
Transferați învățarea în învățarea profundă [Ghid cuprinzător]
Publicat: 2020-12-07Cuprins
Introducere
Ce este Deep Learning? Este o ramură a învățării automate care utilizează o simulare a creierului uman, cunoscută sub numele de rețele neuronale. Aceste rețele neuronale sunt formate din neuroni care sunt similari cu unitatea fundamentală a creierului uman.
Neuronii alcătuiesc un model de rețea neuronală și acest domeniu de studiu în totalitate este denumit învățare profundă. Rezultatul final al unei rețele neuronale se numește model de învățare profundă. În cea mai mare parte, în învățarea profundă, sunt utilizate date nestructurate din care modelul de învățare profundă extrage caracteristici pe cont propriu prin antrenament repetat asupra datelor.
Astfel de modele care sunt concepute pentru un anumit set de date atunci când sunt disponibile pentru utilizare ca punct de plecare pentru dezvoltarea unui alt model cu un set diferit de date și caracteristici, sunt cunoscute sub numele de Transfer Learning. În termeni simpli, Transfer Learning este o metodă populară în care un model dezvoltat pentru o anumită sarcină este din nou folosit ca punct de plecare pentru a dezvolta un model pentru o altă sarcină.
Transfer de învățare
Transfer Learning a fost folosit de oameni din timpuri imemoriale. Deși acest domeniu de învățare prin transfer este relativ nou pentru învățarea automată, oamenii l-au folosit în mod inerent în aproape toate situațiile.
Încercăm întotdeauna să aplicăm cunoștințele dobândite din experiențele noastre trecute atunci când ne confruntăm cu o nouă problemă sau sarcină și aceasta este baza învățării prin transfer. De exemplu, dacă știm să mergem cu bicicleta și când suntem rugați să mergem cu o motocicletă, ceea ce nu am făcut până acum, experiența noastră cu mersul pe bicicletă va fi întotdeauna aplicată atunci când mergem cu motocicleta, cum ar fi direcția mânerului și echilibrarea bicicletei. Acest concept simplu formează baza învățării prin transfer.
Pentru a înțelege noțiunea de bază a învățării prin transfer, considerăm că un model X este antrenat cu succes pentru a îndeplini sarcina A cu modelul M1. Dacă dimensiunea setului de date pentru sarcina B este prea mică, împiedicând antrenamentul eficient al modelului Y sau provocând supraadaptarea datelor, putem folosi o parte din modelul M1 ca bază pentru a construi modelul Y pentru a îndeplini sarcina B.

De ce să transferați învățarea?
Potrivit lui Andrew Ng, unul dintre pionierii lumii de astăzi în promovarea inteligenței artificiale, „Transfer Learning va fi următorul motor al succesului ML”. El a menționat-o într-o discuție susținută la Conference on Neural Information Processing Systems (NIPS 2016). Fără îndoială, succesul ML în industria de astăzi se datorează în primul rând învățării supravegheate. Pe de altă parte, în viitor, cu o cantitate mai mare de date nesupravegheate și neetichetate, învățarea prin transfer va fi o tehnică care va fi utilizată intens în industrie.
În zilele noastre, oamenii preferă să folosească un model pre-antrenat care este deja antrenat pe o varietate de imagini, cum ar fi ImageNet , decât să construiască un întreg model de rețea neuronală convoluțională de la zero. Învățarea prin transfer are mai multe beneficii, dar principalele avantaje sunt economisirea timpului de antrenament, performanța mai bună a rețelelor neuronale și lipsa de multe date.
Citiți: Top tehnici de învățare profundă
Metode de transfer de învățare
În general, există două moduri de aplicare a învățării prin transfer – Una este dezvoltarea unui model de la zero și cealaltă este utilizarea unui model pre-instruit.
În primul caz, de obicei construim o arhitectură a modelului în funcție de datele de antrenament și capacitatea modelului de a extrage greutăți și modele din model este studiată cu atenție cu mai mulți parametri statistici. După câteva runde de antrenament, în funcție de rezultat, pot fi necesare unele modificări la model pentru a obține o performanță optimă. În acest fel, putem salva modelul și îl putem folosi ca început pentru a construi un alt model pentru o sarcină similară.
Al doilea caz de utilizare a modelelor pre-instruite se referă, de obicei, la Transfer Learning. În acest sens, trebuie să căutăm modele pre-instruite care sunt împărtășite de mai multe instituții de cercetare și organizații lansate periodic pentru uz general. Aceste modele sunt disponibile pentru descărcare de pe internet împreună cu greutățile lor și pot fi folosite pentru a construi modele pentru seturi de date similare.
Implementarea învățării prin transfer – Model VGG16
Să trecem printr-o aplicație de Transfer Learning utilizând un model pre-antrenat numit VGG16.
VGG16 este un model de rețea neuronală convoluțională care a fost lansat de profesorii de la Universitatea Oxford în anul 2014. A fost unul dintre modelele celebre care a câștigat concursul ILSVR (ImageNet) în acel an. Este încă recunoscută ca una dintre cele mai bune arhitecturi de model de viziune. Are 16 straturi de greutate, inclusiv 13 straturi convoluționale, 3 straturi complet conectate și un strat maxim moale. Are aproximativ 138 de milioane de parametri. Mai jos este prezentată Arhitectura modelului VGG16.
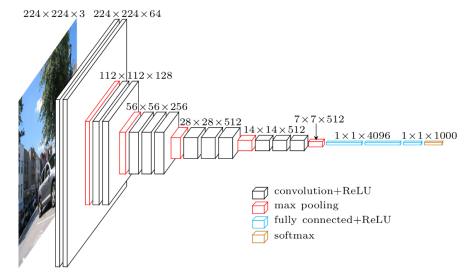
Sursa imagine: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Pasul 1: Primul pas este să importați modelul VGG16 furnizat de biblioteca keras în cadrul TensorFlow.

![]()
Pasul 2: În pasul următor, vom atribui modelul unei variabile „vgg” și vom descărca ponderile ImageNet dându-l ca argument modelului

Pasul 3: Deoarece aceste modele pre-antrenate, cum ar fi VGG16, ResNet au fost antrenate pe câteva mii de imagini și sunt folosite pentru a clasifica mai multe clase, nu este nevoie să antrenăm straturile modelului pre-antrenat încă o dată. Prin urmare, am setat toate straturile modelului VGG16 ca „False”.
![]()
Pasul 4: Deoarece am înghețat toate straturile și am eliminat ultimele straturi de clasificare ale modelului VGG16 pre-antrenat, trebuie să adăugăm un strat de clasificare deasupra modelului pre-antrenat pentru a-l antrena pe un set de date. Prin urmare, aplatizăm straturile și introducem un strat dens final cu softmax ca funcție de activare cu un exemplu de model de predicție de clasă binară.

Pasul 5: În acest pas final, tipărim rezumatul modelului nostru pentru a vizualiza straturile modelului VGG16 pre-antrenat și cele două straturi pe care le-am adăugat deasupra utilizând Transfer Learning.
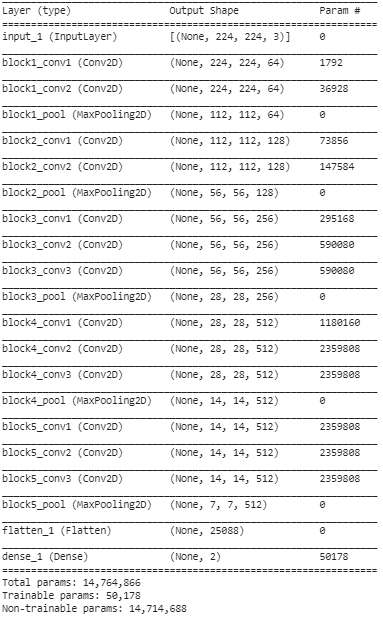
Din rezumatul de mai sus, putem observa că există aproape 14,76 milioane de parametri totali, dintre care doar aproximativ 50.000 de parametri aparținând ultimelor două straturi pot fi utilizați în scopuri de antrenament, datorită condiției stabilite mai sus la Pasul 3. Restul de 14,71 Parametrii M sunt denumiți parametri care nu se pot antrena.
Odată îndepliniți acești pași, putem efectua pași pentru a antrena rețeaua neuronală convoluțională obișnuită prin compilarea modelului nostru cu hiperparametri externi, cum ar fi optimizatorul și funcția de pierdere.
După compilare, putem începe antrenamentul folosind funcția fit pentru un număr stabilit de epoci. În acest fel, putem folosi metoda de transfer de învățare pentru a antrena orice set de date cu mai multe astfel de modele pre-antrenate pe net și adăugând câteva straturi deasupra modelului în funcție de numărul de clase ale datelor noastre de antrenament.
Citiți și: Algoritmul de învățare profundă [Ghid cuprinzător]
Concluzie
În acest articol, am trecut prin înțelegerea de bază a transferului de învățare, aplicarea acesteia și, de asemenea, implementarea sa cu un exemplu de model VGG16 pre-antrenat din biblioteca keras. În plus, s-a constatat că utilizarea greutăților pre-antrenate doar din ultimele două straturi ale rețelei are cel mai mare efect asupra convergenței.
Acest lucru duce, de asemenea, la o convergență mai rapidă datorită utilizării repetate a funcțiilor. Transfer Learning are o mulțime de aplicații în construirea modelelor astăzi. Cel mai important, AI pentru aplicații de asistență medicală are nevoie de mai multe astfel de moduri pre-antrenate datorită dimensiunii sale mari. Deși, Transfer Learning poate fi în stadiile inițiale, în următorii ani va fi una dintre cele mai utilizate metode de a antrena seturi mari de date cu mai multă eficiență și acuratețe.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Prin ce este diferită învățarea profundă de învățarea automată?
Atât învățarea automată, cât și învățarea profundă sunt domenii specializate sub umbrela numite inteligență artificială. Învățarea automată este o subcategorie a inteligenței artificiale care se ocupă de modul în care mașinile sau computerele pot fi învățate să învețe și să îndeplinească sarcini precise cu implicarea umană minimă. Și, învățarea profundă este un subdomeniu al învățării automate. Învățarea profundă se bazează pe conceptele rețelelor neuronale artificiale care ajută mașinile să aprecieze contextele și să decidă ca oamenii. În timp ce învățarea profundă este utilizată pentru a procesa volume masive de date brute, învățarea automată așteaptă de obicei intrări sub formă de date structurate. În plus, în timp ce algoritmii de învățare profundă pot funcționa cu interferențe umane de la zero până la minim, modelele de învățare automată vor avea nevoie în continuare de un anumit nivel de implicare umană.
Există condiții prealabile pentru a învăța rețelele neuronale profunde?
Lucrul la un proiect la scară largă în domeniul inteligenței artificiale, în special învățarea profundă, va trebui să aveți un concept clar și solid al bazelor rețelelor neuronale artificiale. Pentru a vă dezvolta bazele rețelelor neuronale, în primul rând, trebuie să citiți o mulțime de cărți legate de subiect și, de asemenea, să parcurgeți articole și știri pentru a fi la curent cu subiectele și evoluțiile în tendințe. Dar venind la cerințele prealabile ale învățării rețelelor neuronale, nu poți ignora matematica, în special algebra liniară, calculul, statistica și probabilitatea. În afară de acestea, o cunoaștere corectă a limbajelor de programare precum Python, R și Java va fi, de asemenea, benefică.
Ce este învățarea prin transfer în inteligența artificială?
Tehnica de reutilizare a elementelor dintr-un model de învățare automată antrenat anterior într-un model nou este cunoscută sub numele de învățare prin transfer în inteligența artificială. Dacă ambele modele sunt proiectate să îndeplinească funcții similare, este posibilă împărtășirea cunoștințelor generalizate între ele prin învățarea prin transfer. Această tehnică a modelelor de instruire promovează utilizarea eficientă a resurselor disponibile și previne risipa de date clasificate. Pe măsură ce învățarea automată continuă să evolueze, învățarea prin transfer câștigă o importanță mai mare în dezvoltarea inteligenței artificiale.