
深度学习中的迁移学习【综合指南】
已发表: 2020-12-07目录
介绍
什么是深度学习? 它是机器学习的一个分支,它使用被称为神经网络的人脑模拟。 这些神经网络由类似于人脑基本单元的神经元组成。
神经元组成了一个神经网络模型,这个研究领域统称为深度学习。 神经网络的最终结果称为深度学习模型。 大多数情况下,在深度学习中,使用非结构化数据,深度学习模型通过对数据的重复训练来自行提取特征。
为一组特定数据设计的此类模型可用作开发具有不同数据集和特征的另一个模型的起点,称为迁移学习。 简单来说,迁移学习是一种流行的方法,其中为特定任务开发的模型再次用作为另一任务开发模型的起点。
迁移学习
自远古以来,人类就一直在使用迁移学习。 尽管迁移学习这个领域对于机器学习来说是相对较新的领域,但人类几乎在所有情况下都使用了这一点。
当我们面对新的问题或任务时,我们总是试图应用从过去的经验中获得的知识,这是迁移学习的基础。 例如,如果我们知道会骑自行车,并且当被要求骑我们以前没有做过的摩托车时,我们骑自行车的经验将始终应用于骑摩托车时,例如转向把手和平衡自行车。 这个简单的概念构成了迁移学习的基础。
为了理解迁移学习的基本概念,假设模型 X 已成功训练以使用模型 M1 执行任务 A。 如果任务 B 的数据集太小,导致模型 Y 无法有效训练或导致数据过拟合,我们可以使用模型 M1 的一部分作为基础构建模型 Y 来执行任务 B。

为什么迁移学习?
当今世界推广人工智能的先驱之一 Andrew Ng 表示,“迁移学习将成为机器学习成功的下一个驱动力”。 他在神经信息处理系统会议 (NIPS 2016) 上的一次演讲中提到了这一点。 毫无疑问,机器学习在当今行业的成功主要归功于监督学习。 另一方面,随着越来越多的无监督和未标记数据的发展,迁移学习将成为行业中广泛使用的一种技术。
如今,人们更喜欢使用已经在ImageNet等各种图像上训练过的预训练模型,而不是从头开始构建整个卷积神经网络模型。 迁移学习有几个好处,但主要优点是节省训练时间,神经网络性能更好,并且不需要大量数据。
阅读:顶级深度学习技术
迁移学习的方法
一般来说,有两种应用迁移学习的方法——一种是从头开始开发模型,另一种是使用预训练的模型。
在第一种情况下,我们通常根据训练数据构建模型架构,并通过几个统计参数仔细研究模型从模型中提取权重和模式的能力。 经过几轮训练后,根据结果,可能需要对模型进行一些更改以达到最佳性能。 通过这种方式,我们可以保存模型并将其用作为类似任务构建另一个模型的起点。
使用预训练模型的第二种情况通常最常被称为迁移学习。 在这方面,我们必须查找由几个研究机构和组织共享的预训练模型,这些模型和组织定期发布以供一般使用。 这些模型及其权重可在 Internet 上下载,并可用于为类似数据集构建模型。
迁移学习实现——VGG16 模型
让我们通过使用称为 VGG16 的预训练模型来了解迁移学习的应用。
VGG16是牛津大学教授于2014年发布的卷积神经网络模型,是当年赢得ILSVR(ImageNet)竞赛的著名模型之一。 它仍然被公认为最好的视觉模型架构之一。 它有 16 个权重层,包括 13 个卷积层、3 个全连接层和一个 soft max 层。 它有大约 1.38 亿个参数。 下面给出的是 VGG16 模型的架构。
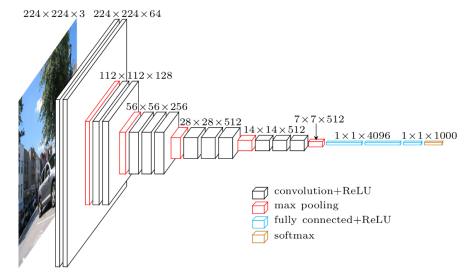
图片来源: https ://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7

第一步:第一步是导入TensorFlow框架中keras库提供的VGG16模型。
![]()
第 2 步:在下一步中,我们将模型分配给变量“vgg”,并通过将其作为模型的参数来下载 ImageNet 的权重

步骤 3:由于这些预训练模型如 VGG16、ResNet 已经在数千张图像上训练并用于分类多个类别,因此我们不需要再次训练预训练模型的层数。 因此,我们将 VGG16 模型的所有层设置为“False”。
![]()
第 4 步:由于我们已经冻结了所有层并删除了预训练 VGG16 模型的最后一个分类层,我们需要在预训练模型之上添加一个分类层以在数据集上对其进行训练。 因此,我们将这些层展平并引入一个最终的 Dense 层,该层以 softmax 作为激活函数,并以二元类预测模型为例。

第 5 步:在最后一步中,我们打印模型的摘要,以可视化预训练的 VGG16 模型的层以及我们利用迁移学习在其上添加的两层。
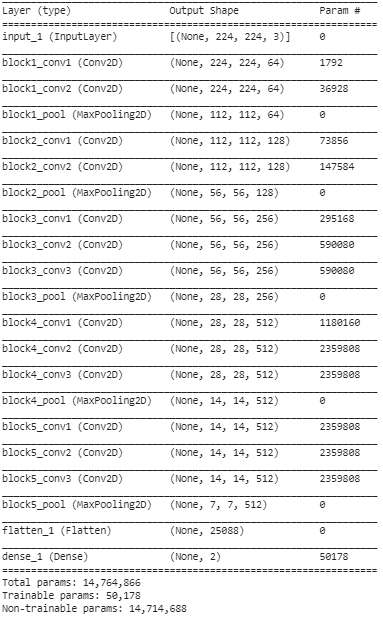
从上面的总结中,我们可以看到总共有接近 14.76M 的参数,其中只有大约 50,000 个属于最后两层的参数由于上面步骤 3 中设置的条件而被允许用于训练目的。剩下的 14.71 M 个参数称为不可训练参数。
一旦执行了这些步骤,我们就可以通过使用外部超参数(例如优化器和损失函数)编译我们的模型来执行训练常规卷积神经网络的步骤。
编译后,我们可以使用 fit 函数开始训练一组 epoch。 通过这种方式,我们可以利用迁移学习的方法在网络上用几个这样的预训练模型训练任何数据集,并根据我们训练数据的类数在模型之上添加几层。
另请阅读:深度学习算法 [综合指南]
结论
在本文中,我们通过 keras 库中的示例预训练 VGG16 模型对迁移学习、其应用及其实现进行了基本了解。 除此之外,已经发现仅使用网络最后两层的预训练权重对收敛的影响最大。
由于重复使用特征,这也导致更快的收敛。 如今,迁移学习在构建模型方面有很多应用。 最重要的是,用于医疗保健应用的人工智能由于其庞大的规模,需要几种这样的预训练模式。 尽管迁移学习可能还处于起步阶段,但在未来几年,它将成为以更高的效率和准确性训练大型数据集的最常用方法之一。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
深度学习与机器学习有何不同?
机器学习和深度学习都是称为人工智能的专业领域。 机器学习是人工智能的一个子类别,它涉及如何教机器或计算机在最少的人为参与的情况下学习和执行确定的任务。 而且,深度学习是机器学习的一个子领域。 深度学习建立在人工神经网络的概念之上,可以帮助机器理解上下文并像人类一样做出决定。 虽然深度学习用于处理大量原始数据,但机器学习通常需要结构化数据形式的输入。 此外,虽然深度学习算法可以在零到最小人为干扰的情况下运行,但机器学习模型仍需要一定程度的人为参与。
学习深度神经网络有什么先决条件吗?
从事人工智能领域的大型项目,尤其是深度学习,需要你对人工神经网络的基础有一个清晰而健全的概念。 要发展您的神经网络基础知识,首先,您需要阅读大量与该主题相关的书籍,并阅读文章和新闻以跟上热门话题和发展。 但谈到学习神经网络的先决条件,你不能忽视数学,尤其是线性代数、微积分、统计学和概率。 除此之外,对 Python、R 和 Java 等编程语言有一定的了解也将是有益的。
什么是人工智能中的迁移学习?
在新模型中重用先前训练的机器学习模型中的元素的技术被称为人工智能中的迁移学习。 如果两个模型都设计为执行相似的功能,则可以通过迁移学习在它们之间共享通用知识。 这种训练模型的技术促进了可用资源的有效利用,并防止分类数据的浪费。 随着机器学习的不断发展,迁移学习在人工智能的发展中越来越重要。