
Contoh Pohon Keputusan: Fungsi & Implementasi [Langkah demi langkah]
Diterbitkan: 2020-12-28Daftar isi
pengantar
Pohon Keputusan adalah salah satu algoritma yang paling kuat dan populer untuk kedua tugas regresi dan klasifikasi. Mereka adalah struktur seperti diagram alur dan termasuk dalam kategori algoritma yang diawasi. Kemampuan pohon keputusan untuk divisualisasikan seperti diagram alur memungkinkan mereka untuk dengan mudah meniru tingkat pemikiran manusia dan inilah alasan mengapa pohon keputusan ini mudah dipahami dan ditafsirkan.
Apa itu Pohon Keputusan?
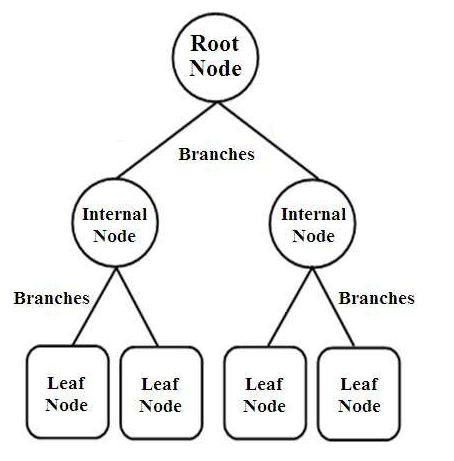
Pohon Keputusan adalah jenis pengklasifikasi terstruktur pohon. Mereka memiliki tiga jenis node yaitu,
- Node Akar
- Node Internal
- simpul daun
Sumber Gambar
Node Root adalah node utama yang mewakili seluruh sampel yang selanjutnya dibagi menjadi beberapa node lainnya. Node internal mewakili pengujian pada atribut sedangkan cabang mewakili keputusan pengujian. Akhirnya, simpul daun menunjukkan kelas label, yang merupakan keputusan yang diambil setelah kompilasi semua atribut. Pelajari lebih lanjut tentang pembelajaran pohon keputusan.
Bagaimana Pohon Keputusan bekerja?
Pohon keputusan digunakan dalam klasifikasi dengan menyortirnya ke seluruh struktur pohon dari simpul akar ke simpul daun. Pendekatan yang digunakan oleh pohon keputusan ini disebut sebagai pendekatan Top-Down. Setelah titik data tertentu dimasukkan ke dalam pohon keputusan, itu dibuat untuk melewati setiap simpul pohon dengan menjawab pertanyaan Ya/Tidak sampai mencapai simpul daun tertentu yang ditunjuk.
Setiap simpul di pohon keputusan mewakili kasus uji untuk atribut dan setiap penurunan (cabang) ke simpul baru sesuai dengan salah satu kemungkinan jawaban untuk kasus uji tersebut. Dengan cara ini, dengan beberapa iterasi, pohon keputusan memprediksi nilai untuk tugas regresi atau mengklasifikasikan objek dalam tugas klasifikasi.

Implementasi Pohon Keputusan
Sekarang setelah kita memiliki dasar-dasar pohon keputusan, mari kita lanjutkan eksekusinya dalam pemrograman Python.
Analisa masalah
Dalam contoh berikut kita akan menggunakan Dataset “Iris Flower” yang terkenal. Awalnya diterbitkan pada tahun 1936 di UCI Machine Learning Repository, (Tautan: https://archive.ics.uci.edu/ml/datasets/Iris ), kumpulan data kecil ini banyak digunakan untuk menguji algoritma dan visualisasi pembelajaran mesin.
Di dalamnya, ada total 150 baris dan 5 kolom di mana 4 kolom adalah atribut atau fitur dan kolom terakhir adalah jenis spesies bunga Iris. Iris adalah genus tanaman berbunga di botani. Empat atribut dalam cm adalah,
- Panjang Sepal
- Lebar Sepal
- Panjang kelopak
- Lebar kelopak
Keempat fitur ini digunakan untuk mendefinisikan dan mengklasifikasikan jenis bunga Iris tergantung pada ukuran dan bentuknya. Kolom ke- 5 atau terakhir terdiri dari kelas bunga Iris, yaitu Iris Setosa, Iris Versicolor dan Iris Virginica.
Untuk masalah kami, kami harus membangun model Machine Learning yang memanfaatkan Algoritma Pohon Keputusan untuk mempelajari fitur dan mengklasifikasikannya berdasarkan kelas bunga Iris.
Mari kita lihat implementasinya di python, langkah demi langkah:
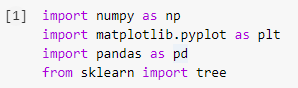
Langkah 1: Mengimpor perpustakaan
Langkah pertama dalam membangun model pembelajaran mesin apa pun dengan Python adalah mengimpor pustaka yang diperlukan seperti Numpy, Pandas, dan Matplotlib. Modul pohon diimpor dari perpustakaan sklearn untuk memvisualisasikan model Pohon Keputusan di akhir.
Langkah 2: Mengimpor kumpulan data
Setelah kami mengimpor dataset Iris, kami menyimpan file .csv ke dalam Pandas DataFrame dari mana kami dapat dengan mudah mengakses kolom dan baris tabel. Empat kolom pertama dari kerangka data adalah variabel independen atau fitur yang harus dipahami oleh pengklasifikasi pohon keputusan dan disimpan ke dalam variabel X.
Variabel terikat yaitu kelas bunga Iris yang terdiri dari 3 spesies disimpan ke dalam variabel y. Dataset divisualisasikan dengan mencetak 5 baris pertama.

Baca Juga : Klasifikasi Pohon Keputusan
Langkah 3: Memisahkan dataset menjadi Training set dan Test set
Pada langkah berikut, setelah membaca dataset, kita harus membagi seluruh dataset menjadi training set, yang menggunakan model classifier yang akan dilatih dan test set, di mana model yang dilatih akan diimplementasikan. Hasil yang diperoleh pada set uji akan dibandingkan untuk memeriksa keakuratan model yang dilatih.

Di sini, kami telah menggunakan ukuran pengujian 0,25, yang menunjukkan bahwa 25% dari seluruh kumpulan data akan dibagi secara acak sebagai kumpulan pengujian dan 75% sisanya akan terdiri dari kumpulan pelatihan yang akan digunakan dalam pelatihan model. Oleh karena itu, dari 150 titik data, 38 titik data acak dipertahankan sebagai set uji dan 112 sampel sisanya digunakan dalam set pelatihan.

Langkah 4: Melatih model Klasifikasi Pohon Keputusan pada Set Pelatihan
Setelah model dipecah dan siap untuk tujuan pelatihan, modul DecisionTreeClassifier diimpor dari perpustakaan sklearn dan variabel pelatihan (X_train dan y_train) dipasang pada classifier untuk membangun model. Selama proses pelatihan ini, classifier mengalami beberapa metode optimasi seperti Gradient Descent dan Backpropagation dan terakhir membangun model Decision Tree Classifier.

Langkah 5: Memprediksi Hasil Set Tes
Karena model kita sudah siap, tidakkah kita harus memeriksa keakuratannya pada set pengujian? Langkah ini melibatkan pengujian model yang dibangun menggunakan algoritma pohon keputusan pada set pengujian yang telah dipecah sebelumnya. Hasil ini disimpan dalam variabel, "y_pred".
![]()
Langkah 6: Membandingkan Nilai Nyata dengan Nilai Prediksi
Ini adalah langkah sederhana lainnya, di mana kita akan membangun kerangka data sederhana lainnya yang akan terdiri dari dua kolom, nilai sebenarnya dari kumpulan tes di satu sisi dan nilai prediksi di sisi lain. Langkah ini memungkinkan kita untuk membandingkan hasil yang diperoleh dari model yang dibangun.
![]()
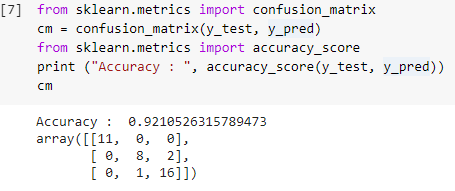
Langkah 7: Matriks Kebingungan dan Akurasi
Sekarang setelah kita memiliki nilai nyata dan nilai prediksi dari set pengujian, mari kita buat matriks klasifikasi sederhana dan hitung akurasi model yang dibangun menggunakan fungsi pustaka sederhana di dalam sklearn. Skor akurasi dihitung dengan memasukkan nilai nyata dan nilai prediksi dari set tes. Model yang dibangun menggunakan langkah-langkah di atas memberi kita akurasi 92,1% yang dilambangkan sebagai 0,92105 pada langkah di bawah ini.
Confusion matrix adalah tabel yang digunakan untuk menunjukkan prediksi yang benar dan salah pada suatu masalah klasifikasi. Untuk penggunaan sederhana, nilai di seberang diagonal mewakili prediksi yang benar dan nilai lain di luar diagonal adalah prediksi yang salah.
Saat menghitung jumlah dari 38 titik data set pengujian, kami mendapatkan 35 prediksi yang benar dan 3 prediksi yang salah, yang dicerminkan sebagai 92% akurat. Akurasi dapat ditingkatkan dengan mengoptimalkan hyperparameter yang dapat diberikan sebagai argumen ke classifier sebelum melatih model.
Langkah 8: Memvisualisasikan Pengklasifikasi Pohon Keputusan
Akhirnya, pada langkah terakhir kita akan memvisualisasikan Pohon Keputusan yang dibangun. Saat melihat node root, terlihat bahwa jumlah “sampel” adalah 112, yang sinkron dengan sampel set pelatihan yang dibagi sebelumnya. Indeks GINI dihitung selama setiap langkah algoritma pohon keputusan dan 3 kelas dibagi seperti yang ditunjukkan pada parameter "nilai" di pohon keputusan.

Harus Dibaca: Pertanyaan & Jawaban Wawancara Pohon Keputusan
Kesimpulan
Oleh karena itu, dengan cara ini, kami telah memahami konsep algoritma Pohon Keputusan dan telah membangun Pengklasifikasi sederhana untuk menyelesaikan masalah klasifikasi menggunakan algoritma ini.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pohon keputusan, pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas , Status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa kerugian menggunakan pohon keputusan?
Sementara pohon keputusan membantu dalam klasifikasi atau pengurutan data, penggunaannya terkadang menimbulkan beberapa masalah juga. Seringkali, pohon keputusan menyebabkan overfitting data, yang selanjutnya membuat hasil akhir menjadi sangat tidak akurat. Dalam kasus kumpulan data yang besar, penggunaan pohon keputusan tunggal tidak dianjurkan karena menyebabkan kompleksitas. Juga, pohon keputusan sangat tidak stabil, yang berarti bahwa jika Anda menyebabkan perubahan kecil pada kumpulan data yang diberikan, struktur pohon keputusan akan sangat berubah.
Bagaimana cara kerja algoritma hutan acak?
Hutan acak pada dasarnya adalah kumpulan pohon keputusan yang beragam, sama seperti hutan yang terdiri dari banyak pohon. Hasil algoritma hutan acak sebenarnya tergantung pada prediksi pohon keputusan. Teknik hutan acak juga meminimalkan kemungkinan data yang terlalu pas. Untuk mendapatkan hasil yang diinginkan, klasifikasi hutan secara acak menggunakan pendekatan ensemble. Data pelatihan digunakan untuk melatih berbagai pohon keputusan. Ketika node dipisahkan, dataset ini berisi observasi dan atribut yang akan diambil secara acak.
Bagaimana tabel keputusan berbeda dari pohon keputusan?
Sebuah tabel keputusan dapat dihasilkan dari pohon keputusan, tetapi tidak sebaliknya. Sebuah pohon keputusan terdiri dari node dan cabang, sedangkan tabel keputusan terdiri dari baris dan kolom. Dalam tabel keputusan, lebih dari satu atau kondisi dapat dimasukkan. Dalam pohon keputusan, ini tidak terjadi. Tabel keputusan hanya berguna ketika hanya beberapa properti yang disajikan; pohon keputusan, di sisi lain, dapat digunakan secara efektif dengan sejumlah besar properti dan logika yang canggih.