
デシジョンツリーの例:機能と実装[ステップバイステップ]
公開: 2020-12-28目次
序章
デシジョンツリーは、回帰タスクと分類タスクの両方で最も強力で人気のあるアルゴリズムの1つです。 それらは構造のようなフローチャートであり、監視ありアルゴリズムのカテゴリに分類されます。 フローチャートのように視覚化できる決定木の能力により、人間の思考レベルを簡単に模倣することができます。これが、これらの決定木が簡単に理解および解釈される理由です。
デシジョンツリーとは何ですか?
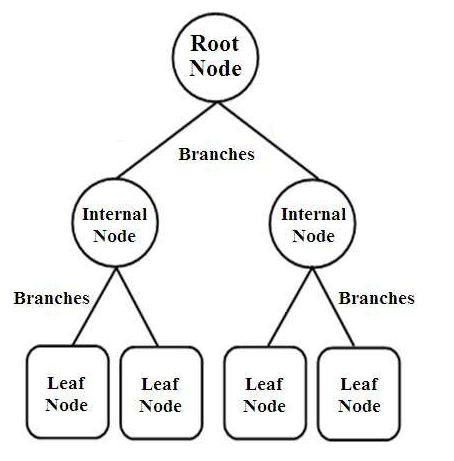
デシジョンツリーは、ツリー構造の分類子の一種です。 それらには、次の3種類のノードがあります。
- ルートノード
- 内部ノード
- リーフノード
画像ソース
ルートノードは、サンプル全体を表すプライマリノードであり、さらにいくつかの他のノードに分割されます。 内部ノードは属性のテストを表し、ブランチはテストの決定を表します。 最後に、リーフノードはラベルのクラスを示します。これは、すべての属性のコンパイル後に行われる決定です。 デシジョンツリー学習の詳細をご覧ください。
デシジョンツリーはどのように機能しますか?
決定木は、ルートノードからリーフノードまでのツリー構造全体を並べ替えることにより、分類に使用されます。 デシジョンツリーで使用されるこのアプローチは、トップダウンアプローチと呼ばれます。 特定のデータポイントが決定木に入力されると、特定の指定されたリーフノードに到達するまで、はい/いいえの質問に答えることによって、ツリーのすべてのノードを通過します。
デシジョンツリーの各ノードは、属性のテストケースを表し、新しいノードへの各降下(分岐)は、そのテストケースに対する可能な回答の1つに対応します。 このように、複数の反復で、決定木は回帰タスクの値を予測するか、分類タスクでオブジェクトを分類します。

デシジョンツリーの実装
デシジョンツリーの基本がわかったので、Pythonプログラミングでの実行について見ていきましょう。
問題分析
次の例では、有名な「アイリスフラワー」データセットを使用します。 1936年にUCIMachineLearning Repository(リンク: https ://archive.ics.uci.edu/ml/datasets/Iris )で最初に公開されたこの小さなデータセットは、機械学習アルゴリズムと視覚化のテストに広く使用されています。
この中には、合計150行5列あり、そのうち4列は属性または特徴であり、最後の列はアヤメの花の種類です。 アイリスは植物学の顕花植物の属です。 cm単位の4つの属性は、
- がく片の長さ
- がく片の幅
- 花びらの長さ
- 花びらの幅
これらの4つの機能は、サイズと形状に応じてアイリスの花のタイプを定義および分類するために使用されます。 5番目または最後の列は、Iris Setosa、Iris Versicolor、およびIrisVirginicaであるIris花クラスで構成されています。
私たちの問題では、決定木アルゴリズムを利用して機械学習モデルを構築し、特徴を学習して、アイリスの花のクラスに基づいて分類する必要があります。
Pythonでの実装を段階的に見ていきましょう。
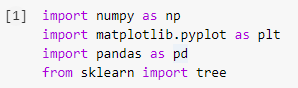
ステップ1:ライブラリをインポートする
Pythonで機械学習モデルを構築する最初のステップは、Numpy、Pandas、Matplotlibなどの必要なライブラリをインポートすることです。 ツリーモジュールはsklearnライブラリからインポートされ、最後にディシジョンツリーモデルを視覚化します。
ステップ2:データセットをインポートする
Irisデータセットをインポートしたら、.csvファイルをPandas DataFrameに保存します。このデータセットから、テーブルの列と行に簡単にアクセスできます。 データフレームの最初の4列は、決定木分類器によって理解され、変数Xに格納される独立変数または特徴です。
3種からなるアイリスの花のクラスである従属変数は、変数yに格納されます。 データセットは、最初の5行を印刷することで視覚化されます。

また読む:ディシジョンツリー分類

ステップ3:データセットをトレーニングセットとテストセットに分割する
次のステップでは、データセットを読み取った後、データセット全体をトレーニングセットに分割する必要があります。これを使用して、分類器モデルがトレーニングされ、テストセットにトレーニングされたモデルが実装されます。 テストセットで得られた結果は、トレーニングされたモデルの精度をチェックするために比較されます。
ここでは、0.25のテストサイズを使用しました。これは、データセット全体の25%がテストセットとしてランダムに分割され、残りの75%がモデルのトレーニングに使用されるトレーニングセットで構成されることを意味します。 したがって、150個のデータポイントのうち38個のランダムなデータポイントがテストセットとして保持され、残りの112個のサンプルがトレーニングセットで使用されます。

ステップ4:トレーニングセットでディシジョンツリー分類モデルをトレーニングする
モデルが分割され、トレーニングの準備が整うと、DecisionTreeClassifierモジュールがsklearnライブラリからインポートされ、トレーニング変数(X_trainおよびy_train)が分類子に適合されてモデルが構築されます。 このトレーニングプロセス中に、分類器は最急降下法やバックプロパゲーションなどのいくつかの最適化手法を実行し、最終的に決定木分類器モデルを構築します。

ステップ5:テストセットの結果を予測する
モデルの準備ができたので、テストセットでその精度を確認する必要がありますか? このステップには、以前に分割されたテストセットでデシジョンツリーアルゴリズムを使用して構築されたモデルのテストが含まれます。 これらの結果は、変数「y_pred」に格納されます。
![]()
ステップ6:実際の値と予測値の比較
これは別の簡単なステップで、2つの列で構成される別の簡単なデータフレームを作成します。一方の側にテストセットの実際の値、もう一方の側に予測値があります。 このステップにより、構築されたモデルによって得られた結果を比較できます。
![]()
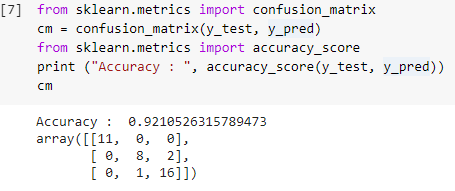
ステップ7:混同行列と精度
テストセットの実際の値と予測値の両方が得られたので、簡単な分類行列を作成し、sklearn内の簡単なライブラリ関数を使用して作成したモデルの精度を計算しましょう。 精度スコアは、テストセットの実際の値と予測値の両方を入力することによって計算されます。 上記の手順を使用して作成されたモデルでは、92.1%の精度が得られます。これは、次の手順では0.92105として示されます。
混同行列は、分類問題の正しい予測と誤った予測を示すために使用されるテーブルです。 簡単な使用法では、対角線を横切る値は正しい予測を表し、対角線の外側の他の値は誤った予測を表します。
38個のテストセットデータポイントから数を計算すると、35個の正しい予測と3個の誤った予測が得られ、92%の精度として反映されます。 モデルをトレーニングする前に分類器に引数として指定できるハイパーパラメータを最適化することで、精度を向上させることができます。
ステップ8:ディシジョンツリー分類子の視覚化
最後に、最後のステップで、構築されたディシジョンツリーを視覚化します。 ルートノードに注目すると、「サンプル」の数は112であり、以前に分割されたトレーニングセットのサンプルと同期していることがわかります。 GINIインデックスは、デシジョンツリーアルゴリズムの各ステップで計算され、デシジョンツリーの「value」パラメーターに示されているように3つのクラスが分割されます。

必読:ディシジョンツリーインタビューの質問と回答
結論
したがって、このようにして、決定木アルゴリズムの概念を理解し、このアルゴリズムを使用して分類問題を解決するための単純な分類器を構築しました。
意思決定ツリー、機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題を提供します。 、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
デシジョンツリーを使用することの短所は何ですか?
デシジョンツリーはデータの分類や並べ替えに役立ちますが、決定木を使用するといくつかの問題が発生することもあります。 多くの場合、決定木はデータの過剰適合につながり、最終結果が非常に不正確になります。 大規模なデータセットの場合、複雑さを引き起こすため、単一の決定木を使用することはお勧めしません。 また、デシジョンツリーは非常に不安定です。つまり、特定のデータセットに小さな変更を加えると、デシジョンツリーの構造が大幅に変更されます。
ランダムフォレストアルゴリズムはどのように機能しますか?
ランダムフォレストは、フォレストが多くのツリーで構成されているように、本質的には多様な決定木のコレクションです。 ランダムフォレストアルゴリズムの結果は、実際には決定木の予測に依存しています。 ランダムフォレスト手法は、データの過剰適合の可能性も最小限に抑えます。 必要な結果を得るために、ランダムフォレスト分類はアンサンブルアプローチを採用しています。 トレーニングデータは、さまざまな決定木のトレーニングに使用されます。 ノードが分離されている場合、このデータセットには、ランダムに選択される観測値と属性が含まれます。
デシジョンテーブルはデシジョンツリーとどのように異なりますか?
デシジョンテーブルはデシジョンツリーから作成できますが、その逆はできません。 デシジョンツリーはノードとブランチで構成されていますが、デシジョンテーブルは行と列で構成されています。 デシジョンテーブルでは、複数のまたは条件を挿入できます。 デシジョンツリーでは、これは当てはまりません。 デシジョンテーブルは、少数のプロパティのみが表示される場合にのみ役立ちます。 一方、決定木は、多数のプロパティと高度なロジックで効果的に使用できます。