
Trasferisci l'apprendimento in Deep Learning [Guida completa]
Pubblicato: 2020-12-07Sommario
introduzione
Che cos'è l'apprendimento profondo? È una branca del Machine Learning che utilizza una simulazione del cervello umano nota come reti neurali. Queste reti neurali sono costituite da neuroni simili all'unità fondamentale del cervello umano.
I neuroni costituiscono un modello di rete neurale e questo campo di studio complessivamente è chiamato deep learning. Il risultato finale di una rete neurale è chiamato modello di apprendimento profondo. Per lo più, nell'apprendimento profondo, vengono utilizzati dati non strutturati da cui il modello di apprendimento profondo estrae le funzionalità da solo mediante l'addestramento ripetuto sui dati.
Tali modelli progettati per un particolare insieme di dati quando disponibili per l'uso come punto di partenza per lo sviluppo di un altro modello con un diverso insieme di dati e funzionalità, sono noti come Transfer Learning. In termini semplici, Transfer Learning è un metodo popolare in cui un modello sviluppato per un compito particolare viene nuovamente utilizzato come punto di partenza per sviluppare un modello per un altro compito.
Trasferisci l'apprendimento
Il Transfer Learning è stato utilizzato dagli esseri umani da tempo immemorabile. Sebbene questo campo del transfer learning sia relativamente nuovo per l'apprendimento automatico, gli esseri umani lo hanno utilizzato intrinsecamente in quasi tutte le situazioni.
Cerchiamo sempre di applicare le conoscenze acquisite dalle nostre esperienze passate quando affrontiamo un nuovo problema o compito e questa è la base del transfer learning. Ad esempio, se sappiamo andare in bicicletta e quando ci viene chiesto di guidare una moto che non abbiamo mai fatto prima, la nostra esperienza con l'andare in bicicletta sarà sempre applicata quando si guida la moto, come sterzare il manubrio e bilanciare la bicicletta. Questo semplice concetto costituisce la base del Transfer Learning.
Per comprendere la nozione di base di Transfer Learning, si consideri che un modello X è stato addestrato con successo per eseguire il compito A con il modello M1. Se la dimensione del set di dati per l'attività B è troppo piccola, impedendo al modello Y di addestrarsi in modo efficiente o causando un overfitting dei dati, possiamo utilizzare una parte del modello M1 come base per costruire il modello Y per eseguire l'attività B.

Perché trasferire l'apprendimento?
Secondo Andrew Ng, uno dei pionieri del mondo di oggi nella promozione dell'Intelligenza Artificiale, "Il Transfer Learning sarà il prossimo motore del successo del ML". Ne ha parlato in un discorso tenuto alla Conferenza sui sistemi di elaborazione delle informazioni neurali (NIPS 2016). Non c'è dubbio che il successo del ML nel settore odierno sia dovuto principalmente all'apprendimento supervisionato. D'altra parte, andando avanti, con una maggiore quantità di dati non supervisionati e non etichettati, il transfer learning sarà una tecnica che sarà ampiamente utilizzata nel settore.
Al giorno d'oggi, le persone preferiscono utilizzare un modello pre-addestrato che è già addestrato su una varietà di immagini come ImageNet piuttosto che costruire un intero modello di rete neurale convoluzionale da zero. L'apprendimento del trasferimento ha diversi vantaggi, ma i vantaggi principali sono il risparmio di tempo di addestramento, migliori prestazioni delle reti neurali e la non necessità di molti dati.
Leggi: Le migliori tecniche di apprendimento profondo
Metodi di trasferimento dell'apprendimento
In generale, ci sono due modi per applicare il transfer learning: uno sta sviluppando un modello da zero e l'altro consiste nell'utilizzare un modello pre-addestrato.
Nel primo caso, di solito costruiamo un'architettura del modello in base ai dati di addestramento e la capacità del modello di estrarre pesi e modelli dal modello viene studiata attentamente con diversi parametri statistici. Dopo alcuni cicli di allenamento, a seconda del risultato, potrebbe essere necessario apportare alcune modifiche al modello per ottenere prestazioni ottimali. In questo modo, possiamo salvare il modello e usarlo come punto di partenza per costruire un altro modello per un'attività simile.
Il secondo caso di utilizzo di modelli pre-addestrati è di solito più comunemente riferito al Transfer Learning. In questo, dobbiamo cercare modelli pre-addestrati che sono condivisi da diversi istituti di ricerca e organizzazioni rilasciati periodicamente per un uso generale. Questi modelli sono disponibili per il download su Internet insieme ai relativi pesi e possono essere utilizzati per creare modelli per set di dati simili.
Implementazione del Transfer Learning – Modello VGG16
Esaminiamo un'applicazione di Transfer Learning utilizzando un modello pre-addestrato chiamato VGG16.
Il VGG16 è un modello di rete neurale convoluzionale che è stato rilasciato dai professori dell'Università di Oxford nell'anno 2014. È stato uno dei famosi modelli che ha vinto il concorso ILSVR (ImageNet) quell'anno. È ancora riconosciuta come una delle migliori architetture di modelli di visione. Ha 16 strati di peso inclusi 13 strati convoluzionali, 3 strati completamente collegati e uno strato morbido massimo. Ha circa 138 milioni di parametri. Di seguito è riportata l'architettura del modello VGG16.
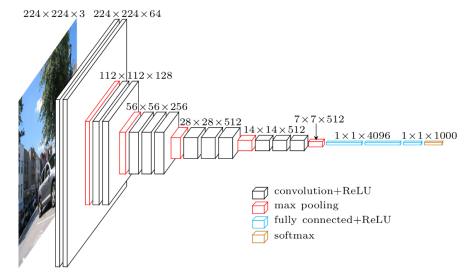
Fonte immagine: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Passaggio 1: il primo passaggio consiste nell'importare il modello VGG16 fornito dalla libreria keras nel framework TensorFlow.

![]()
Passaggio 2: nel passaggio successivo, assegneremo il modello a una variabile "vgg" e scaricheremo i pesi di ImageNet fornendolo come argomento al modello

Passaggio 3: poiché questi modelli pre-addestrati come VGG16, ResNet sono stati addestrati su diverse migliaia di immagini e vengono utilizzati per classificare diverse classi, non è necessario addestrare nuovamente i livelli del modello pre-addestrato. Quindi, impostiamo tutti i livelli del modello VGG16 come "False".
![]()
Passaggio 4: poiché abbiamo congelato tutti i livelli e rimosso gli ultimi livelli di classificazione del modello VGG16 pre-addestrato, è necessario aggiungere un livello di classificazione sopra il modello pre-addestrato per addestrarlo su un set di dati. Quindi, appiattiamo i livelli e introduciamo uno strato denso finale con softmax come funzione di attivazione con un esempio di un modello di previsione di classe binaria.

Passaggio 5: in questo passaggio finale, stampiamo il riepilogo del nostro modello per visualizzare i livelli del modello VGG16 pre-addestrato e i due livelli che abbiamo aggiunto sopra utilizzando Transfer Learning.
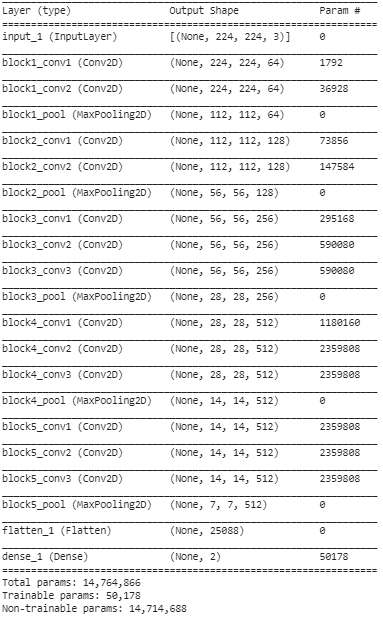
Dal riepilogo di cui sopra, possiamo vedere che ci sono quasi 14,76 milioni di parametri totali di cui solo circa 50.000 parametri appartenenti agli ultimi due livelli possono essere utilizzati a fini di addestramento a causa della condizione sopra impostata nel passaggio 3. I restanti 14,71 I parametri M sono indicati come parametri non addestrabili.
Una volta eseguiti questi passaggi, possiamo eseguire i passaggi per addestrare la normale rete neurale convoluzionale compilando il nostro modello con iperparametri esterni come l'ottimizzatore e la funzione di perdita.
Dopo la compilazione, possiamo iniziare l'addestramento utilizzando la funzione fit per un determinato numero di epoche. In questo modo, possiamo utilizzare il metodo del trasferimento dell'apprendimento per addestrare qualsiasi set di dati con diversi modelli pre-addestrati in rete e aggiungere alcuni livelli sopra il modello in base al numero di classi dei nostri dati di addestramento.
Leggi anche: Algoritmo di Deep Learning [Guida completa]
Conclusione
In questo articolo, abbiamo esaminato la comprensione di base di Transfer Learning, la sua applicazione e anche la sua implementazione con un modello VGG16 pre-addestrato di esempio dalla libreria keras. In aggiunta a questo, è stato scoperto che l'utilizzo dei pesi pre-addestrati solo dagli ultimi due strati della rete ha l'effetto maggiore sulla convergenza.
Ciò si traduce anche in una convergenza più rapida grazie all'utilizzo ripetuto delle funzionalità. Oggi Transfer Learning ha molte applicazioni nella creazione di modelli. Soprattutto, l'IA per le applicazioni sanitarie necessita di diverse modalità pre-addestrate a causa delle sue grandi dimensioni. Sebbene il Transfer Learning possa essere nelle sue fasi iniziali, nei prossimi anni sarà uno dei metodi più utilizzati per addestrare grandi set di dati con maggiore efficienza e precisione.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
In che modo il deep learning è diverso dal machine learning?
Sia l'apprendimento automatico che l'apprendimento profondo sono campi specializzati sotto l'ombrello chiamato intelligenza artificiale. L'apprendimento automatico è una sottocategoria dell'intelligenza artificiale che si occupa di come si può insegnare a macchine o computer ad apprendere e svolgere compiti definiti con il minimo coinvolgimento umano. E il deep learning è un sottocampo dell'apprendimento automatico. Il deep learning si basa sui concetti di reti neurali artificiali che aiutano le macchine ad apprezzare i contesti e a decidere come gli esseri umani. Mentre il deep learning viene utilizzato per elaborare enormi volumi di dati grezzi, il machine learning di solito si aspetta input sotto forma di dati strutturati. Inoltre, mentre gli algoritmi di deep learning possono funzionare con un'interferenza umana da zero a minima, i modelli di machine learning avranno comunque bisogno di un certo livello di coinvolgimento umano.
Ci sono dei prerequisiti per l'apprendimento delle reti neurali profonde?
Lavorare a un progetto su larga scala nel campo dell'intelligenza artificiale, in particolare del deep learning, richiederà che tu abbia un concetto chiaro e solido delle basi delle reti neurali artificiali. Per sviluppare i tuoi fondamenti sulle reti neurali, in primo luogo, devi leggere molti libri relativi all'argomento e anche leggere articoli e notizie per stare al passo con gli argomenti e gli sviluppi di tendenza. Ma venendo ai prerequisiti per l'apprendimento delle reti neurali, non si può ignorare la matematica, in particolare l'algebra lineare, il calcolo, la statistica e la probabilità. Oltre a questi, sarà utile anche una discreta conoscenza dei linguaggi di programmazione come Python, R e Java.
Che cos'è il transfer learning nell'intelligenza artificiale?
La tecnica di riutilizzo degli elementi di un modello di machine learning precedentemente addestrato in un nuovo modello è nota come transfer learning nell'intelligenza artificiale. Se entrambi i modelli sono progettati per svolgere funzioni simili, è possibile condividere la conoscenza generalizzata tra di loro tramite il transfer learning. Questa tecnica di modelli di formazione promuove l'utilizzo efficace delle risorse disponibili e previene lo spreco di dati classificati. Man mano che l'apprendimento automatico continua a evolversi, il trasferimento di apprendimento continua ad acquisire un significato sempre maggiore nello sviluppo dell'intelligenza artificiale.