
의사결정 트리 예: 기능 및 구현 [단계별]
게시 됨: 2020-12-28목차
소개
의사 결정 트리는 회귀 및 분류 작업 모두에 대해 가장 강력하고 널리 사용되는 알고리즘 중 하나입니다. 그들은 구조와 같은 순서도이며 감독 알고리즘 범주에 속합니다. 의사결정나무가 플로우차트처럼 시각화되는 능력은 인간의 사고 수준을 쉽게 모방할 수 있게 하고 이것이 이러한 의사결정나무를 쉽게 이해하고 해석하는 이유입니다.
의사결정나무란?
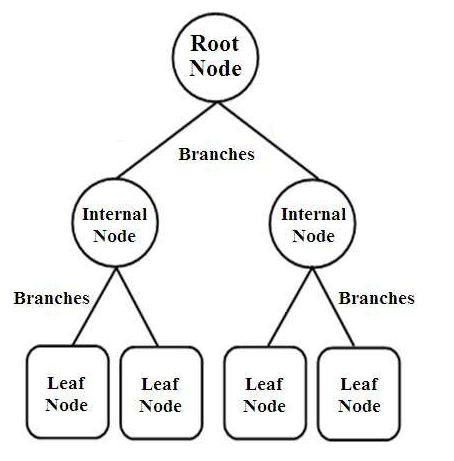
의사 결정 트리는 트리 구조의 분류기 유형입니다. 세 가지 유형의 노드가 있습니다.
- 루트 노드
- 내부 노드
- 리프 노드
이미지 소스
루트 노드는 여러 다른 노드로 더 분할되는 전체 샘플을 나타내는 기본 노드입니다. 내부 노드는 속성에 대한 테스트를 나타내는 반면 분기는 테스트의 결정을 나타냅니다. 마지막으로 리프 노드는 모든 속성을 컴파일한 후 결정되는 레이블의 클래스를 나타냅니다. 의사 결정 트리 학습에 대해 자세히 알아보십시오.
의사결정나무는 어떻게 작동합니까?
결정 트리는 루트 노드에서 리프 노드까지 전체 트리 구조를 정렬하여 분류에 사용됩니다. 의사 결정 트리에서 사용하는 이러한 접근 방식을 하향식 접근 방식이라고 합니다. 특정 데이터 포인트가 의사결정 트리에 입력되면 지정된 특정 리프 노드에 도달할 때까지 예/아니오 질문에 답하여 트리의 모든 노드를 통과하도록 합니다.
결정 트리의 각 노드는 속성에 대한 테스트 케이스를 나타내며 새 노드로의 각 하강(분기)은 해당 테스트 케이스에 대한 가능한 답변 중 하나에 해당합니다. 이러한 방식으로 여러 번의 반복을 통해 의사 결정 트리는 회귀 작업의 값을 예측하거나 분류 작업에서 개체를 분류합니다.

의사결정 트리 구현
이제 의사 결정 트리의 기본 사항이 있으므로 Python 프로그래밍에서 실행을 살펴보겠습니다.
문제 분석
다음 예제에서는 유명한 "Iris Flower" 데이터 세트를 사용할 것입니다. 1936년 UCI Machine Learning Repository(링크: https://archive.ics.uci.edu/ml/datasets/Iris )에 처음 게시된 이 작은 데이터 세트는 기계 학습 알고리즘 및 시각화를 테스트하는 데 널리 사용됩니다.
여기에는 총 150개의 행과 5개의 열이 있으며 그 중 4개의 열은 속성 또는 특징이고 마지막 열은 붓꽃의 종류입니다. 아이리스는 식물학에서 꽃 피는 식물의 속입니다. cm의 네 가지 속성은 다음과 같습니다.
- 꽃받침 길이
- 꽃받침 너비
- 꽃잎 길이
- 꽃잎 폭
이 4가지 특징은 창포꽃의 크기와 모양에 따라 꽃창포의 종류를 정의하고 분류하는 데 사용됩니다. 다섯 번째 또는 마지막 열은 Iris Setosa, Iris Versicolor 및 Iris Virginica인 Iris 꽃 클래스로 구성됩니다.
우리 문제의 경우, 특징을 학습하고 Iris 꽃 클래스를 기반으로 분류하기 위해 Decision Tree Algorithm을 사용하는 Machine Learning 모델을 구축해야 합니다.
Python으로 구현하는 과정을 단계별로 살펴보겠습니다.
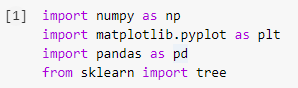
1단계: 라이브러리 가져오기
Python에서 기계 학습 모델을 구축하는 첫 번째 단계는 Numpy, Pandas 및 Matplotlib와 같은 필요한 라이브러리를 가져오는 것입니다. sklearn 라이브러리에서 tree 모듈을 가져와서 마지막에 Decision Tree 모델을 시각화합니다.
2단계: 데이터세트 가져오기
Iris 데이터 세트를 가져온 후에는 .csv 파일을 Pandas DataFrame에 저장하여 테이블의 열과 행에 쉽게 액세스할 수 있습니다. 데이터 프레임의 처음 4개 열은 독립 변수 또는 의사 결정 트리 분류자가 이해해야 하고 변수 X에 저장되는 기능입니다.
변수 y에는 3종으로 구성된 붓꽃 종류인 종속변수가 저장된다. 데이터 세트는 처음 5개 행을 인쇄하여 시각화됩니다.

더 읽어보기: 의사결정나무 분류

3단계: 데이터 세트를 훈련 세트와 테스트 세트로 분할
다음 단계에서는 데이터 세트를 읽은 후 전체 데이터 세트를 분류기 모델이 훈련될 훈련 세트와 훈련된 모델이 구현될 테스트 세트로 분할해야 합니다. 테스트 세트에서 얻은 결과는 훈련된 모델의 정확성을 확인하기 위해 비교됩니다.
여기에서 우리는 0.25의 테스트 크기를 사용했는데, 이는 전체 데이터 세트의 25%가 테스트 세트로 무작위로 분할되고 나머지 75%는 모델 훈련에 사용할 훈련 세트로 구성됨을 나타냅니다. 따라서 150개의 데이터 포인트 중 38개의 임의 데이터 포인트가 테스트 세트로 유지되고 나머지 112개 샘플은 훈련 세트에서 사용됩니다.

4단계: 훈련 세트에서 의사결정나무 분류 모델 훈련
모델이 분할되고 훈련 목적으로 준비되면 sklearn 라이브러리에서 DecisionTreeClassifier 모듈을 가져오고 훈련 변수(X_train 및 y_train)를 분류기에 맞춰 모델을 빌드합니다. 이 훈련 과정에서 분류기는 Gradient Descent 및 Backpropagation과 같은 여러 최적화 방법을 거쳐 최종적으로 의사 결정 트리 분류기 모델을 구축합니다.

5단계: 테스트 세트 결과 예측
모델이 준비되었으므로 테스트 세트에서 정확성을 확인해야 하지 않습니까? 이 단계에는 이전에 분할된 테스트 세트에서 의사결정 트리 알고리즘을 사용하여 구축된 모델의 테스트가 포함됩니다. 이 결과는 "y_pred"라는 변수에 저장됩니다.
![]()
6단계: 실제 값과 예측 값 비교
이것은 두 개의 열로 구성되는 또 다른 간단한 데이터 프레임을 만드는 또 다른 간단한 단계입니다. 한쪽에는 테스트 세트의 실제 값이 있고 다른쪽에는 예측 값이 있습니다. 이 단계를 통해 구축된 모델에서 얻은 결과를 비교할 수 있습니다.
![]()
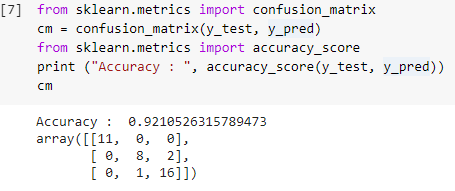
7단계: 혼동 매트릭스 및 정확도
이제 테스트 세트의 실제 값과 예측 값이 모두 있으므로 간단한 분류 행렬을 만들고 sklearn 내에서 간단한 라이브러리 함수를 사용하여 빌드한 모델의 정확도를 계산해 보겠습니다. 정확도 점수는 테스트 세트의 실제 값과 예측 값을 모두 입력하여 계산됩니다. 위의 단계를 사용하여 구축된 모델은 아래 단계에서 0.92105로 표시된 92.1%의 정확도를 제공합니다.
정오분류표는 분류 문제에 대한 올바른 예측과 잘못된 예측을 표시하는 데 사용되는 테이블입니다. 간단한 사용법의 경우 대각선의 값은 올바른 예측을 나타내고 대각선 외부의 다른 값은 잘못된 예측을 나타냅니다.
38개의 테스트 세트 데이터 포인트에서 수를 계산할 때 35개의 올바른 예측과 3개의 잘못된 예측을 얻었으며 이는 92%의 정확도로 반영됩니다. 모델을 훈련하기 전에 분류기에 인수로 제공할 수 있는 하이퍼파라미터를 최적화하여 정확도를 향상시킬 수 있습니다.
8단계: 의사결정 트리 분류기 시각화
마지막으로, 마지막 단계에서 구축된 의사결정나무를 시각화할 것입니다. 루트 노드를 보면 "샘플"의 수가 112개임을 알 수 있으며 이는 이전에 분할된 훈련 세트 샘플과 동기화됩니다. GINI 지수는 의사결정 트리 알고리즘의 각 단계에서 계산되며 의사결정 트리의 "값" 매개변수에 표시된 대로 3개의 클래스가 분할됩니다.

반드시 읽어야 함: 의사결정나무 인터뷰 질문 및 답변
결론
따라서 우리는 이와 같이 Decision Tree 알고리즘의 개념을 이해하고 이 알고리즘을 사용하여 분류 문제를 해결하기 위해 간단한 분류기를 구축했습니다.
의사 결정 트리, 기계 학습에 대해 자세히 알아보려면 작업 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제를 제공하는 IIIT-B & upGrad의 기계 학습 및 AI PG 디플로마를 확인하십시오. , IIIT-B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
의사 결정 트리를 사용하면 어떤 단점이 있습니까?
의사 결정 트리는 데이터의 분류 또는 정렬에 도움이 되지만 사용하면 몇 가지 문제가 발생하기도 합니다. 종종 의사 결정 트리는 데이터의 과적합으로 이어져 최종 결과가 매우 부정확해집니다. 데이터 세트가 큰 경우 단일 의사 결정 트리를 사용하면 복잡성이 발생하므로 권장하지 않습니다. 또한 의사결정나무는 매우 불안정하기 때문에 주어진 데이터세트에 작은 변화를 일으키면 의사결정나무의 구조가 크게 바뀝니다.
랜덤 포레스트 알고리즘은 어떻게 작동합니까?
랜덤 포레스트는 포리스트가 많은 트리로 구성된 것처럼 본질적으로 다양한 의사결정 트리의 모음입니다. 랜덤 포레스트 알고리즘의 결과는 실제로 의사 결정 트리의 예측에 따라 다릅니다. 랜덤 포레스트 기법은 또한 데이터 과적합의 가능성을 최소화합니다. 필요한 결과를 얻기 위해 랜덤 포레스트 분류는 앙상블 접근 방식을 사용합니다. 훈련 데이터는 다양한 의사 결정 트리를 훈련하는 데 사용됩니다. 노드가 분리되면 이 데이터 세트에는 무작위로 선택되는 관찰 및 속성이 포함됩니다.
의사결정 테이블은 의사결정 트리와 어떻게 다릅니까?
의사결정 테이블은 의사결정 트리에서 생성될 수 있지만 그 반대는 아닙니다. 의사결정 트리는 노드와 분기로 구성되는 반면 의사결정 테이블은 행과 열로 구성됩니다. 의사결정 테이블에서 둘 이상의 조건을 삽입할 수 있습니다. 의사 결정 트리에서는 그렇지 않습니다. 의사결정 테이블은 몇 가지 속성만 표시되는 경우에만 유용합니다. 반면에 의사 결정 트리는 많은 속성과 정교한 논리와 함께 효과적으로 사용할 수 있습니다.