
Esempio di albero decisionale: funzione e implementazione [passo dopo passo]
Pubblicato: 2020-12-28Sommario
introduzione
Gli alberi decisionali sono uno degli algoritmi più potenti e popolari sia per le attività di regressione che di classificazione. Sono una struttura simile a un diagramma di flusso e rientrano nella categoria degli algoritmi supervisionati. La capacità degli alberi decisionali di essere visualizzati come un diagramma di flusso consente loro di imitare facilmente il livello di pensiero degli esseri umani e questo è il motivo per cui questi alberi decisionali sono facilmente comprensibili e interpretabili.
Che cos'è un albero decisionale?
Gli alberi decisionali sono un tipo di classificatori strutturati ad albero. Hanno tre tipi di nodi che sono,
- Nodi radice
- Nodi interni
- Nodi fogliari
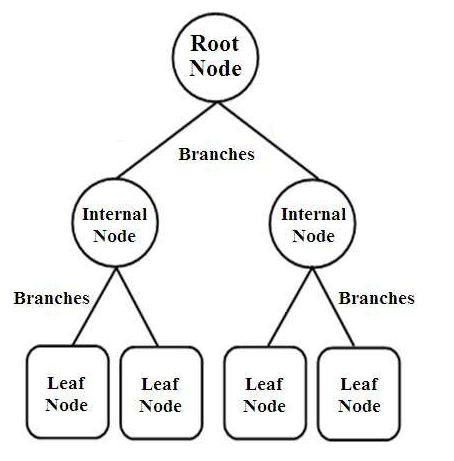
Fonte immagine
I nodi radice sono i nodi primari che rappresentano l'intero campione che è ulteriormente suddiviso in molti altri nodi. I nodi interni rappresentano il test su un attributo mentre i rami rappresentano la decisione del test. Infine, i nodi foglia denotano la classe dell'etichetta, che è la decisione presa dopo la compilazione di tutti gli attributi. Ulteriori informazioni sull'apprendimento dell'albero decisionale.
Come funzionano gli alberi decisionali?
Gli alberi decisionali vengono utilizzati nella classificazione ordinandoli lungo l'intera struttura ad albero dal nodo radice al nodo foglia. Questo approccio utilizzato dall'albero decisionale è chiamato approccio Top-Down. Una volta che un particolare punto dati viene inserito nell'albero decisionale, viene fatto passare attraverso ogni singolo nodo dell'albero rispondendo alle domande Sì/No finché non raggiunge il particolare nodo foglia designato.
Ogni nodo nell'albero decisionale rappresenta un test case per un attributo e ogni discesa (ramo) a un nuovo nodo corrisponde a una delle possibili risposte a quel test case. In questo modo, con più iterazioni, l'albero decisionale prevede un valore per l'attività di regressione o classifica l'oggetto in un'attività di classificazione.

Implementazione dell'albero decisionale
Ora che abbiamo le basi di un albero decisionale, esaminiamo la sua esecuzione nella programmazione Python.
Analisi del problema
Nell'esempio seguente utilizzeremo il famoso set di dati "Iris Flower". Originariamente pubblicato nel 1936 su UCI Machine Learning Repository, (Link: https://archive.ics.uci.edu/ml/datasets/Iris ), questo piccolo set di dati è ampiamente utilizzato per testare algoritmi e visualizzazioni di apprendimento automatico.
In questo, ci sono un totale di 150 righe e 5 colonne di cui 4 colonne sono gli attributi o le caratteristiche e l'ultima colonna è il tipo di specie di fiori di Iris. Iris è un genere di piante da fiore in botanica. I quattro attributi in cm sono,
- Lunghezza del sepalo
- Larghezza del sepalo
- Lunghezza del petalo
- Larghezza petalo
Queste quattro caratteristiche vengono utilizzate per definire e classificare il tipo di fiore Iris a seconda delle dimensioni e della forma. La 5a o l'ultima colonna è costituita dalla classe dei fiori Iris, che sono Iris Setosa, Iris Versicolor e Iris Virginica.
Per il nostro problema, dobbiamo costruire un modello di Machine Learning utilizzando l'algoritmo dell'albero delle decisioni per apprendere le funzionalità e classificarle in base alla classe del fiore di iris.
Esaminiamo la sua implementazione in Python, passo dopo passo:
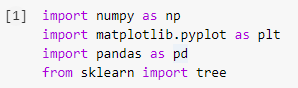
Passaggio 1: importazione delle librerie
Il primo passo nella creazione di qualsiasi modello di machine learning in Python sarà importare le librerie necessarie come Numpy, Pandas e Matplotlib. Il modulo tree viene importato dalla libreria sklearn per visualizzare il modello Decision Tree alla fine.
Passaggio 2: importazione del set di dati
Una volta importato il set di dati Iris, memorizziamo il file .csv in un Pandas DataFrame da cui possiamo accedere facilmente alle colonne e alle righe della tabella. Le prime quattro colonne del dataframe sono le variabili indipendenti o le caratteristiche che devono essere comprese dal classificatore dell'albero decisionale e sono memorizzate nella variabile X.
La variabile dipendente che è la classe di fiori Iris composta da 3 specie è memorizzata nella variabile y. Il dataset viene visualizzato stampando le prime 5 righe.

Leggi anche: Classificazione dell'albero decisionale
Passaggio 3: suddivisione del set di dati nel set di allenamento e nel set di test
Nel passaggio successivo, dopo aver letto il set di dati, dobbiamo dividere l'intero set di dati nel set di addestramento, utilizzando il modello di classificatore su cui verrà addestrato e il set di test, su cui verrà implementato il modello addestrato. I risultati ottenuti sul set di prova verranno confrontati per verificare l'accuratezza del modello addestrato.

In questo caso, abbiamo utilizzato una dimensione del test di 0,25, che denota che il 25% dell'intero set di dati verrà suddiviso casualmente come set di test e il restante 75% sarà costituito dal set di addestramento da utilizzare nell'addestramento del modello. Quindi, su 150 punti dati, 38 punti dati casuali vengono mantenuti come set di test e i restanti 112 campioni vengono utilizzati nel set di addestramento.

Fase 4: Addestrare il modello di classificazione dell'albero decisionale sul Training Set
Una volta che il modello è stato suddiviso ed è pronto per l'addestramento, il modulo DecisionTreeClassifier viene importato dalla libreria sklearn e le variabili di addestramento (X_train e y_train) vengono adattate al classificatore per costruire il modello. Durante questo processo di addestramento, il classificatore viene sottoposto a diversi metodi di ottimizzazione come la discesa del gradiente e la retropropagazione e infine costruisce il modello del classificatore dell'albero delle decisioni.

Passaggio 5: previsione dei risultati del set di test
Poiché abbiamo il nostro modello pronto, non dovremmo verificarne l'accuratezza sul set di prova? Questo passaggio prevede il test del modello costruito utilizzando l'algoritmo dell'albero decisionale sul set di test che è stato suddiviso in precedenza. Questi risultati sono memorizzati in una variabile, "y_pred".
![]()
Passaggio 6: confrontare i valori reali con i valori previsti
Questo è un altro semplice passaggio, in cui costruiremo un altro semplice dataframe che sarà composto da due colonne, i valori reali del test impostato su un lato e i valori previsti dall'altro lato. Questo passaggio permette di confrontare i risultati ottenuti dal modello costruito.
![]()
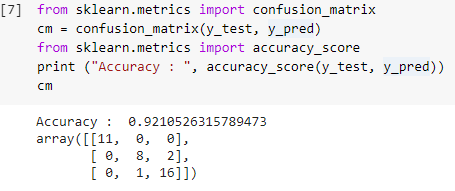
Passaggio 7: matrice di confusione e precisione
Ora che abbiamo sia i valori reali che quelli previsti dei set di test, costruiamo una semplice matrice di classificazione e calcoliamo l'accuratezza del nostro modello costruito utilizzando semplici funzioni di libreria all'interno di sklearn. Il punteggio di precisione viene calcolato inserendo sia i valori reali che quelli previsti del set di test. Il modello costruito utilizzando i passaggi precedenti ci fornisce una precisione del 92,1% che è indicato come 0,92105 nel passaggio seguente.
La matrice di confusione è una tabella utilizzata per mostrare le previsioni corrette e errate su un problema di classificazione. Per un utilizzo semplice, i valori lungo la diagonale rappresentano le previsioni corrette e gli altri valori al di fuori della diagonale sono previsioni errate.
Calcolando il numero da 38 punti dati del set di test, otteniamo 35 previsioni corrette e 3 previsioni errate, che si riflettono come accurate al 92%. L'accuratezza può essere migliorata ottimizzando gli iperparametri che possono essere forniti come argomenti al classificatore prima di addestrare il modello.
Passaggio 8: visualizzazione del classificatore dell'albero decisionale
Infine, nell'ultimo passaggio visualizzeremo il Decision Tree costruito. Notando il nodo radice, si vede che il numero di "campioni" è 112, che sono sincronizzati con i campioni del set di addestramento suddivisi in precedenza. L'indice GINI viene calcolato durante ogni passaggio dell'algoritmo dell'albero decisionale e le 3 classi vengono suddivise come mostrato nel parametro "valore" nell'albero decisionale.

Da leggere: Domande e risposte sull'intervista sull'albero decisionale
Conclusione
Quindi, in questo modo, abbiamo compreso il concetto di algoritmo Decision Tree e abbiamo costruito un semplice Classificatore per risolvere un problema di classificazione utilizzando questo algoritmo.
Se sei interessato a saperne di più sugli alberi decisionali, sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi , status di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali sono i contro dell'utilizzo degli alberi decisionali?
Sebbene gli alberi decisionali aiutino nella classificazione o nell'ordinamento dei dati, il loro utilizzo a volte crea anche alcuni problemi. Spesso, gli alberi decisionali portano all'overfitting dei dati, il che rende ulteriormente il risultato finale altamente impreciso. In caso di insiemi di dati di grandi dimensioni, l'uso di un unico albero decisionale non è consigliato perché causa complessità. Inoltre, gli alberi decisionali sono altamente instabili, il che significa che se si provoca una piccola modifica nel dataset specificato, la struttura dell'albero decisionale cambia notevolmente.
Come funziona un algoritmo di foresta casuale?
Una foresta casuale è essenzialmente una raccolta di diversi alberi decisionali, proprio come una foresta è composta da molti alberi. I risultati dell'algoritmo della foresta casuale dipendono in realtà dalle previsioni degli alberi decisionali. La tecnica della foresta casuale riduce anche la probabilità di un adattamento eccessivo dei dati. Per ottenere il risultato richiesto, la classificazione casuale delle foreste utilizza un approccio di insieme. I dati di addestramento vengono utilizzati per addestrare vari alberi decisionali. Quando i nodi sono separati, questo set di dati contiene osservazioni e attributi che verranno scelti a caso.
In che modo una tabella decisionale è diversa da un albero decisionale?
Una tabella decisionale può essere prodotta da un albero decisionale, ma non viceversa. Un albero decisionale è composto da nodi e rami, mentre una tabella decisionale è composta da righe e colonne. Nelle tabelle decisionali è possibile inserire più di una condizione. Negli alberi decisionali, questo non è il caso. Le tabelle decisionali sono utili solo quando vengono presentate solo poche proprietà; gli alberi decisionali, d'altra parte, possono essere utilizzati efficacemente con un gran numero di proprietà e una logica sofisticata.