
Exemple d'arbre de décision : fonction et mise en œuvre [étape par étape]
Publié: 2020-12-28Table des matières
introduction
Les arbres de décision sont l'un des algorithmes les plus puissants et les plus populaires pour les tâches de régression et de classification. Ils sont une structure de type organigramme et relèvent de la catégorie des algorithmes supervisés. La capacité des arbres de décision à être visualisés comme un organigramme leur permet d'imiter facilement le niveau de réflexion des humains et c'est la raison pour laquelle ces arbres de décision sont facilement compris et interprétés.
Qu'est-ce qu'un arbre de décision ?
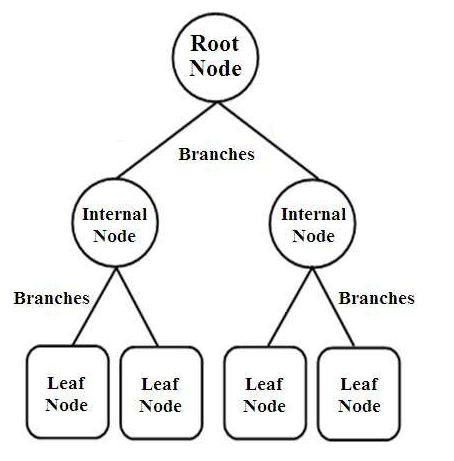
Les arbres de décision sont un type de classificateurs structurés en arbre. Ils ont trois types de nœuds qui sont,
- Nœuds racine
- Nœuds internes
- Nœuds feuilles
Source des images
Les nœuds racine sont les nœuds principaux qui représentent l'ensemble de l'échantillon qui est ensuite divisé en plusieurs autres nœuds. Les nœuds internes représentent le test sur un attribut tandis que les branches représentent la décision du test. Enfin, les nœuds feuilles désignent la classe de l'étiquette, qui est la décision prise après la compilation de tous les attributs. En savoir plus sur l'apprentissage par arbre de décision.
Comment fonctionnent les arbres de décision ?
Les arbres de décision sont utilisés dans la classification en les triant dans toute la structure arborescente du nœud racine au nœud feuille. Cette approche utilisée par l'arbre de décision est appelée approche descendante. Une fois qu'un point de données particulier est introduit dans l'arbre de décision, il est amené à traverser chaque nœud de l'arbre en répondant aux questions Oui/Non jusqu'à ce qu'il atteigne le nœud feuille désigné particulier.
Chaque nœud de l'arbre de décision représente un cas de test pour un attribut et chaque descente (branche) vers un nouveau nœud correspond à l'une des réponses possibles à ce cas de test. Ainsi, avec plusieurs itérations, l'arbre de décision prédit une valeur pour la tâche de régression ou classe l'objet dans une tâche de classification.

Mise en œuvre de l'arbre de décision
Maintenant que nous avons les bases d'un arbre de décision, passons en revue son exécution en programmation Python.
Analyse du problème
Dans l'exemple suivant, nous allons utiliser le célèbre jeu de données "Iris Flower". Publié à l'origine en 1936 au UCI Machine Learning Repository, (Lien : https://archive.ics.uci.edu/ml/datasets/Iris ), ce petit ensemble de données est largement utilisé pour tester les algorithmes d'apprentissage automatique et les visualisations.
En cela, il y a un total de 150 lignes et 5 colonnes dont 4 colonnes sont les attributs ou caractéristiques et la dernière colonne est le type d'espèce de fleur d'Iris. Iris est un genre de plantes à fleurs en botanique. Les quatre attributs en cm sont,
- Longueur des sépales
- Largeur de sépale
- Longueur des pétales
- Largeur des pétales
Ces quatre caractéristiques sont utilisées pour définir et classer le type de fleur d'iris en fonction de la taille et de la forme. La 5ème ou la dernière colonne se compose de la classe de fleurs Iris, qui sont Iris Setosa, Iris Versicolor et Iris Virginica.
Pour notre problème, nous devons créer un modèle d'apprentissage automatique utilisant l'algorithme d'arbre de décision pour apprendre les fonctionnalités et les classer en fonction de la classe de fleurs Iris.
Passons en revue son implémentation en python, étape par étape :
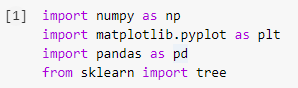
Étape 1 : Importation des bibliothèques
La première étape de la construction de tout modèle d'apprentissage automatique en Python consistera à importer les bibliothèques nécessaires telles que Numpy, Pandas et Matplotlib. Le module d'arbre est importé de la bibliothèque sklearn pour visualiser le modèle d'arbre de décision à la fin.
Étape 2 : Importer le jeu de données
Une fois que nous avons importé le jeu de données Iris, nous stockons le fichier .csv dans un Pandas DataFrame à partir duquel nous pouvons facilement accéder aux colonnes et aux lignes du tableau. Les quatre premières colonnes de la trame de données sont les variables indépendantes ou les caractéristiques qui doivent être comprises par le classificateur d'arbre de décision et sont stockées dans la variable X.
La variable dépendante qui est la classe de fleurs Iris composée de 3 espèces est stockée dans la variable y. Le jeu de données est visualisé en imprimant les 5 premières lignes.

Lire aussi : Classification de l'arbre de décision
Étape 3 : Diviser l'ensemble de données en ensemble d'apprentissage et en ensemble de test
Dans l'étape suivante, après avoir lu l'ensemble de données, nous devons diviser l'ensemble de données en l'ensemble d'apprentissage, à l'aide duquel le modèle de classificateur sera formé et l'ensemble de test, sur lequel le modèle formé sera implémenté. Les résultats obtenus sur l'ensemble de test seront comparés pour vérifier l'exactitude du modèle entraîné.

Ici, nous avons utilisé une taille de test de 0,25, ce qui signifie que 25 % de l'ensemble de données complet seront répartis de manière aléatoire en tant qu'ensemble de test et que les 75 % restants seront constitués de l'ensemble d'apprentissage à utiliser pour l'apprentissage du modèle. Par conséquent, sur 150 points de données, 38 points de données aléatoires sont retenus comme ensemble de test et les 112 échantillons restants sont utilisés dans l'ensemble d'apprentissage.

Étape 4 : Entraînement du modèle de classification d'arbre de décision sur l'ensemble d'entraînement
Une fois que le modèle a été divisé et est prêt pour la formation, le module DecisionTreeClassifier est importé de la bibliothèque sklearn et les variables de formation (X_train et y_train) sont ajustées sur le classificateur pour construire le modèle. Au cours de ce processus de formation, le classificateur subit plusieurs méthodes d'optimisation telles que la descente de gradient et la rétropropagation et construit finalement le modèle de classificateur d'arbre de décision.

Étape 5 : Prédire les résultats de l'ensemble de test
Comme nous avons notre modèle prêt, ne devrions-nous pas vérifier sa précision sur l'ensemble de test ? Cette étape implique le test du modèle construit à l'aide de l'algorithme d'arbre de décision sur l'ensemble de test qui a été divisé précédemment. Ces résultats sont stockés dans une variable, "y_pred".
![]()
Étape 6 : Comparer les valeurs réelles avec les valeurs prédites
Il s'agit d'une autre étape simple, où nous allons construire une autre base de données simple qui sera composée de deux colonnes, les valeurs réelles de l'ensemble de test d'un côté et les valeurs prédites de l'autre côté. Cette étape nous permet de comparer les résultats obtenus par le modèle construit.
![]()
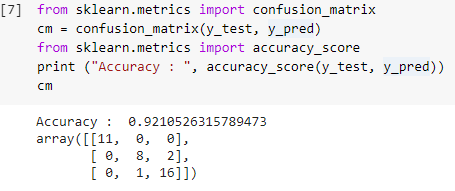
Étape 7 : Matrice de confusion et précision
Maintenant que nous avons à la fois les valeurs réelles et prédites des ensembles de tests, construisons une matrice de classification simple et calculons la précision de notre modèle construit à l'aide de fonctions de bibliothèque simples dans sklearn. Le score de précision est calculé en saisissant à la fois les valeurs réelles et prédites de l'ensemble de test. Le modèle construit en utilisant les étapes ci-dessus nous donne une précision de 92,1% qui est notée 0,92105 dans l'étape ci-dessous.
La matrice de confusion est un tableau utilisé pour montrer les prédictions correctes et incorrectes sur un problème de classification. Pour une utilisation simple, les valeurs sur la diagonale représentent les prédictions correctes et les autres valeurs en dehors de la diagonale sont des prédictions incorrectes.
En calculant le nombre à partir de 38 points de données de test, nous obtenons 35 prédictions correctes et 3 prédictions incorrectes, qui sont considérées comme exactes à 92 %. La précision peut être améliorée en optimisant les hyperparamètres qui peuvent être donnés comme arguments au classificateur avant de former le modèle.
Étape 8 : Visualiser le classificateur d'arbre de décision
Enfin, dans la dernière étape, nous visualiserons l'arbre de décision construit. En remarquant le nœud racine, on voit que le nombre d '«échantillons» est de 112, qui sont synchronisés avec les échantillons de l'ensemble d'apprentissage divisés auparavant. L'indice GINI est calculé à chaque étape de l'algorithme de l'arbre de décision et les 3 classes sont réparties comme indiqué dans le paramètre "valeur" de l'arbre de décision.

Doit lire: Questions et réponses de l'entretien sur l'arbre de décision
Conclusion
Par conséquent, de cette manière, nous avons compris le concept d'algorithme d'arbre de décision et avons construit un classificateur simple pour résoudre un problème de classification à l'aide de cet algorithme.
Si vous souhaitez en savoir plus sur les arbres de décision, l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions. , statut IIIT-B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Quels sont les inconvénients de l'utilisation d'arbres de décision ?
Alors que les arbres de décision aident à la classification ou au tri des données, leur utilisation crée parfois aussi quelques problèmes. Souvent, les arbres de décision conduisent à un surajustement des données, ce qui rend encore plus le résultat final très imprécis. Dans le cas de grands ensembles de données, l'utilisation d'un arbre de décision unique n'est pas recommandée car cela entraîne de la complexité. De plus, les arbres de décision sont très instables, ce qui signifie que si vous provoquez un petit changement dans l'ensemble de données donné, la structure de l'arbre de décision change considérablement.
Comment fonctionne un algorithme de forêt aléatoire ?
Une forêt aléatoire est essentiellement une collection d'arbres de décision divers, tout comme une forêt est composée de nombreux arbres. Les résultats de l'algorithme de forêt aléatoire dépendent en fait des prédictions des arbres de décision. La technique de la forêt aléatoire minimise également la probabilité de surajustement des données. Pour obtenir le résultat requis, la classification aléatoire des forêts utilise une approche d'ensemble. Les données de formation sont utilisées pour former divers arbres de décision. Lorsque les nœuds sont séparés, cet ensemble de données contient des observations et des attributs qui seront choisis au hasard.
En quoi une table de décision est-elle différente d'un arbre de décision ?
Une table de décision peut être produite à partir d'un arbre de décision, mais pas l'inverse. Un arbre de décision est composé de nœuds et de branches, tandis qu'une table de décision est composée de lignes et de colonnes. Dans les tables de décision, plusieurs conditions ou peuvent être insérées. Dans les arbres de décision, ce n'est pas le cas. Les tables de décision ne sont utiles que lorsque seules quelques propriétés sont présentées ; les arbres de décision, en revanche, peuvent être utilisés efficacement avec un grand nombre de propriétés et une logique sophistiquée.