
决策树示例:功能和实现 [逐步]
已发表: 2020-12-28目录
介绍
决策树是用于回归和分类任务的最强大和最流行的算法之一。 它们是类似结构的流程图,属于监督算法的范畴。 决策树像流程图一样可视化的能力使它们能够轻松模仿人类的思维水平,这就是这些决策树易于理解和解释的原因。
什么是决策树?
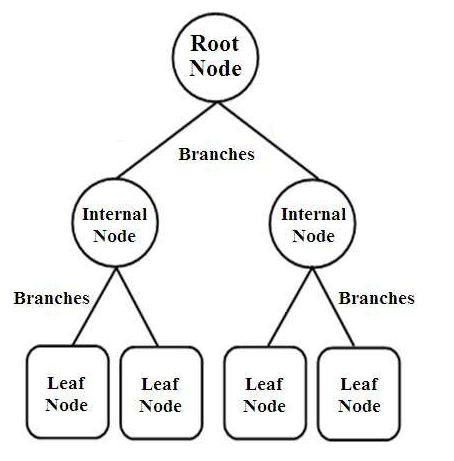
决策树是一种树形结构的分类器。 它们具有三种类型的节点,它们是,
- 根节点
- 内部节点
- 叶节点
图片来源
根节点是代表整个样本的主要节点,该样本进一步分为几个其他节点。 内部节点代表对属性的测试,而分支代表测试的决定。 最后,叶子节点表示标签的类别,这是所有属性编译后做出的决定。 了解有关决策树学习的更多信息。
决策树如何工作?
决策树通过从根节点到叶节点对整个树结构进行排序来用于分类。 决策树使用的这种方法称为自顶向下方法。 一旦一个特定的数据点被输入到决策树中,它就会通过回答是/否问题来通过树的每个节点,直到它到达特定的指定叶节点。
决策树中的每个节点代表一个属性的测试用例,每个下降(分支)到一个新节点对应于该测试用例的可能答案之一。 这样,通过多次迭代,决策树预测回归任务的值或在分类任务中对对象进行分类。

决策树实现
现在我们已经了解了决策树的基础知识,让我们继续了解它在 Python 编程中的执行。
问题分析
在下面的示例中,我们将使用著名的“鸢尾花”数据集。 这个小型数据集最初于 1936 年在 UCI 机器学习存储库(链接: https ://archive.ics.uci.edu/ml/datasets/Iris )上发布,广泛用于测试机器学习算法和可视化。
其中,共有 150 行 5 列,其中 4 列是属性或特征,最后一列是鸢尾花种类。 鸢尾花是植物学中开花植物的一个属。 cm中的四个属性是,
- 萼片长度
- 萼片宽度
- 花瓣长度
- 花瓣宽度
这四个特征用于根据大小和形状来定义和分类鸢尾花的类型。 第 5列或最后一列由鸢尾花类组成,分别是 Iris Setosa、Iris Versicolor 和 Iris Virginica。
对于我们的问题,我们必须利用决策树算法构建一个机器学习模型来学习特征并根据鸢尾花类对其进行分类。
让我们一步一步地在python中实现它:
第 1 步:导入库
在 Python 中构建任何机器学习模型的第一步是导入必要的库,例如 Numpy、Pandas 和 Matplotlib。 树模块是从 sklearn 库中导入的,最后将决策树模型可视化。
第 2 步:导入数据集
导入 Iris 数据集后,我们将 .csv 文件存储到 Pandas DataFrame 中,我们可以从中轻松访问表格的列和行。 数据框的前四列是自变量或决策树分类器要理解的特征,并存储在变量 X 中。
由 3 个物种组成的鸢尾花类的因变量存储在变量 y 中。 通过打印前 5 行来可视化数据集。


另请阅读:决策树分类
步骤 3:将数据集拆分为训练集和测试集
在接下来的步骤中,在读取数据集后,我们必须将整个数据集拆分为训练集,用于训练分类器模型和测试集,将在其上实现训练模型。 将比较在测试集上获得的结果,以检查训练模型的准确性。
在这里,我们使用了 0.25 的测试大小,这表示整个数据集的 25% 将被随机拆分为测试集,其余 75% 将包含用于训练模型的训练集。 因此,在 150 个数据点中,保留 38 个随机数据点作为测试集,其余 112 个样本用于训练集。

第 4 步:在训练集上训练决策树分类模型
一旦模型被分割并准备好用于训练目的,DecisionTreeClassifier 模块将从 sklearn 库中导入,并将训练变量(X_train 和 y_train)安装在分类器上以构建模型。 在这个训练过程中,分类器经过梯度下降和反向传播等多种优化方法,最终建立决策树分类器模型。

第 5 步:预测测试集结果
既然我们已经准备好了模型,我们不应该在测试集上检查它的准确性吗? 此步骤涉及在先前拆分的测试集上测试使用决策树算法构建的模型。 这些结果存储在变量“y_pred”中。
![]()
第 6 步:将实际值与预测值进行比较
这是另一个简单的步骤,我们将在其中构建另一个简单的数据框,该数据框由两列组成,一侧是测试集的真实值,另一侧是预测值。 这一步使我们能够比较所建立的模型所获得的结果。
![]()
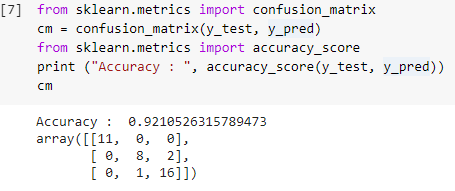
第 7 步:混淆矩阵和准确性
现在我们有了测试集的真实值和预测值,让我们构建一个简单的分类矩阵并计算使用 sklearn 中的简单库函数构建的模型的准确性。 准确度分数是通过输入测试集的真实值和预测值来计算的。 使用上述步骤构建的模型为我们提供了 92.1% 的准确度,在下面的步骤中表示为 0.92105。
混淆矩阵是一个表格,用于显示对分类问题的正确和错误预测。 为简单起见,对角线上的值表示正确的预测,对角线之外的其他值表示不正确的预测。
在计算 38 个测试集数据点的数量时,我们得到 35 个正确的预测和 3 个错误的预测,准确率为 92%。 在训练模型之前,可以通过优化超参数来提高准确性,这些超参数可以作为分类器的参数。
第 8 步:可视化决策树分类器
最后,在最后一步中,我们将可视化构建的决策树。 在注意到根节点时,可以看到“样本”的数量为 112,这与之前拆分的训练集样本是同步的。 GINI 指数在决策树算法的每个步骤中计算,并且 3 个类被拆分,如决策树中的“值”参数所示。

必读:决策树面试问答
结论
因此,通过这种方式,我们了解了决策树算法的概念,并构建了一个简单的分类器来使用该算法解决分类问题。
如果您有兴趣了解有关决策树、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业,IIIT-B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
使用决策树有什么缺点?
虽然决策树有助于数据的分类或排序,但它们的使用有时也会产生一些问题。 通常,决策树会导致数据过度拟合,从而进一步使最终结果非常不准确。 在大型数据集的情况下,不建议使用单个决策树,因为它会导致复杂性。 此外,决策树是高度不稳定的,这意味着如果您对给定数据集造成很小的变化,决策树的结构就会发生很大变化。
随机森林算法如何工作?
随机森林本质上是不同决策树的集合,就像森林是由许多树组成的一样。 随机森林算法的结果实际上取决于决策树的预测。 随机森林技术还可以最大限度地减少数据过度拟合的可能性。 为了获得所需的结果,随机森林分类采用了集成方法。 训练数据用于训练各种决策树。 当节点分离时,该数据集包含将随机挑选的观察值和属性。
决策表与决策树有何不同?
决策表可以从决策树生成,但反过来不行。 决策树由节点和分支组成,而决策表由行和列组成。 在决策表中,可以插入多个 or 条件。 在决策树中,情况并非如此。 决策表仅在仅显示少数属性时才有用; 另一方面,决策树可以有效地与大量属性和复杂的逻辑一起使用。