
ถ่ายทอดการเรียนรู้ในการเรียนรู้เชิงลึก [คู่มือที่ครอบคลุม]
เผยแพร่แล้ว: 2020-12-07สารบัญ
บทนำ
การเรียนรู้เชิงลึกคืออะไร? เป็นสาขาหนึ่งของ Machine Learning ซึ่งใช้การจำลองสมองของมนุษย์ที่เรียกว่าโครงข่ายประสาทเทียม โครงข่ายประสาทเหล่านี้ประกอบด้วยเซลล์ประสาทที่คล้ายกับหน่วยพื้นฐานของสมองมนุษย์
เซลล์ประสาทประกอบขึ้นเป็นแบบจำลองโครงข่ายประสาทเทียม และสาขาการศึกษานี้รวมกันเรียกว่าการเรียนรู้เชิงลึก ผลลัพธ์สุดท้ายของโครงข่ายประสาทเทียมเรียกว่าแบบจำลองการเรียนรู้เชิงลึก ส่วนใหญ่ ในการเรียนรู้เชิงลึก ข้อมูลที่ไม่มีโครงสร้างจะถูกใช้ซึ่งโมเดลการเรียนรู้เชิงลึกจะดึงคุณลักษณะต่างๆ ด้วยตัวมันเองโดยการฝึกอบรมซ้ำกับข้อมูล
โมเดลดังกล่าวได้รับการออกแบบสำหรับชุดข้อมูลชุดใดชุดหนึ่งเมื่อพร้อมใช้งานเป็นจุดเริ่มต้นสำหรับการพัฒนาโมเดลอื่นด้วยชุดข้อมูลและคุณลักษณะที่แตกต่างกัน เรียกว่า Transfer Learning พูดง่ายๆ ก็คือ Transfer Learning เป็นวิธีที่ได้รับความนิยม โดยโมเดลหนึ่งที่พัฒนาขึ้นสำหรับงานเฉพาะจะถูกใช้อีกครั้งเป็นจุดเริ่มต้นในการพัฒนาแบบจำลองสำหรับงานอื่น
ถ่ายทอดการเรียนรู้
มนุษย์ใช้ Transfer Learning มาแต่ไหนแต่ไรแล้ว แม้ว่าการเรียนรู้การถ่ายโอนสาขานี้จะค่อนข้างใหม่สำหรับการเรียนรู้ของเครื่อง แต่มนุษย์ก็ใช้วิธีนี้โดยธรรมชาติในเกือบทุกสถานการณ์
เราพยายามนำความรู้ที่ได้รับจากประสบการณ์ที่ผ่านมาไปใช้เสมอเมื่อเราเผชิญกับปัญหาหรืองานใหม่ๆ และนี่คือพื้นฐานของการถ่ายโอนการเรียนรู้ ตัวอย่างเช่น หากเรารู้จักขี่จักรยานและเมื่อถูกขอให้ขี่มอเตอร์ไซค์ที่เราไม่เคยทำมาก่อน ประสบการณ์ของเราในการขี่จักรยานจะถูกนำมาใช้เสมอเมื่อขี่มอเตอร์ไซค์ เช่น การบังคับที่จับและการทรงตัวของจักรยาน แนวคิดง่ายๆ นี้เป็นพื้นฐานของ Transfer Learning
เพื่อให้เข้าใจแนวคิดพื้นฐานของ Transfer Learning ให้พิจารณาว่าโมเดล X ได้รับการฝึกฝนให้ทำงาน A ด้วยโมเดล M1 ได้สำเร็จ หากขนาดของชุดข้อมูลสำหรับงาน B มีขนาดเล็กเกินไปที่ทำให้ไม่สามารถฝึกโมเดล Y ได้อย่างมีประสิทธิภาพหรือทำให้เกิดการใช้ข้อมูลมากเกินไป เราสามารถใช้ส่วนหนึ่งของแบบจำลอง M1 เป็นฐานในการสร้างแบบจำลอง Y เพื่อทำงาน B

ทำไมต้องถ่ายทอดการเรียนรู้?
Andrew Ng หนึ่งในผู้บุกเบิกโลกปัจจุบันในการส่งเสริมปัญญาประดิษฐ์กล่าวว่า "การเรียนรู้แบบถ่ายโอนจะเป็นตัวขับเคลื่อนต่อไปของความสำเร็จของ ML" เขาพูดถึงเรื่องนี้ในการพูดคุยที่การประชุมเกี่ยวกับระบบประมวลผลข้อมูลประสาท (NIPS 2016) ไม่ต้องสงสัยเลยว่าความสำเร็จของ ML ในอุตสาหกรรมปัจจุบันเกิดจากการเรียนรู้ภายใต้การดูแลเป็นหลัก ในทางกลับกัน เมื่อมีข้อมูลที่ไม่ได้รับการดูแลและไม่มีป้ายกำกับจำนวนมากขึ้น การเรียนรู้การถ่ายโอนจะเป็นเทคนิคหนึ่งที่จะนำไปใช้อย่างมากในอุตสาหกรรม
ทุกวันนี้ ผู้คนชอบใช้โมเดลที่ได้รับการฝึกฝนล่วงหน้าซึ่งได้รับการฝึกฝนบนรูปภาพที่หลากหลายแล้ว เช่น ImageNet มากกว่า การสร้างโมเดล Convolutional Neural Network ทั้งหมดตั้งแต่เริ่มต้น การถ่ายโอนการเรียนรู้มีประโยชน์หลายประการ แต่ข้อดีหลักคือการประหยัดเวลาในการฝึกอบรม ประสิทธิภาพเครือข่ายประสาทที่ดีขึ้น และไม่ต้องการข้อมูลจำนวนมาก
อ่าน: เทคนิคการเรียนรู้เชิงลึกยอดนิยม
วิธีการถ่ายโอนการเรียนรู้
โดยทั่วไป มีสองวิธีในการประยุกต์ใช้การเรียนรู้แบบถ่ายโอน – วิธีหนึ่งคือการพัฒนาแบบจำลองตั้งแต่เริ่มต้น และอีกวิธีหนึ่งคือการใช้แบบจำลองที่ผ่านการฝึกอบรมล่วงหน้า
ในกรณีแรก เรามักจะสร้างสถาปัตยกรรมแบบจำลองขึ้นอยู่กับข้อมูลการฝึก และความสามารถของตัวแบบในการดึงน้ำหนักและรูปแบบออกจากแบบจำลองนั้นจะได้รับการศึกษาอย่างรอบคอบด้วยพารามิเตอร์ทางสถิติหลายตัว หลังจากการฝึกอบรมสองสามรอบ ขึ้นอยู่กับผลลัพธ์ อาจจำเป็นต้องทำการเปลี่ยนแปลงบางอย่างกับโมเดลเพื่อให้ได้ประสิทธิภาพสูงสุด ด้วยวิธีนี้ เราสามารถบันทึกแบบจำลองและใช้เป็นจุดเริ่มต้นในการสร้างแบบจำลองอื่นสำหรับงานที่คล้ายคลึงกัน
กรณีที่สองของการใช้แบบจำลองที่ได้รับการฝึกฝนมาล่วงหน้ามักจะอ้างถึง Transfer Learning เป็นหลัก ในเรื่องนี้ เราต้องมองหาโมเดลที่ฝึกไว้ล่วงหน้าซึ่งใช้ร่วมกันโดยสถาบันวิจัยและองค์กรต่างๆ ที่เผยแพร่เป็นระยะเพื่อใช้งานทั่วไป โมเดลเหล่านี้สามารถดาวน์โหลดได้ทางอินเทอร์เน็ตพร้อมกับน้ำหนัก และสามารถใช้เพื่อสร้างแบบจำลองสำหรับชุดข้อมูลที่คล้ายกัน
โอนการดำเนินการเรียนรู้ – VGG16 Model
ให้เราดำเนินการผ่านแอปพลิเคชัน Transfer Learning โดยใช้โมเดลที่ผ่านการฝึกอบรมล่วงหน้าที่เรียกว่า VGG16
VGG16 เป็นโมเดล Convolutional Neural Network ที่เผยแพร่โดย Professors of University of Oxford ในปี 2014 เป็นหนึ่งในโมเดลที่มีชื่อเสียงที่ชนะการแข่งขัน ILSVR (ImageNet) ในปีนั้น ยังคงเป็นที่ยอมรับว่าเป็นหนึ่งในสถาปัตยกรรมแบบจำลองการมองเห็นที่ดีที่สุด มีชั้นน้ำหนัก 16 ชั้น รวมทั้งชั้นที่โค้งงอได้ 13 ชั้น ชั้นที่เชื่อมต่อกันทั้งหมด 3 ชั้น และชั้นสูงสุดแบบนุ่ม มีพารามิเตอร์ประมาณ 138 ล้านพารามิเตอร์ รับด้านล่างเป็นสถาปัตยกรรมของรุ่น VGG16
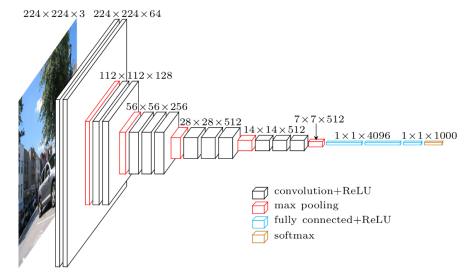
ที่มาของรูปภาพ: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
ขั้นตอนที่ 1: ขั้นตอนแรกคือการนำเข้าโมเดล VGG16 ที่จัดเตรียมโดยไลบรารี keras ในเฟรมเวิร์ก TensorFlow

![]()
ขั้นตอนที่ 2: ในขั้นตอนต่อไป เราจะกำหนดโมเดลให้กับตัวแปร "vgg" และดาวน์โหลดน้ำหนักของ ImageNet โดยให้มันเป็นอาร์กิวเมนต์ของโมเดล

ขั้นตอนที่ 3: เนื่องจากโมเดลที่ผ่านการฝึกอบรมล่วงหน้า เช่น VGG16 ResNet ได้รับการฝึกอบรมเกี่ยวกับรูปภาพหลายพันภาพ และใช้เพื่อจำแนกคลาสต่างๆ เราจึงไม่จำเป็นต้องฝึกเลเยอร์ของโมเดลที่ผ่านการฝึกอบรมล่วงหน้าอีกครั้ง ดังนั้นเราจึงตั้งค่าเลเยอร์ทั้งหมดของโมเดล VGG16 เป็น "เท็จ"
![]()
ขั้นตอนที่ 4: เนื่องจากเราได้ตรึงเลเยอร์ทั้งหมดและลบเลเยอร์การจัดหมวดหมู่สุดท้ายของโมเดล VGG16 ที่ผ่านการฝึกอบรมล่วงหน้า เราจำเป็นต้องเพิ่มเลเยอร์การจัดหมวดหมู่ที่ด้านบนของโมเดลที่ฝึกอบรมล่วงหน้าเพื่อฝึกบนชุดข้อมูล ดังนั้นเราจึงทำให้เลเยอร์เรียบและแนะนำเลเยอร์หนาแน่นขั้นสุดท้ายด้วย softmax เป็นฟังก์ชันการเปิดใช้งานด้วยตัวอย่างของแบบจำลองการทำนายคลาสไบนารี

ขั้นตอนที่ 5: ในขั้นตอนสุดท้ายนี้ เราพิมพ์บทสรุปของแบบจำลองของเราเพื่อแสดงภาพเลเยอร์ของแบบจำลอง VGG16 ที่ฝึกไว้ล่วงหน้า และสองชั้นที่เราเพิ่มไว้ด้านบนโดยใช้ Transfer Learning
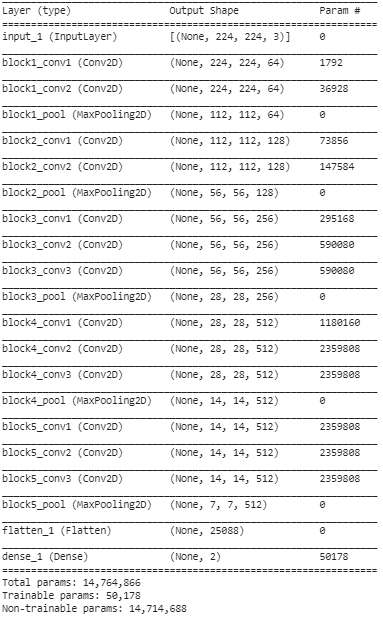
จากข้อมูลสรุปข้างต้น เราจะเห็นได้ว่ามีพารามิเตอร์ทั้งหมดเกือบ 14.76M พารามิเตอร์ ซึ่งมีเพียงประมาณ 50,000 พารามิเตอร์ที่เป็นของสองชั้นสุดท้ายเท่านั้นที่ได้รับอนุญาตให้ใช้เพื่อวัตถุประสงค์ในการฝึกอบรม เนื่องจากเงื่อนไขที่กำหนดไว้ข้างต้นในขั้นตอนที่ 3 ส่วนที่เหลืออีก 14.71 พารามิเตอร์ M เรียกว่าพารามิเตอร์ที่ไม่สามารถฝึกได้
เมื่อดำเนินการตามขั้นตอนเหล่านี้แล้ว เราสามารถดำเนินการตามขั้นตอนเพื่อฝึก Convolutional Neural Network ปกติโดยรวบรวมโมเดลของเราด้วยไฮเปอร์พารามิเตอร์ภายนอก เช่น ตัวเพิ่มประสิทธิภาพและฟังก์ชันการสูญเสีย
หลังจากการคอมไพล์แล้ว เราสามารถเริ่มการฝึกได้โดยใช้ฟังก์ชัน fit สำหรับช่วงเวลาที่กำหนด ด้วยวิธีนี้ เราสามารถใช้วิธีการโอนย้ายการเรียนรู้เพื่อฝึกชุดข้อมูลใดๆ ที่มีโมเดลที่ผ่านการฝึกอบรมล่วงหน้าหลายแบบบนเน็ต และเพิ่มเลเยอร์สองสามชั้นที่ด้านบนของโมเดลตามจำนวนคลาสของข้อมูลการฝึกของเรา
อ่านเพิ่มเติม: อัลกอริธึมการเรียนรู้เชิงลึก [คู่มือฉบับสมบูรณ์]
บทสรุป
ในบทความนี้ เราได้ทำความเข้าใจพื้นฐานเกี่ยวกับ Transfer Learning แอปพลิเคชัน และการนำไปปฏิบัติด้วยตัวอย่าง VGG16 Model ที่ผ่านการฝึกอบรมล่วงหน้าจากไลบรารี keras แล้ว นอกจากนี้ ยังพบว่าการใช้ตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้าจากสองชั้นสุดท้ายของเครือข่ายมีผลมากที่สุดต่อการบรรจบกัน
นอกจากนี้ยังส่งผลให้มีการบรรจบกันเร็วขึ้นเนื่องจากการใช้คุณสมบัติซ้ำ ๆ Transfer Learning มีแอปพลิเคชั่นมากมายในการสร้างแบบจำลองในปัจจุบัน สิ่งสำคัญที่สุดคือ AI สำหรับการใช้งานด้านการดูแลสุขภาพจำเป็นต้องมีโหมดการฝึกอบรมล่วงหน้าหลายโหมด เนื่องจากมีขนาดใหญ่ แม้ว่า Transfer Learning อาจอยู่ในช่วงเริ่มต้น แต่ในอีกไม่กี่ปีข้างหน้า จะเป็นหนึ่งในวิธีการที่ใช้มากที่สุดในการฝึกอบรมชุดข้อมูลขนาดใหญ่ที่มีประสิทธิภาพและความแม่นยำมากขึ้นในอีกไม่กี่ปีข้างหน้า
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
การเรียนรู้เชิงลึกแตกต่างจากการเรียนรู้ของเครื่องอย่างไร
ทั้งแมชชีนเลิร์นนิงและการเรียนรู้เชิงลึกเป็นสาขาเฉพาะภายใต้ร่มที่เรียกว่าปัญญาประดิษฐ์ แมชชีนเลิร์นนิงเป็นหมวดหมู่ย่อยของปัญญาประดิษฐ์ที่เกี่ยวข้องกับวิธีการสอนเครื่องจักรหรือคอมพิวเตอร์ให้เรียนรู้และดำเนินงานที่ชัดเจนโดยมีส่วนร่วมของมนุษย์น้อยที่สุด และการเรียนรู้เชิงลึกเป็นสาขาย่อยของการเรียนรู้ของเครื่อง การเรียนรู้เชิงลึกสร้างขึ้นจากแนวคิดของโครงข่ายประสาทเทียมที่ช่วยให้เครื่องเข้าใจบริบทและตัดสินใจได้เหมือนมนุษย์ แม้ว่าการเรียนรู้เชิงลึกจะใช้ในการประมวลผลข้อมูลดิบจำนวนมาก แต่แมชชีนเลิร์นนิงมักจะคาดหวังอินพุตในรูปแบบของข้อมูลที่มีโครงสร้าง นอกจากนี้ แม้ว่าอัลกอริธึมการเรียนรู้เชิงลึกสามารถทำงานโดยปราศจากการแทรกแซงของมนุษย์ตั้งแต่ศูนย์จนถึงขั้นต่ำ แต่โมเดลการเรียนรู้ของเครื่องก็ยังต้องการการมีส่วนร่วมของมนุษย์ในระดับหนึ่ง
มีข้อกำหนดเบื้องต้นใด ๆ ในการเรียนรู้โครงข่ายประสาทเทียมระดับลึกหรือไม่?
การทำงานในโครงการขนาดใหญ่ในด้านปัญญาประดิษฐ์ โดยเฉพาะอย่างยิ่งการเรียนรู้เชิงลึก คุณจะต้องมีแนวคิดที่ชัดเจนเกี่ยวกับพื้นฐานของโครงข่ายประสาทเทียม ในการพัฒนาพื้นฐานของโครงข่ายประสาทเทียม ก่อนอื่น คุณต้องอ่านหนังสือที่เกี่ยวข้องกับหัวข้อนี้ให้มาก และอ่านบทความและข่าวสารเพื่อให้ทันกับหัวข้อและการพัฒนาที่กำลังเป็นกระแส แต่เมื่อมาถึงข้อกำหนดเบื้องต้นของการเรียนรู้โครงข่ายประสาท คุณไม่สามารถละเลยคณิตศาสตร์ได้ โดยเฉพาะพีชคณิตเชิงเส้น แคลคูลัส สถิติ และความน่าจะเป็น นอกเหนือจากนี้ ความรู้ที่ยุติธรรมเกี่ยวกับภาษาโปรแกรมอย่าง Python, R และ Java ก็จะเป็นประโยชน์เช่นกัน
การถ่ายโอนการเรียนรู้ในปัญญาประดิษฐ์คืออะไร?
เทคนิคการนำองค์ประกอบกลับมาใช้ใหม่จากโมเดลการเรียนรู้ของเครื่องที่ได้รับการฝึกฝนมาก่อนหน้านี้ในรูปแบบใหม่เรียกว่าการเรียนรู้แบบถ่ายโอนในปัญญาประดิษฐ์ หากทั้งสองรุ่นได้รับการออกแบบให้ทำหน้าที่คล้ายคลึงกัน ก็เป็นไปได้ที่จะแบ่งปันความรู้ทั่วไประหว่างกันผ่านการเรียนรู้แบบถ่ายโอน เทคนิคของแบบจำลองการฝึกอบรมนี้ส่งเสริมการใช้ทรัพยากรที่มีอยู่อย่างมีประสิทธิภาพและป้องกันการสูญเสียข้อมูลที่เป็นความลับ ในขณะที่แมชชีนเลิร์นนิงพัฒนาขึ้นเรื่อยๆ การเรียนรู้แบบถ่ายโอนก็มีความสำคัญมากขึ้นเรื่อยๆ ในการพัฒนาปัญญาประดิษฐ์