
Пример дерева решений: функция и реализация [шаг за шагом]
Опубликовано: 2020-12-28Оглавление
Введение
Деревья решений — один из самых мощных и популярных алгоритмов как для задач регрессии, так и для задач классификации. Они имеют структуру, подобную блок-схеме, и подпадают под категорию контролируемых алгоритмов. Способность деревьев решений визуализировать в виде блок-схемы позволяет им легко имитировать уровень мышления людей, и по этой причине эти деревья решений легко понять и интерпретировать.
Что такое дерево решений?
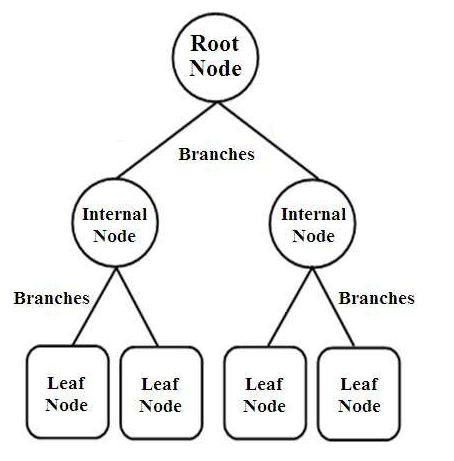
Деревья решений — это классификаторы с древовидной структурой. У них есть три типа узлов, которые:
- Корневые узлы
- Внутренние узлы
- Листовые узлы
Источник изображения
Корневые узлы — это первичные узлы, представляющие всю выборку, которая далее делится на несколько других узлов. Внутренние узлы представляют тест атрибута, а ветви представляют решение теста. Наконец, листовые узлы обозначают класс метки, решение о котором принимается после компиляции всех атрибутов. Узнайте больше об обучении дерева решений.
Как работают деревья решений?
Деревья решений используются в классификации путем их сортировки по всей древовидной структуре от корневого узла до конечного узла. Этот подход, используемый деревом решений, называется подходом сверху вниз. Как только конкретная точка данных вводится в дерево решений, она проходит через каждый узел дерева, отвечая на вопросы «Да/Нет», пока не достигнет определенного назначенного конечного узла.
Каждый узел в дереве решений представляет собой тестовый пример для атрибута, и каждый спуск (ветвь) к новому узлу соответствует одному из возможных ответов на этот тестовый пример. Таким образом, с помощью нескольких итераций дерево решений предсказывает значение для задачи регрессии или классифицирует объект в задаче классификации.

Реализация дерева решений
Теперь, когда у нас есть основы дерева решений, давайте рассмотрим его выполнение в программировании на Python.
Анализ проблемы
В следующем примере мы будем использовать знаменитый набор данных «Цветок ириса». Первоначально опубликованный в 1936 году в репозитории машинного обучения UCI (ссылка: https://archive.ics.uci.edu/ml/datasets/Iris ), этот небольшой набор данных широко используется для тестирования алгоритмов машинного обучения и визуализации.
В нем всего 150 строк и 5 столбцов, из которых 4 столбца — это атрибуты или признаки, а последний столбец — тип цветка ириса. Ирис — род цветковых растений в ботанике. Четыре атрибута в см:
- Длина чашелистика
- Ширина чашелистика
- Длина лепестка
- Ширина лепестка
Эти четыре признака используются для определения и классификации типа цветка ириса в зависимости от размера и формы. 5 -я или последняя колонка состоит из цветов класса ирисов, которые включают Iris Setosa, Iris Versicolor и Iris Virginica.
Для нашей проблемы мы должны построить модель машинного обучения, используя алгоритм дерева решений, чтобы изучить функции и классифицировать их на основе класса цветов ириса.
Давайте рассмотрим его реализацию на питоне шаг за шагом:
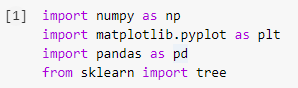
Шаг 1: Импорт библиотек
Первым шагом в создании любой модели машинного обучения на Python будет импорт необходимых библиотек, таких как Numpy, Pandas и Matplotlib. Модуль дерева импортируется из библиотеки sklearn для визуализации модели дерева решений в конце.
Шаг 2: Импорт набора данных
После того, как мы импортировали набор данных Iris, мы сохраняем файл .csv в Pandas DataFrame, из которого мы можем легко получить доступ к столбцам и строкам таблицы. Первые четыре столбца фрейма данных — это независимые переменные или признаки, которые должны быть поняты классификатором дерева решений и хранятся в переменной X.
Зависимая переменная, которая представляет собой класс цветов ириса, состоящий из 3 видов, хранится в переменной y. Набор данных визуализируется путем печати первых 5 строк.

Читайте также: Классификация дерева решений
Шаг 3: Разделение набора данных на обучающий набор и тестовый набор
На следующем шаге, после чтения набора данных, мы должны разделить весь набор данных на обучающий набор, на котором будет обучаться модель классификатора, и тестовый набор, на котором будет реализована обученная модель. Результаты, полученные на тестовом наборе, будут сравниваться для проверки точности обученной модели.

Здесь мы использовали размер теста 0,25, что означает, что 25% всего набора данных будут случайным образом разделены в качестве тестового набора, а оставшиеся 75% будут состоять из обучающего набора, который будет использоваться при обучении модели. Следовательно, из 150 точек данных 38 случайных точек данных сохраняются в качестве тестового набора, а остальные 112 образцов используются в обучающем наборе.

Шаг 4: Обучение модели классификации дерева решений на обучающем наборе
Как только модель разделена и готова к обучению, модуль DecisionTreeClassifier импортируется из библиотеки sklearn, а обучающие переменные (X_train и y_train) устанавливаются в классификаторе для построения модели. Во время этого процесса обучения классификатор подвергается нескольким методам оптимизации, таким как градиентный спуск и обратное распространение, и, наконец, строит модель классификатора дерева решений.

Шаг 5: Прогнозирование результатов набора тестов
Поскольку у нас есть готовая модель, не следует ли нам проверить ее точность на тестовом наборе? Этот шаг включает в себя тестирование модели, построенной с использованием алгоритма дерева решений, на тестовом наборе, который был разделен ранее. Эти результаты сохраняются в переменной «y_pred».
![]()
Шаг 6: Сравнение реальных значений с прогнозируемыми значениями
Это еще один простой шаг, на котором мы создадим еще один простой фрейм данных, который будет состоять из двух столбцов, реальных значений тестового набора с одной стороны и прогнозируемых значений с другой стороны. Этот шаг позволяет нам сравнить результаты, полученные построенной моделью.
![]()
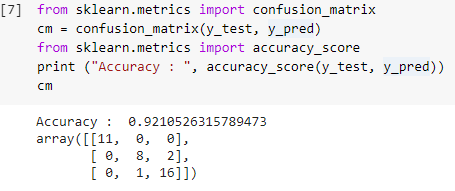
Шаг 7: Матрица путаницы и точность
Теперь, когда у нас есть как реальные, так и прогнозируемые значения тестовых наборов, давайте построим простую матрицу классификации и рассчитаем точность нашей модели, построенной с использованием простых библиотечных функций в sklearn. Оценка точности рассчитывается путем ввода как реальных, так и прогнозируемых значений тестового набора. Модель, построенная с использованием вышеуказанных шагов, дает нам точность 92,1%, которая обозначена как 0,92105 на шаге ниже.
Матрица путаницы — это таблица, которая используется для отображения правильных и неправильных прогнозов в задаче классификации. Для простоты использования значения по диагонали представляют правильные прогнозы, а другие значения за пределами диагонали — неправильные прогнозы.
При вычислении числа из 38 точек данных тестового набора мы получаем 35 правильных прогнозов и 3 неправильных прогноза, которые отражают точность 92%. Точность можно повысить, оптимизировав гиперпараметры, которые можно передать в качестве аргументов классификатору перед обучением модели.
Шаг 8: Визуализация классификатора дерева решений
Наконец, на последнем шаге мы визуализируем построенное дерево решений. Заметив корневой узел, видно, что количество «выборок» равно 112, что синхронизировано с выборками обучающего набора, разделенными ранее. Индекс GINI рассчитывается на каждом этапе алгоритма дерева решений, и 3 класса разделяются, как показано в параметре «значение» в дереве решений.

Обязательно к прочтению: вопросы и ответы на собеседовании по дереву принятия решений
Заключение
Таким образом, мы поняли концепцию алгоритма дерева решений и создали простой классификатор для решения задачи классификации с использованием этого алгоритма.
Если вам интересно узнать больше о деревьях решений и машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий. , статус выпускника IIIT-B, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Каковы недостатки использования деревьев решений?
Хотя деревья решений помогают в классификации или сортировке данных, их использование также иногда создает некоторые проблемы. Часто деревья решений приводят к переоснащению данных, что еще больше делает окончательный результат крайне неточным. В случае больших наборов данных использование одного дерева решений не рекомендуется, поскольку это приводит к сложности. Кроме того, деревья решений очень нестабильны, а это означает, что если вы внесете небольшое изменение в данный набор данных, структура дерева решений сильно изменится.
Как работает алгоритм случайного леса?
Случайный лес — это, по сути, набор разнообразных деревьев решений, точно так же, как лес состоит из множества деревьев. Результаты алгоритма случайного леса на самом деле зависят от предсказаний деревьев решений. Метод случайного леса также сводит к минимуму вероятность переобучения данных. Чтобы получить требуемый результат, классификация случайных лесов использует ансамблевый подход. Данные обучения используются для обучения различных деревьев решений. Когда узлы разделены, этот набор данных содержит наблюдения и атрибуты, которые будут выбраны случайным образом.
Чем таблица решений отличается от дерева решений?
Таблица решений может быть получена из дерева решений, но не наоборот. Дерево решений состоит из узлов и ветвей, тогда как таблица решений состоит из строк и столбцов. В таблицы решений можно вставить более одного условия или. В деревьях решений это не так. Таблицы решений полезны только тогда, когда представлены только несколько свойств; деревья решений, с другой стороны, могут эффективно использоваться с большим количеством свойств и сложной логикой.