
Beispiel Entscheidungsbaum: Funktion & Umsetzung [Schritt für Schritt]
Veröffentlicht: 2020-12-28Inhaltsverzeichnis
Einführung
Entscheidungsbäume sind einer der leistungsstärksten und beliebtesten Algorithmen für Regressions- und Klassifizierungsaufgaben. Sie sind eine Flussdiagramm-ähnliche Struktur und fallen unter die Kategorie der überwachten Algorithmen. Die Fähigkeit der Entscheidungsbäume, wie ein Flussdiagramm visualisiert zu werden, ermöglicht es ihnen, die Denkebene des Menschen leicht nachzuahmen, und das ist der Grund, warum diese Entscheidungsbäume leicht zu verstehen und zu interpretieren sind.
Was ist ein Entscheidungsbaum?
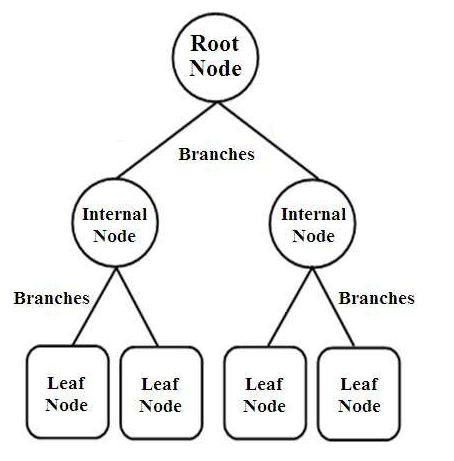
Entscheidungsbäume sind eine Art von baumstrukturierten Klassifikatoren. Sie haben drei Arten von Knoten, nämlich
- Wurzelknoten
- Interne Knoten
- Blattknoten
Bildquelle
Die Root-Knoten sind die primären Knoten, die die gesamte Stichprobe darstellen, die weiter in mehrere andere Knoten aufgeteilt wird. Die internen Knoten stellen den Test auf ein Attribut dar, während die Zweige die Entscheidung des Tests darstellen. Schließlich bezeichnen die Blattknoten die Klasse des Etiketts, was die Entscheidung ist, die nach der Zusammenstellung aller Attribute getroffen wird. Erfahren Sie mehr über das Lernen von Entscheidungsbäumen.
Wie funktionieren Entscheidungsbäume?
Die Entscheidungsbäume werden bei der Klassifizierung verwendet, indem sie die gesamte Baumstruktur vom Wurzelknoten bis zum Blattknoten heruntersortiert werden. Dieser vom Entscheidungsbaum verwendete Ansatz wird als Top-Down-Ansatz bezeichnet. Sobald ein bestimmter Datenpunkt in den Entscheidungsbaum eingespeist wird, durchläuft er jeden einzelnen Knoten des Baums, indem Ja/Nein-Fragen beantwortet werden, bis er den bestimmten bezeichneten Blattknoten erreicht.
Jeder Knoten im Entscheidungsbaum stellt einen Testfall für ein Attribut dar und jeder Abstieg (Zweig) zu einem neuen Knoten entspricht einer der möglichen Antworten auf diesen Testfall. Auf diese Weise sagt der Entscheidungsbaum mit mehreren Iterationen einen Wert für die Regressionsaufgabe voraus oder klassifiziert das Objekt in einer Klassifizierungsaufgabe.

Entscheidungsbaum-Implementierung
Nachdem wir nun die Grundlagen eines Entscheidungsbaums kennen, wollen wir seine Ausführung in der Python-Programmierung durchgehen.
Problemanalyse
Im folgenden Beispiel verwenden wir den berühmten „Iris Flower“-Datensatz. Dieser kleine Datensatz wurde ursprünglich 1936 im UCI Machine Learning Repository (Link: https://archive.ics.uci.edu/ml/datasets/Iris ) veröffentlicht und wird häufig zum Testen von Algorithmen und Visualisierungen für maschinelles Lernen verwendet.
Darin gibt es insgesamt 150 Zeilen und 5 Spalten, von denen 4 Spalten die Attribute oder Merkmale sind und die letzte Spalte die Art der Iris-Blütenart ist. Iris ist eine Pflanzengattung in der Botanik. Die vier Attribute in cm sind:
- Kelchblattlänge
- Kelchblattbreite
- Blütenblattlänge
- Blütenblattbreite
Diese vier Merkmale werden verwendet, um die Art der Irisblüte je nach Größe und Form zu definieren und zu klassifizieren. Die 5. oder letzte Spalte besteht aus der Iris- Blumenklasse , die Iris Setosa, Iris Versicolor und Iris Virginica sind.
Für unser Problem müssen wir ein Modell für maschinelles Lernen erstellen, das den Entscheidungsbaumalgorithmus verwendet, um die Merkmale zu lernen und sie basierend auf der Iris-Blumenklasse zu klassifizieren.
Lassen Sie uns die Implementierung in Python Schritt für Schritt durchgehen:
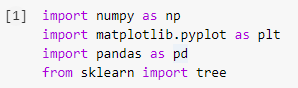
Schritt 1: Importieren der Bibliotheken
Der erste Schritt beim Erstellen eines Modells für maschinelles Lernen in Python besteht darin, die erforderlichen Bibliotheken wie Numpy, Pandas und Matplotlib zu importieren. Das Baummodul wird aus der sklearn-Bibliothek importiert, um das Entscheidungsbaummodell am Ende zu visualisieren.
Schritt 2: Importieren des Datensatzes
Nachdem wir den Iris-Datensatz importiert haben, speichern wir die .csv-Datei in einem Pandas DataFrame, von dem aus wir einfach auf die Spalten und Zeilen der Tabelle zugreifen können. Die ersten vier Spalten des Datenrahmens sind die unabhängigen Variablen oder die Merkmale, die vom Entscheidungsbaumklassifizierer verstanden werden sollen und in der Variablen X gespeichert werden.
Die abhängige Variable, die die Irisblütenklasse ist, die aus 3 Arten besteht, wird in der Variablen y gespeichert. Der Datensatz wird visualisiert, indem die ersten 5 Zeilen gedruckt werden.

Lesen Sie auch: Klassifizierung von Entscheidungsbäumen
Schritt 3: Aufteilen des Datensatzes in Trainingssatz und Testsatz
Im nächsten Schritt müssen wir nach dem Lesen des Datensatzes den gesamten Datensatz aufteilen in das Trainingsset, mit dem das Klassifikatormodell trainiert wird, und das Testset, auf dem das trainierte Modell implementiert wird. Die auf dem Testset erzielten Ergebnisse werden verglichen, um die Genauigkeit des trainierten Modells zu überprüfen.

Hier haben wir eine Testgröße von 0,25 verwendet, was bedeutet, dass 25 % des gesamten Datensatzes zufällig als Testsatz aufgeteilt werden und die restlichen 75 % aus dem Trainingssatz bestehen, der zum Trainieren des Modells verwendet wird. Daher werden von 150 Datenpunkten 38 zufällige Datenpunkte als Testsatz beibehalten und die verbleibenden 112 Proben werden im Trainingssatz verwendet.

Schritt 4: Trainieren des Entscheidungsbaum-Klassifizierungsmodells auf dem Trainingssatz
Sobald das Modell aufgeteilt wurde und für Trainingszwecke bereit ist, wird das DecisionTreeClassifier-Modul aus der sklearn-Bibliothek importiert und die Trainingsvariablen (X_train und y_train) werden an den Klassifikator angepasst, um das Modell zu erstellen. Während dieses Trainingsprozesses durchläuft der Klassifikator mehrere Optimierungsmethoden wie Gradient Descent und Backpropagation und baut schließlich das Entscheidungsbaum-Klassifikatormodell auf.

Schritt 5: Vorhersage der Ergebnisse der Testreihe
Da wir unser Modell fertig haben, sollten wir seine Genauigkeit nicht am Testgerät überprüfen? Dieser Schritt beinhaltet das Testen des Modells, das unter Verwendung des Entscheidungsbaumalgorithmus auf der zuvor aufgeteilten Testmenge erstellt wurde. Diese Ergebnisse werden in einer Variablen „y_pred“ gespeichert.
![]()
Schritt 6: Vergleich der realen Werte mit den vorhergesagten Werten
Dies ist ein weiterer einfacher Schritt, in dem wir einen weiteren einfachen Datenrahmen erstellen, der aus zwei Spalten besteht, den tatsächlichen Werten des Testsatzes auf der einen Seite und den vorhergesagten Werten auf der anderen Seite. Dieser Schritt ermöglicht es uns, die Ergebnisse des gebauten Modells zu vergleichen.
![]()
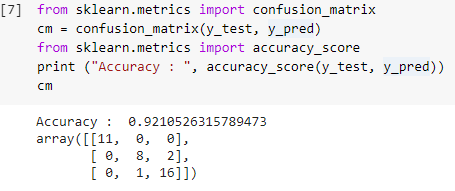
Schritt 7: Verwirrungsmatrix und Genauigkeit
Nachdem wir nun sowohl die tatsächlichen als auch die vorhergesagten Werte der Testsätze haben, lassen Sie uns eine einfache Klassifizierungsmatrix erstellen und die Genauigkeit unseres Modells berechnen, das mithilfe einfacher Bibliotheksfunktionen in sklearn erstellt wurde. Die Genauigkeitsbewertung wird berechnet, indem sowohl die tatsächlichen als auch die vorhergesagten Werte des Testsatzes eingegeben werden. Das mit den obigen Schritten erstellte Modell ergibt eine Genauigkeit von 92,1 %, die im folgenden Schritt als 0,92105 bezeichnet wird.
Die Konfusionsmatrix ist eine Tabelle, die verwendet wird, um die richtigen und falschen Vorhersagen zu einem Klassifizierungsproblem anzuzeigen. Für eine einfache Verwendung stellen die Werte über der Diagonale die richtigen Vorhersagen dar und die anderen Werte außerhalb der Diagonale sind falsche Vorhersagen.
Bei der Berechnung der Anzahl aus 38 Testdatenpunkten erhalten wir 35 richtige Vorhersagen und 3 falsche Vorhersagen, die zu 92 % genau sind. Die Genauigkeit kann verbessert werden, indem die Hyperparameter optimiert werden, die dem Klassifikator vor dem Trainieren des Modells als Argumente übergeben werden können.
Schritt 8: Visualisierung des Entscheidungsbaum-Klassifikators
Schließlich visualisieren wir im letzten Schritt den aufgebauten Entscheidungsbaum. Beim Betrachten des Wurzelknotens ist ersichtlich, dass die Anzahl der „Samples“ 112 beträgt, die mit den zuvor geteilten Samples des Trainingssatzes synchron sind. Der GINI-Index wird bei jedem Schritt des Entscheidungsbaumalgorithmus berechnet und die 3 Klassen werden aufgeteilt, wie im Parameter „Wert“ im Entscheidungsbaum gezeigt.

Muss gelesen werden: Fragen und Antworten zum Entscheidungsbaum-Interview
Fazit
Daher haben wir auf diese Weise das Konzept des Entscheidungsbaumalgorithmus verstanden und einen einfachen Klassifikator entwickelt, um ein Klassifizierungsproblem unter Verwendung dieses Algorithmus zu lösen.
Wenn Sie mehr über Entscheidungsbäume und maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet , IIIT-B-Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Was sind die Nachteile der Verwendung von Entscheidungsbäumen?
Entscheidungsbäume helfen zwar bei der Klassifizierung oder Sortierung von Daten, aber ihre Verwendung verursacht manchmal auch einige Probleme. Häufig führen Entscheidungsbäume zu einer Überanpassung von Daten, was das Endergebnis weiter sehr ungenau macht. Bei großen Datensätzen wird die Verwendung eines einzelnen Entscheidungsbaums nicht empfohlen, da dies zu Komplexität führt. Außerdem sind Entscheidungsbäume sehr instabil, was bedeutet, dass sich die Struktur des Entscheidungsbaums stark ändert, wenn Sie eine kleine Änderung im gegebenen Datensatz bewirken.
Wie funktioniert ein Random-Forest-Algorithmus?
Ein Random Forest ist im Wesentlichen eine Sammlung verschiedener Entscheidungsbäume, genau wie ein Wald aus vielen Bäumen besteht. Die Ergebnisse des Random-Forest-Algorithmus hängen tatsächlich von den Vorhersagen der Entscheidungsbäume ab. Die Random-Forest-Technik minimiert auch die Wahrscheinlichkeit einer Datenüberanpassung. Um das erforderliche Ergebnis zu erzielen, verwendet die Random-Forest-Klassifizierung einen Ensemble-Ansatz. Die Trainingsdaten werden verwendet, um verschiedene Entscheidungsbäume zu trainieren. Wenn Knoten getrennt werden, enthält dieser Datensatz Beobachtungen und Attribute, die zufällig ausgewählt werden.
Wie unterscheidet sich eine Entscheidungstabelle von einem Entscheidungsbaum?
Aus einem Entscheidungsbaum kann eine Entscheidungstabelle entstehen, aber nicht umgekehrt. Ein Entscheidungsbaum besteht aus Knoten und Zweigen, während eine Entscheidungstabelle aus Zeilen und Spalten besteht. In Entscheidungstabellen können mehr als eine oder-Bedingung eingefügt werden. Bei Entscheidungsbäumen ist dies nicht der Fall. Entscheidungstabellen sind nur nützlich, wenn nur wenige Eigenschaften präsentiert werden; Entscheidungsbäume hingegen können mit einer Vielzahl von Eigenschaften und ausgefeilter Logik effektiv eingesetzt werden.