
Transferir Aprendizagem em Aprendizado Profundo [Guia Completo]
Publicados: 2020-12-07Índice
Introdução
O que é Aprendizado Profundo? É um ramo do Machine Learning que usa uma simulação do cérebro humano que são conhecidas como redes neurais. Essas redes neurais são compostas de neurônios que são semelhantes à unidade fundamental do cérebro humano.
Os neurônios compõem um modelo de rede neural e esse campo de estudo é chamado de aprendizado profundo. O resultado final de uma rede neural é chamado de modelo de aprendizado profundo. Principalmente, no aprendizado profundo, são usados dados não estruturados dos quais o modelo de aprendizado profundo extrai recursos por conta própria por meio de treinamento repetido nos dados.
Esses modelos que são projetados para um determinado conjunto de dados, quando disponíveis para uso como ponto de partida para o desenvolvimento de outro modelo com um conjunto diferente de dados e recursos, são conhecidos como Aprendizado de Transferência. Em termos simples, o Transfer Learning é um método popular em que um modelo desenvolvido para uma tarefa específica é novamente usado como ponto de partida para desenvolver um modelo para outra tarefa.
Transferência de Aprendizagem
A aprendizagem por transferência tem sido utilizada por humanos desde tempos imemoriais. Embora esse campo de aprendizado de transferência seja relativamente novo para aprendizado de máquina, os humanos o usaram inerentemente em quase todas as situações.
Sempre tentamos aplicar o conhecimento adquirido em nossas experiências passadas quando enfrentamos um novo problema ou tarefa e essa é a base do aprendizado de transferência. Por exemplo, se sabemos andar de bicicleta e quando solicitados a andar de moto o que não fizemos antes, nossa experiência em andar de bicicleta sempre será aplicada ao andar de moto, como dirigir o manípulo e equilibrar a moto. Este conceito simples forma a base do Transfer Learning.
Para entender a noção básica de Transferência de Aprendizagem, considere um modelo X treinado com sucesso para realizar a tarefa A com o modelo M1. Se o tamanho do conjunto de dados para a tarefa B for muito pequeno, impedindo que o modelo Y treine de forma eficiente ou cause overfitting dos dados, podemos usar uma parte do modelo M1 como base para construir o modelo Y para executar a tarefa B.

Por que Transferir Aprendizagem?
De acordo com Andrew Ng, um dos pioneiros do mundo de hoje na promoção da Inteligência Artificial, “Transfer Learning será o próximo impulsionador do sucesso do ML”. Ele mencionou isso em uma palestra dada na Conference on Neural Information Processing Systems (NIPS 2016). Não há dúvida de que o sucesso do ML na indústria atual se deve principalmente ao aprendizado supervisionado. Por outro lado, daqui para frente, com maior quantidade de dados não supervisionados e não rotulados, o aprendizado de transferência será uma técnica que será muito utilizada na indústria.
Hoje em dia, as pessoas preferem usar um modelo pré-treinado que já é treinado em uma variedade de imagens, como ImageNet , do que construir um modelo inteiro de Rede Neural Convolucional do zero. O aprendizado de transferência tem vários benefícios, mas as principais vantagens são economizar tempo de treinamento, melhor desempenho das redes neurais e não precisar de muitos dados.
Leia: Principais técnicas de aprendizado profundo
Métodos de Transferência de Aprendizagem
Geralmente, existem duas maneiras de aplicar o aprendizado de transferência – uma é desenvolver um modelo do zero e a outra é usar um modelo pré-treinado.
No primeiro caso, geralmente construímos uma arquitetura de modelo dependendo dos dados de treinamento e a capacidade do modelo de extrair pesos e padrões do modelo é estudada cuidadosamente com vários parâmetros estatísticos. Após algumas rodadas de treinamento, dependendo do resultado, podem ser necessárias algumas alterações no modelo para atingir o desempenho ideal. Dessa forma, podemos salvar o modelo e usá-lo como ponto de partida para construir outro modelo para uma tarefa semelhante.
O segundo caso de uso de modelos pré-treinados geralmente é mais comumente referido como Transferência de Aprendizagem. Nesse sentido, temos que buscar modelos pré-treinados que são compartilhados por diversas instituições e organizações de pesquisa e divulgados periodicamente para uso geral. Esses modelos estão disponíveis para download na internet junto com seus pesos e podem ser usados para construir modelos para conjuntos de dados semelhantes.
Implementação de Aprendizagem de Transferência - Modelo VGG16
Vamos passar por uma aplicação de Transfer Learning utilizando um modelo pré-treinado chamado VGG16.
O VGG16 é um modelo de Rede Neural Convolucional que foi lançado pelos Professores da Universidade de Oxford no ano de 2014. Foi um dos modelos famosos que venceu o Concurso ILSVR (ImageNet) daquele ano. Ainda é reconhecida como uma das melhores arquiteturas de modelo de visão. Possui 16 camadas de peso, incluindo 13 camadas convolucionais, 3 camadas totalmente conectadas e uma camada máxima suave. Tem aproximadamente 138 milhões de parâmetros. Dada a seguir é a Arquitetura do Modelo VGG16.
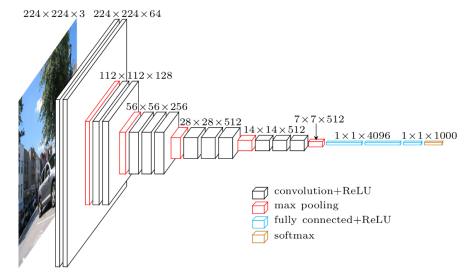
Fonte da imagem: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Etapa 1: a primeira etapa é importar o modelo VGG16 fornecido pela biblioteca keras na estrutura do TensorFlow.

![]()
Passo 2: No próximo passo, vamos atribuir o modelo a uma variável “vgg” e baixar os pesos do ImageNet dando-o como argumento para o modelo

Etapa 3: Como esses modelos pré-treinados, como VGG16, ResNet, foram treinados em vários milhares de imagens e são usados para classificar várias classes, não precisamos treinar novamente as camadas do modelo pré-treinado. Assim, definimos todas as camadas do modelo VGG16 como “False”.
![]()
Etapa 4: Como congelamos todas as camadas e removemos as últimas camadas de classificação do modelo VGG16 pré-treinado, precisamos adicionar uma camada de classificação em cima do modelo pré-treinado para treiná-lo em um conjunto de dados. Assim, achatamos as camadas e introduzimos uma camada Dense final com softmax como função de ativação com um exemplo de modelo de previsão de classe binária.

Etapa 5: Nesta etapa final, imprimimos o resumo do nosso modelo para visualizar as camadas do modelo VGG16 pré-treinado e as duas camadas que adicionamos em cima dele utilizando o Transfer Learning.
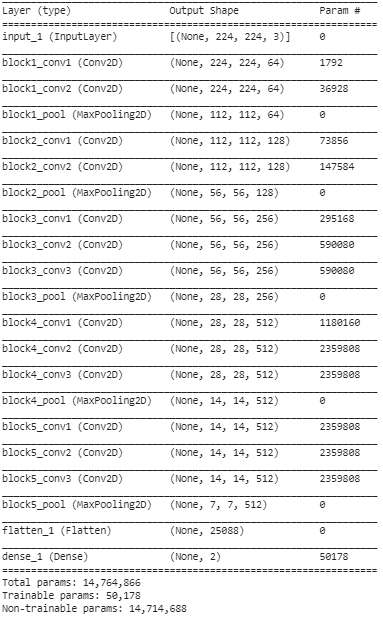
A partir do resumo acima, podemos ver que existem cerca de 14,76 milhões de parâmetros totais, dos quais apenas cerca de 50.000 parâmetros pertencentes às duas últimas camadas podem ser usados para fins de treinamento devido à condição definida acima na Etapa 3. Os 14,71 restantes Os parâmetros M são chamados de parâmetros não treináveis.
Uma vez que essas etapas são executadas, podemos executar etapas para treinar a Rede Neural Convolucional regular compilando nosso modelo com hiperparâmetros externos, como otimizador e função de perda.
Após a compilação, podemos iniciar o treinamento usando a função fit para um número definido de épocas. Dessa forma, podemos utilizar o método de transferência de aprendizado para treinar qualquer conjunto de dados com vários modelos pré-treinados na rede e adicionar algumas camadas no topo do modelo de acordo com o número de classes de nossos dados de treinamento.
Leia também: Algoritmo de aprendizado profundo [Guia abrangente]
Conclusão
Neste artigo, passamos pelo entendimento básico do Transfer Learning, sua aplicação e também sua implementação com um modelo VGG16 pré-treinado da biblioteca keras. Além disso, descobriu-se que usar os pesos pré-treinados apenas das duas últimas camadas da rede tem o maior efeito na convergência.
Isso também resulta em convergência mais rápida devido ao uso repetido de recursos. O Transfer Learning tem muitas aplicações na construção de modelos hoje. Mais importante ainda, a IA para aplicativos de saúde precisa de vários modos pré-treinados devido ao seu grande tamanho. Embora o Transfer Learning possa estar em seus estágios iniciais, nos próximos anos será um dos métodos mais utilizados para treinar grandes conjuntos de dados com mais eficiência e precisão.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Como o aprendizado profundo é diferente do aprendizado de máquina?
Tanto o aprendizado de máquina quanto o aprendizado profundo são campos especializados sob o guarda-chuva chamado inteligência artificial. O aprendizado de máquina é uma subcategoria da inteligência artificial que trata de como máquinas ou computadores podem ser ensinados a aprender e realizar tarefas definidas com o mínimo de envolvimento humano. E o aprendizado profundo é um subcampo do aprendizado de máquina. O aprendizado profundo é construído sobre os conceitos de redes neurais artificiais que ajudam as máquinas a apreciar contextos e decidir como humanos. Embora o aprendizado profundo seja usado para processar grandes volumes de dados brutos, o aprendizado de máquina geralmente espera entradas na forma de dados estruturados. Além disso, embora os algoritmos de aprendizado profundo possam funcionar com zero a mínima interferência humana, os modelos de aprendizado de máquina ainda precisarão de algum nível de envolvimento humano.
Existem pré-requisitos para aprender redes neurais profundas?
Trabalhar em um projeto de grande escala no campo da inteligência artificial, especialmente o aprendizado profundo, exigirá que você tenha um conceito claro e sólido dos fundamentos das redes neurais artificiais. Para desenvolver seus fundamentos de redes neurais, em primeiro lugar, você precisa ler muitos livros relacionados ao assunto e também passar por artigos e notícias para acompanhar os tópicos e desenvolvimentos em alta. Mas chegando aos pré-requisitos de aprendizagem de redes neurais, você não pode ignorar a matemática, especialmente álgebra linear, cálculo, estatística e probabilidade. Além disso, um bom conhecimento de linguagens de programação como Python, R e Java também será benéfico.
O que é o aprendizado de transferência em inteligência artificial?
A técnica de reutilizar elementos de um modelo de aprendizado de máquina previamente treinado em um novo modelo é conhecida como transferência de aprendizado em inteligência artificial. Se ambos os modelos forem projetados para desempenhar funções semelhantes, é possível compartilhar conhecimento generalizado entre eles por meio do aprendizado de transferência. Essa técnica de treinamento de modelos promove a utilização efetiva dos recursos disponíveis e evita o desperdício de dados classificados. À medida que o aprendizado de máquina continua evoluindo, o aprendizado de transferência continua ganhando maior importância no desenvolvimento da inteligência artificial.