iris.
Repasemos su implementación en python, paso a paso:
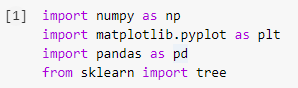
Paso 1: Importación de las bibliotecas
El primer paso para construir cualquier modelo de aprendizaje automático en Python será importar las bibliotecas necesarias, como Numpy, Pandas y Matplotlib. El módulo de árbol se importa de la biblioteca sklearn para visualizar el modelo de árbol de decisiones al final.
Paso 2: Importación del conjunto de datos
Una vez que hemos importado el conjunto de datos de Iris, almacenamos el archivo .csv en un Pandas DataFrame desde el cual podemos acceder fácilmente a las columnas y filas de la tabla. Las primeras cuatro columnas del marco de datos son las variables independientes o las características que debe comprender el clasificador del árbol de decisión y se almacenan en la variable X.
La variable dependiente, que es la clase de flor de Iris que consta de 3 especies, se almacena en la variable y. El conjunto de datos se visualiza imprimiendo las primeras 5 filas.

Lea también: Clasificación del árbol de decisiones
Paso 3: dividir el conjunto de datos en el conjunto de entrenamiento y el conjunto de prueba
En el siguiente paso, después de leer el conjunto de datos, tenemos que dividir todo el conjunto de datos en el conjunto de entrenamiento, con el que se entrenará el modelo clasificador, y el conjunto de prueba, en el que se implementará el modelo entrenado. Los resultados obtenidos en el conjunto de prueba se compararán para verificar la precisión del modelo entrenado.

Aquí, hemos utilizado un tamaño de prueba de 0,25, lo que indica que el 25 % de todo el conjunto de datos se dividirá aleatoriamente como conjunto de prueba y el 75 % restante consistirá en el conjunto de entrenamiento que se usará para entrenar el modelo. Por lo tanto, de 150 puntos de datos, 38 puntos de datos aleatorios se conservan como conjunto de prueba y las 112 muestras restantes se utilizan en el conjunto de entrenamiento.

Paso 4: entrenar el modelo de clasificación del árbol de decisiones en el conjunto de entrenamiento
Una vez que el modelo se ha dividido y está listo para fines de capacitación, el módulo DecisionTreeClassifier se importa de la biblioteca sklearn y las variables de capacitación (X_train e y_train) se ajustan en el clasificador para construir el modelo. Durante este proceso de entrenamiento, el clasificador se somete a varios métodos de optimización, como Gradient Descent y Backpropagation, y finalmente construye el modelo de clasificador de árbol de decisión.

Paso 5: Predicción de los resultados del conjunto de pruebas
Ya que tenemos nuestro modelo listo, ¿no deberíamos verificar su precisión en el conjunto de prueba? Este paso implica la prueba del modelo creado con el algoritmo del árbol de decisión en el conjunto de prueba que se dividió anteriormente. Estos resultados se almacenan en una variable, “y_pred”.
![]()
Paso 6: Comparación de los valores reales con los valores pronosticados
Este es otro paso simple, donde construiremos otro marco de datos simple que constará de dos columnas, los valores reales del conjunto de prueba en un lado y los valores predichos en el otro lado. Este paso nos permite comparar los resultados obtenidos por el modelo construido.
![]()
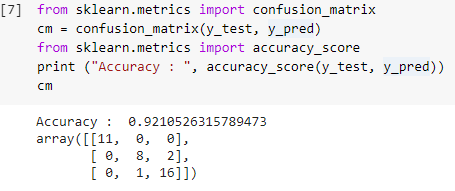
Paso 7: Matriz de confusión y precisión
Ahora que tenemos los valores reales y predichos de los conjuntos de prueba, construyamos una matriz de clasificación simple y calculemos la precisión de nuestro modelo construido usando funciones de biblioteca simples dentro de sklearn. La puntuación de precisión se calcula ingresando los valores reales y predichos del conjunto de prueba. El modelo creado con los pasos anteriores nos da una precisión del 92,1 %, que se denota como 0,92105 en el paso siguiente.
La matriz de confusión es una tabla que se utiliza para mostrar las predicciones correctas e incorrectas sobre un problema de clasificación. Para un uso simple, los valores a lo largo de la diagonal representan las predicciones correctas y los otros valores fuera de la diagonal son predicciones incorrectas.
Al calcular el número de 38 puntos de datos del conjunto de prueba, obtenemos 35 predicciones correctas y 3 predicciones incorrectas, que se reflejan como un 92 % de precisión. La precisión se puede mejorar optimizando los hiperparámetros que se pueden dar como argumentos al clasificador antes de entrenar el modelo.
Paso 8: visualización del clasificador del árbol de decisiones
Finalmente, en el último paso visualizaremos el Árbol de Decisión construido. Al observar el nodo raíz, se ve que el número de "muestras" es 112, que están sincronizadas con las muestras del conjunto de entrenamiento divididas antes. El índice GINI se calcula durante cada paso del algoritmo del árbol de decisión y las 3 clases se dividen como se muestra en el parámetro "valor" en el árbol de decisión.

Debe leer: Preguntas y respuestas de la entrevista del árbol de decisiones
Conclusión
Por lo tanto, de esta manera, hemos entendido el concepto de algoritmo de árbol de decisión y hemos construido un clasificador simple para resolver un problema de clasificación usando este algoritmo.
Si está interesado en obtener más información sobre árboles de decisión, aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones. , estado de exalumno de IIIT-B, más de 5 proyectos prácticos finales y asistencia laboral con las mejores empresas.
¿Cuáles son las desventajas de usar árboles de decisión?
Si bien los árboles de decisión ayudan en la clasificación o clasificación de los datos, su uso a veces también crea algunos problemas. A menudo, los árboles de decisión conducen al sobreajuste de los datos, lo que hace que el resultado final sea muy inexacto. En el caso de grandes conjuntos de datos, no se recomienda el uso de un solo árbol de decisión porque genera complejidad. Además, los árboles de decisión son muy inestables, lo que significa que si provoca un pequeño cambio en el conjunto de datos dado, la estructura del árbol de decisión cambia mucho.
¿Cómo funciona un algoritmo de bosque aleatorio?
Un bosque aleatorio es esencialmente una colección de diversos árboles de decisión, al igual que un bosque se compone de muchos árboles. Los resultados del algoritmo de bosque aleatorio en realidad dependen de las predicciones de los árboles de decisión. La técnica de bosque aleatorio también minimiza la probabilidad de sobreajuste de datos. Para obtener el resultado requerido, la clasificación aleatoria de bosques emplea un enfoque de conjunto. Los datos de entrenamiento se utilizan para entrenar varios árboles de decisión. Cuando se separan los nodos, este conjunto de datos contiene observaciones y atributos que se elegirán al azar.
¿En qué se diferencia una tabla de decisiones de un árbol de decisiones?
Una tabla de decisiones puede generarse a partir de un árbol de decisiones, pero no al revés. Un árbol de decisiones se compone de nodos y ramas, mientras que una tabla de decisiones se compone de filas y columnas. En las tablas de decisión, se pueden insertar más de una condición o. En los árboles de decisión, este no es el caso. Las tablas de decisiones solo son útiles cuando solo se presentan unas pocas propiedades; los árboles de decisión, por otro lado, se pueden usar de manera efectiva con una gran cantidad de propiedades y una lógica sofisticada.