
Transfer Learning w Deep Learning [Kompleksowy przewodnik]
Opublikowany: 2020-12-07Spis treści
Wstęp
Co to jest głębokie uczenie? Jest to gałąź uczenia maszynowego, która wykorzystuje symulację ludzkiego mózgu, zwaną sieciami neuronowymi. Te sieci neuronowe składają się z neuronów, które są podobne do podstawowej jednostki ludzkiego mózgu.
Neurony tworzą model sieci neuronowej i ta dziedzina badań nazywana jest głębokim uczeniem. Końcowy rezultat sieci neuronowej nazywa się modelem głębokiego uczenia. Przeważnie w uczeniu głębokim używane są dane nieustrukturyzowane, z których model uczenia głębokiego samodzielnie wyodrębnia funkcje przez powtarzane trenowanie na danych.
Takie modele, które są zaprojektowane dla jednego konkretnego zestawu danych, gdy są dostępne jako punkt wyjścia do opracowania innego modelu z innym zestawem danych i funkcji, są znane jako Transfer Learning. Mówiąc prościej, Transfer Learning jest popularną metodą, w której jeden model opracowany dla konkretnego zadania jest ponownie używany jako punkt wyjścia do opracowania modelu dla innego zadania.
Transfer nauki
Transfer Learning był używany przez ludzi od niepamiętnych czasów. Chociaż ta dziedzina uczenia się transferowego jest stosunkowo nowa w uczeniu maszynowym, ludzie wykorzystywali ją z natury w prawie każdej sytuacji.
Zawsze staramy się zastosować wiedzę zdobytą z naszych przeszłych doświadczeń, gdy stajemy przed nowym problemem lub zadaniem i to jest podstawą uczenia transferowego. Na przykład, jeśli umiemy jeździć na rowerze i gdy zostaniemy poproszeni o jazdę na motocyklu, czego wcześniej nie robiliśmy, nasze doświadczenie z jazdą na rowerze zawsze będzie wykorzystywane podczas jazdy na motocyklu, takie jak kierowanie rączką i balansowanie rowerem. Ta prosta koncepcja stanowi podstawę Transfer Learningu.
Aby zrozumieć podstawowe pojęcie Transfer Learning, rozważmy, że model X jest pomyślnie wytrenowany do wykonywania zadania A z modelem M1. Jeśli rozmiar zbioru danych dla zadania B jest zbyt mały, uniemożliwiając efektywne uczenie modelu Y lub powodując nadmierne dopasowanie danych, możemy użyć części modelu M1 jako podstawy do zbudowania modelu Y do wykonania zadania B.

Dlaczego transferowe uczenie się?
Według Andrew Ng, jednego z pionierów dzisiejszego świata w promowaniu sztucznej inteligencji, „Transfer Learning będzie kolejnym motorem sukcesu ML”. Wspomniał o tym w prelekcji wygłoszonej na Konferencji Neuronowe Systemy Przetwarzania Informacji (NIPS 2016). Nie ma wątpliwości, że sukces ML w dzisiejszym przemyśle wynika przede wszystkim z nadzorowanego uczenia się. Z drugiej strony, w przyszłości, przy większej ilości nienadzorowanych i nieoznakowanych danych, uczenie transferowe będzie jedną z technik, która będzie intensywnie wykorzystywana w branży.
W dzisiejszych czasach ludzie wolą używać wstępnie wytrenowanego modelu, który jest już wytrenowany na różnych obrazach, takich jak ImageNet , niż budować od podstaw cały model Convolutional Neural Network. Transfer learning ma kilka zalet, ale głównymi zaletami są oszczędność czasu szkolenia, lepsza wydajność sieci neuronowych i brak potrzeby dużej ilości danych.
Przeczytaj: Najlepsze techniki głębokiego uczenia
Metody Transfer Learning
Ogólnie rzecz biorąc, istnieją dwa sposoby zastosowania uczenia się transferowego – jeden polega na opracowaniu modelu od podstaw, a drugi na wykorzystaniu modelu wstępnie wytrenowanego.
W pierwszym przypadku zwykle budujemy architekturę modelu w zależności od danych uczących, a zdolność modelu do wyodrębniania wag i wzorców z modelu jest dokładnie badana przy użyciu kilku parametrów statystycznych. Po kilku rundach szkolenia, w zależności od wyniku, mogą być wymagane pewne zmiany w modelu, aby osiągnąć optymalną wydajność. W ten sposób możemy zapisać model i wykorzystać go jako początek budowy kolejnego modelu do podobnego zadania.
Drugi przypadek użycia wstępnie wytrenowanych modeli jest zwykle określany jako Transfer Learning. W tym celu musimy szukać wstępnie przeszkolonych modeli, które są udostępniane przez kilka instytucji badawczych i organizacji okresowo udostępnianych do ogólnego użytku. Modele te są dostępne do pobrania w Internecie wraz z ich wagami i mogą być używane do budowania modeli dla podobnych zbiorów danych.
Implementacja transferu uczenia się – model VGG16
Przejdźmy przez aplikację Transfer Learning, wykorzystując wstępnie wytrenowany model o nazwie VGG16.
VGG16 to model Convolutional Neural Network, który został wydany przez profesorów Uniwersytetu Oksfordzkiego w 2014 roku. Był to jeden ze słynnych modeli, który w tym roku wygrał konkurs ILSVR (ImageNet). Nadal jest uznawana za jedną z najlepszych architektur modeli wizyjnych. Ma 16 warstw obciążających, w tym 13 warstw splotowych, 3 w pełni połączone warstwy i miękką warstwę max. Ma około 138 milionów parametrów. Poniżej przedstawiono architekturę modelu VGG16.
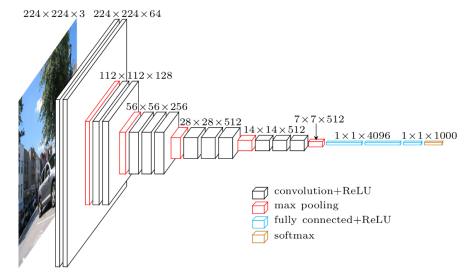
Źródło obrazu: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Krok 1: Pierwszym krokiem jest zaimportowanie modelu VGG16 dostarczonego przez bibliotekę keras we frameworku TensorFlow.

![]()
Krok 2: W kolejnym kroku przypiszemy model do zmiennej „vgg” i pobierzemy wagi z ImageNet podając je jako argument do modelu

Krok 3: Ponieważ te wstępnie wytrenowane modele, takie jak VGG16, ResNet zostały przeszkolone na kilku tysiącach obrazów i są używane do klasyfikowania kilku klas, nie musimy ponownie trenować warstw wstępnie wytrenowanego modelu. Dlatego ustawiamy wszystkie warstwy modelu VGG16 jako „Fałsz”.
![]()
Krok 4: Ponieważ zamroziliśmy wszystkie warstwy i usunęliśmy ostatnie warstwy klasyfikacji ze wstępnie wytrenowanego modelu VGG16, musimy dodać warstwę klasyfikacji do wstępnie wytrenowanego modelu, aby wytrenować go w zestawie danych. W związku z tym spłaszczamy warstwy i wprowadzamy ostateczną warstwę Dense z softmax jako funkcją aktywacji z przykładem binarnego modelu predykcji klas.

Krok 5: W tym ostatnim kroku drukujemy podsumowanie naszego modelu, aby zwizualizować warstwy wstępnie wytrenowanego modelu VGG16 oraz dwie warstwy, które dodaliśmy do niego za pomocą uczenia transferu.
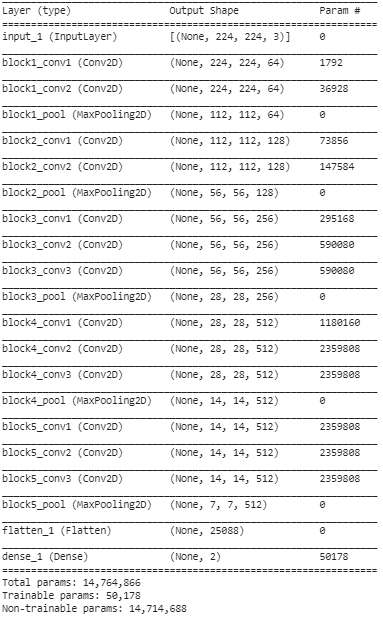
Z powyższego podsumowania widzimy, że łącznie jest blisko 14,76 mln parametrów, z których tylko około 50 000 parametrów należących do dwóch ostatnich warstw może być użytych do celów szkoleniowych ze względu na warunek ustawiony powyżej w kroku 3. Pozostałe 14,71 Parametry M są określane jako parametry nietreningowe.
Po wykonaniu tych kroków możemy wykonać kroki, aby wytrenować zwykłą splotową sieć neuronową, kompilując nasz model z zewnętrznymi hiperparametrami, takimi jak optymalizator i funkcja straty.
Po skompilowaniu możemy rozpocząć szkolenie z wykorzystaniem funkcji fit dla określonej liczby epok. W ten sposób możemy wykorzystać metodę transferu uczenia się do trenowania dowolnego zestawu danych za pomocą kilku takich wstępnie wytrenowanych modeli w sieci i dodawania kilku warstw na górze modelu zgodnie z liczbą klas naszych danych szkoleniowych.
Przeczytaj także: Algorytm głębokiego uczenia [Kompleksowy przewodnik]
Wniosek
W tym artykule omówiliśmy podstawową wiedzę na temat transferu uczenia się, jego zastosowania, a także jego implementacji, korzystając z przykładowego, wstępnie wytrenowanego modelu VGG16 z biblioteki Keras. Oprócz tego stwierdzono, że użycie wytrenowanych wag tylko z dwóch ostatnich warstw sieci ma największy wpływ na zbieżność.
Powoduje to również szybszą konwergencję dzięki wielokrotnemu używaniu funkcji. Transfer Learning ma dziś wiele zastosowań w budowaniu modeli. Co najważniejsze, sztuczna inteligencja w zastosowaniach medycznych wymaga kilku takich przeszkolonych trybów ze względu na swój duży rozmiar. Chociaż Transfer Learning może być w początkowej fazie, w nadchodzących latach będzie to jedna z najczęściej używanych metod uczenia dużych zbiorów danych z większą wydajnością i dokładnością.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czym różni się uczenie głębokie od uczenia maszynowego?
Zarówno uczenie maszynowe, jak i uczenie głębokie to wyspecjalizowane dziedziny pod parasolem zwanej sztuczną inteligencją. Uczenie maszynowe to podkategoria sztucznej inteligencji, która zajmuje się tym, jak można nauczyć maszyny lub komputery uczenia się i wykonywania określonych zadań przy minimalnym zaangażowaniu człowieka. Uczenie głębokie to poddziedzina uczenia maszynowego. Głębokie uczenie opiera się na koncepcjach sztucznych sieci neuronowych, które pomagają maszynom doceniać konteksty i podejmować decyzje jak ludzie. Podczas gdy uczenie głębokie jest wykorzystywane do przetwarzania ogromnych ilości nieprzetworzonych danych, uczenie maszynowe zwykle oczekuje danych wejściowych w postaci danych strukturalnych. Co więcej, chociaż algorytmy uczenia głębokiego mogą działać przy zerowej do minimalnej ingerencji człowieka, modele uczenia maszynowego nadal będą wymagały pewnego zaangażowania człowieka.
Czy są jakieś warunki wstępne uczenia się głębokich sieci neuronowych?
Praca nad dużym projektem z dziedziny sztucznej inteligencji, zwłaszcza głębokiego uczenia, będzie wymagała jasnej i solidnej koncepcji podstaw sztucznych sieci neuronowych. Aby rozwinąć podstawy sieci neuronowych, po pierwsze, musisz przeczytać wiele książek związanych z tym tematem, a także przejrzeć artykuły i wiadomości, aby nadążyć za popularnymi tematami i rozwojem. Ale przechodząc do warunków wstępnych uczenia się sieci neuronowych, nie można ignorować matematyki, zwłaszcza algebry liniowej, rachunku różniczkowego, statystyki i prawdopodobieństwa. Oprócz tego korzystna będzie również dobra znajomość języków programowania, takich jak Python, R i Java.
Czym jest transfer learning w sztucznej inteligencji?
Technika ponownego wykorzystywania elementów z wcześniej wytrenowanego modelu uczenia maszynowego w nowym modelu jest znana jako uczenie transferu w sztucznej inteligencji. Jeżeli oba modele mają spełniać podobne funkcje, możliwe jest dzielenie się między nimi uogólnioną wiedzą poprzez transfer learning. Ta technika modeli szkoleniowych promuje efektywne wykorzystanie dostępnych zasobów i zapobiega marnowaniu niejawnych danych. Ponieważ uczenie maszynowe wciąż ewoluuje, transfer learning nabiera coraz większego znaczenia w rozwoju sztucznej inteligencji.