
Exemplu de arbore de decizie: funcție și implementare [pas cu pas]
Publicat: 2020-12-28Cuprins
Introducere
Arborii de decizie sunt unul dintre cei mai puternici și populari algoritmi atât pentru sarcinile de regresie, cât și pentru cele de clasificare. Sunt o structură asemănătoare unei diagrame de flux și se încadrează în categoria algoritmilor supravegheați. Capacitatea arborilor de decizie de a fi vizualizați ca o diagramă de flux le permite să imite cu ușurință nivelul de gândire al oamenilor și acesta este motivul pentru care acești arbori de decizie sunt ușor de înțeles și interpretat.
Ce este un arbore de decizie?
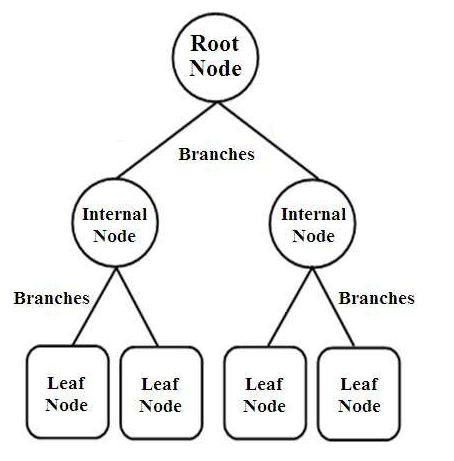
Arborii de decizie sunt un tip de clasificatori structurați în arbore. Au trei tipuri de noduri care sunt,
- Noduri rădăcină
- Noduri interne
- Noduri de frunze
Sursa imaginii
Nodurile rădăcină sunt nodurile primare care reprezintă întregul eșantion care este împărțit în continuare în câteva alte noduri. Nodurile interne reprezintă testul asupra unui atribut în timp ce ramurile reprezintă decizia testului. În cele din urmă, nodurile frunze denotă clasa etichetei, care este decizia luată după compilarea tuturor atributelor. Aflați mai multe despre învățarea arborelui de decizie.
Cum funcționează arborii de decizie?
Arborele de decizie sunt utilizați în clasificare prin sortarea lor în întreaga structură de arbore de la nodul rădăcină la nodul frunză. Această abordare utilizată de arborele de decizie este numită abordare de sus în jos. Odată ce un anumit punct de date este introdus în arborele de decizie, acesta trebuie să treacă prin fiecare nod al arborelui, răspunzând la întrebările Da/Nu până ajunge la nodul frunză desemnat.
Fiecare nod din arborele de decizie reprezintă un caz de testare pentru un atribut și fiecare coborâre (ramură) la un nou nod corespunde unuia dintre răspunsurile posibile la acel caz de testare. În acest fel, cu mai multe iterații, arborele de decizie prezice o valoare pentru sarcina de regresie sau clasifică obiectul într-o sarcină de clasificare.

Implementarea arborelui decizional
Acum că avem elementele de bază ale unui arbore de decizie, haideți să trecem prin execuția acestuia în programarea Python.
Analiza problemei
În exemplul următor vom folosi faimosul set de date „Floarea de iris”. Publicat inițial în 1936 la UCI Machine Learning Repository, (Link: https://archive.ics.uci.edu/ml/datasets/Iris ), acest mic set de date este utilizat pe scară largă pentru testarea algoritmilor și vizualizărilor de învățare automată.
În aceasta, există un total de 150 de rânduri și 5 coloane din care 4 coloane sunt atributele sau trăsăturile și ultima coloană este tipul speciei de flori de iris. Irisul este un gen de plante cu flori în botanică. Cele patru atribute în cm sunt:
- Lungimea sepalului
- Lățimea sepalului
- Lungimea petalei
- Lățimea petelor
Aceste patru caracteristici sunt folosite pentru a defini și clasifica tipul de flori de iris în funcție de dimensiune și formă. A 5- a sau ultima coloană este formată din clasa florilor Iris, care sunt Iris Setosa, Iris Versicolor și Iris Virginica.
Pentru problema noastră, trebuie să construim un model de învățare automată utilizând algoritmul arborelui de decizie pentru a învăța caracteristicile și a le clasifica pe baza clasei de flori Iris.
Să trecem prin implementarea sa în python, pas cu pas:
Pasul 1: Importul bibliotecilor
Primul pas în construirea oricărui model de învățare automată în Python va fi importarea bibliotecilor necesare, cum ar fi Numpy, Pandas și Matplotlib. Modulul arborelui este importat din biblioteca sklearn pentru a vizualiza modelul arborelui decizional la sfârșit.
Pasul 2: Importul setului de date
Odată ce am importat setul de date Iris, stocăm fișierul .csv într-un Pandas DataFrame din care putem accesa cu ușurință coloanele și rândurile tabelului. Primele patru coloane ale cadrului de date sunt variabilele independente sau caracteristicile care trebuie înțelese de clasificatorul arborelui de decizie și sunt stocate în variabila X.
Variabila dependentă care este clasa de flori Iris, constând din 3 specii, este stocată în variabila y. Setul de date este vizualizat prin imprimarea primelor 5 rânduri.

Citește și: Clasificarea arborelui de decizie
Pasul 3: Împărțirea setului de date în setul de antrenament și setul de testare
În pasul următor, după citirea setului de date, trebuie să împărțim întregul setul de date în setul de antrenament, folosindu-ne de antrenat modelul de clasificator și setul de testare, pe care va fi implementat modelul antrenat. Rezultatele obținute pe setul de testare vor fi comparate pentru a verifica acuratețea modelului antrenat.

Aici, am folosit o dimensiune a testului de 0,25, ceea ce indică faptul că 25% din întregul set de date va fi împărțit aleatoriu ca set de testare, iar restul de 75% va consta din setul de antrenament care va fi utilizat în antrenamentul modelului. Prin urmare, din 150 de puncte de date, 38 de puncte de date aleatorii sunt reținute ca set de testare, iar restul de 112 eșantioane sunt utilizate în setul de antrenament.

Pasul 4: Antrenarea modelului de clasificare a arborelui de decizie pe setul de antrenament
Odată ce modelul a fost împărțit și este gata de antrenament, modulul DecisionTreeClassifier este importat din biblioteca sklearn și variabilele de antrenament (X_train și y_train) sunt montate pe clasificator pentru a construi modelul. În timpul acestui proces de instruire, clasificatorul trece prin mai multe metode de optimizare, cum ar fi Gradient Descent și Backpropagation și în cele din urmă construiește modelul Decision Tree Classifier.

Pasul 5: Prezicerea rezultatelor setului de testare
Deoarece avem modelul pregătit, nu ar trebui să-i verificăm acuratețea pe setul de testare? Acest pas implică testarea modelului construit folosind algoritmul arborelui de decizie pe setul de testare care a fost împărțit mai devreme. Aceste rezultate sunt stocate într-o variabilă, „y_pred”.
![]()
Pasul 6: Compararea valorilor reale cu valorile prezise
Acesta este un alt pas simplu, în care vom construi un alt cadru de date simplu care va consta din două coloane, valorile reale ale setului de test pe de o parte și valorile prezise pe cealaltă parte. Acest pas ne permite să comparăm rezultatele obținute prin modelul construit.
![]()
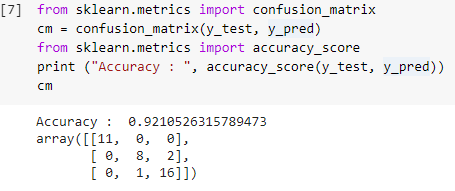
Pasul 7: Matricea confuziei și acuratețea
Acum că avem atât valorile reale, cât și cele prezise ale setului de test, haideți să construim o matrice simplă de clasificare și să calculăm acuratețea modelului nostru construit folosind funcții simple de bibliotecă din sklearn. Scorul de precizie este calculat prin introducerea atât a valorilor reale, cât și a celor prezise ale setului de testare. Modelul construit folosind pașii de mai sus ne oferă o precizie de 92,1% care este notă ca 0,92105 în pasul de mai jos.
Matricea de confuzie este un tabel care este folosit pentru a arăta predicțiile corecte și incorecte asupra unei probleme de clasificare. Pentru o utilizare simplă, valorile de pe diagonală reprezintă predicțiile corecte, iar celelalte valori din afara diagonalei sunt predicții incorecte.
La calcularea numărului din 38 de puncte de date seturi de testare, obținem 35 de predicții corecte și 3 predicții incorecte, care sunt reflectate ca 92% precise. Precizia poate fi îmbunătățită prin optimizarea hiperparametrilor care pot fi dați ca argumente clasificatorului înainte de antrenamentul modelului.
Pasul 8: Vizualizarea clasificatorului arborelui de decizie
În sfârșit, în ultimul pas vom vizualiza Arborele de decizie construit. La observarea nodului rădăcină, se vede că numărul de „probe” este 112, care sunt sincronizate cu eșantioanele setului de antrenament împărțite înainte. Indicele GINI este calculat în timpul fiecărei etape a algoritmului arborelui de decizie și cele 3 clase sunt împărțite așa cum se arată în parametrul „valoare” din arborele de decizie.

Trebuie citit: Întrebări și răspunsuri la interviu în arborele decizional
Concluzie
Prin urmare, în acest fel, am înțeles conceptul de algoritm Arborele de decizie și am construit un Clasificator simplu pentru a rezolva o problemă de clasificare folosind acest algoritm.
Dacă sunteți interesat să aflați mai multe despre arbori de decizie, învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și sarcini. , statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Care sunt dezavantajele utilizării arborilor de decizie?
În timp ce arborii de decizie ajută la clasificarea sau sortarea datelor, utilizarea lor creează uneori și câteva probleme. Adesea, arborii de decizie duc la supraadaptarea datelor, ceea ce face ca rezultatul final să fie extrem de inexact. În cazul seturilor de date mari, utilizarea unui singur arbore de decizie nu este recomandată deoarece provoacă complexitate. De asemenea, arborii de decizie sunt foarte instabili, ceea ce înseamnă că, dacă provocați o mică modificare în setul de date dat, structura arborelui de decizie se schimbă foarte mult.
Cum funcționează un algoritm de pădure aleatoare?
O pădure aleatorie este în esență o colecție de arbori de decizie diverși, la fel cum o pădure este formată din mulți copaci. Rezultatele algoritmului forestier aleatoriu depind de fapt de predicțiile arborilor de decizie. Tehnica pădurii aleatoare minimizează, de asemenea, probabilitatea de supraajustare a datelor. Pentru a obține rezultatul necesar, clasificarea aleatorie a pădurilor folosește o abordare de ansamblu. Datele de antrenament sunt folosite pentru a antrena diferiți arbori de decizie. Când nodurile sunt separate, acest set de date conține observații și atribute care vor fi alese la întâmplare.
Cum este un tabel de decizie diferit de un arbore de decizie?
Un tabel de decizie poate fi produs dintr-un arbore de decizie, dar nu invers. Un arbore de decizie este format din noduri și ramuri, în timp ce un tabel de decizie este format din rânduri și coloane. În tabelele de decizie pot fi introduse mai multe sau condiții. În arborii de decizie, acesta nu este cazul. Tabelele de decizie sunt utile numai atunci când sunt prezentate doar câteva proprietăți; arborii de decizie, pe de altă parte, pot fi utilizați eficient cu un număr mare de proprietăți și o logică sofisticată.