
Передача обучения в глубоком обучении [Полное руководство]
Опубликовано: 2020-12-07Оглавление
Введение
Что такое глубокое обучение? Это ветвь машинного обучения, в которой используется моделирование человеческого мозга, известное как нейронные сети. Эти нейронные сети состоят из нейронов, которые аналогичны основной единице человеческого мозга.
Нейроны составляют модель нейронной сети, и эта область исследований в целом называется глубоким обучением. Конечный результат нейронной сети называется моделью глубокого обучения. В основном в глубоком обучении используются неструктурированные данные, из которых модель глубокого обучения самостоятельно извлекает функции путем повторного обучения данных.
Такие модели, которые предназначены для одного конкретного набора данных, когда они доступны для использования в качестве отправной точки для разработки другой модели с другим набором данных и функций, известны как трансферное обучение. Проще говоря, трансферное обучение — это популярный метод, при котором одна модель, разработанная для конкретной задачи, снова используется в качестве отправной точки для разработки модели для другой задачи.
Трансферное обучение
Трансферное обучение используется людьми с незапамятных времен. Хотя эта область трансферного обучения является относительно новой для машинного обучения, люди использовали ее почти в каждой ситуации.
Мы всегда пытаемся применить знания, полученные из нашего прошлого опыта, когда сталкиваемся с новой проблемой или задачей, и это является основой трансферного обучения. Например, если мы знаем, как ездить на велосипеде, и когда нас просят покататься на мотоцикле, чего мы раньше не делали, наш опыт езды на велосипеде всегда будет применяться при езде на мотоцикле, например, при управлении рулем и балансировке велосипеда. Эта простая концепция составляет основу трансферного обучения.
Чтобы понять основное понятие трансферного обучения, представьте, что модель X успешно обучена выполнению задачи A с моделью M1. Если размер набора данных для задачи B слишком мал, что препятствует эффективному обучению модели Y или вызывает переобучение данных, мы можем использовать часть модели M1 в качестве основы для построения модели Y для выполнения задачи B.

Зачем передавать обучение?
По словам Эндрю Нг, одного из пионеров современного мира в продвижении искусственного интеллекта, «перенос обучения станет следующим фактором успеха машинного обучения». Он упомянул об этом в своем выступлении на конференции по системам обработки нейронной информации (NIPS 2016). Несомненно, успех машинного обучения в современной отрасли в первую очередь связан с контролируемым обучением. С другой стороны, в будущем, с большим объемом неконтролируемых и немаркированных данных, трансферное обучение станет одним из методов, который будет широко использоваться в отрасли.
В настоящее время люди предпочитают использовать предварительно обученную модель, которая уже обучена на различных изображениях, таких как ImageNet , чем создавать всю модель сверточной нейронной сети с нуля. Трансферное обучение имеет несколько преимуществ, но основными преимуществами являются экономия времени обучения, более высокая производительность нейронных сетей и отсутствие необходимости в большом количестве данных.
Читайте: Лучшие методы глубокого обучения
Методы трансферного обучения
Как правило, существует два способа применения трансферного обучения: один — разработка модели с нуля, а другой — использование предварительно обученной модели.
В первом случае мы обычно строим архитектуру модели в зависимости от обучающих данных, и способность модели извлекать веса и шаблоны из модели тщательно изучается с помощью нескольких статистических параметров. После нескольких циклов обучения, в зависимости от результата, может потребоваться внести некоторые изменения в модель для достижения оптимальной производительности. Таким образом, мы можем сохранить модель и использовать ее в качестве отправной точки для построения другой модели для аналогичной задачи.
Второй случай использования предварительно обученных моделей обычно чаще всего называют трансферным обучением. При этом мы должны искать предварительно обученные модели, которые совместно используются несколькими исследовательскими институтами и организациями, периодически выпускаемыми для общего пользования. Эти модели доступны для загрузки в Интернете вместе с их весами и могут использоваться для построения моделей для аналогичных наборов данных.
Реализация трансферного обучения — модель VGG16
Давайте рассмотрим приложение Transfer Learning, используя предварительно обученную модель, называемую VGG16.
VGG16 — это модель сверточной нейронной сети, выпущенная профессорами Оксфордского университета в 2014 году. Это была одна из известных моделей, выигравших в том же году конкурс ILSVR (ImageNet). Он до сих пор считается одной из лучших архитектур модели машинного зрения. Он имеет 16 весовых слоев, включая 13 сверточных слоев, 3 полносвязных слоя и мягкий максимальный слой. Он имеет около 138 миллионов параметров. Ниже приведена архитектура модели VGG16.
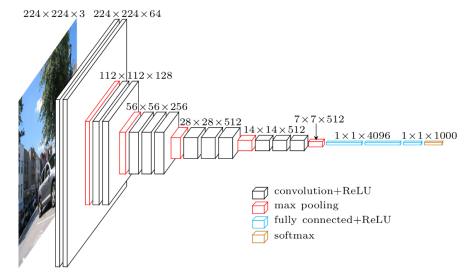
Источник изображения: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7 .
Шаг 1. Первым шагом является импорт модели VGG16, предоставляемой библиотекой keras в инфраструктуре TensorFlow.

![]()
Шаг 2: На следующем шаге мы назначим модель переменной «vgg» и загрузим веса ImageNet, передав их в качестве аргумента модели.

Шаг 3: Поскольку эти предварительно обученные модели, такие как VGG16, ResNet, были обучены на нескольких тысячах изображений и используются для классификации нескольких классов, нам не нужно повторно обучать слои предварительно обученной модели. Следовательно, мы устанавливаем все слои модели VGG16 как «Ложь».
![]()
Шаг 4: Поскольку мы заморозили все слои и удалили последние слои классификации предварительно обученной модели VGG16, нам нужно добавить слой классификации поверх предварительно обученной модели, чтобы обучить ее на наборе данных. Следовательно, мы сглаживаем слои и вводим последний плотный слой с softmax в качестве функции активации с примером модели прогнозирования бинарного класса.

Шаг 5: На этом последнем шаге мы печатаем сводку нашей модели, чтобы визуализировать слои предварительно обученной модели VGG16 и два слоя, которые мы добавили поверх нее с помощью трансферного обучения.
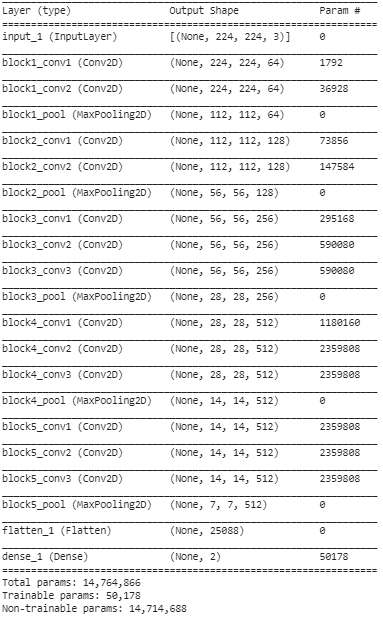
Из приведенной выше сводки мы видим, что общее количество параметров близко к 14,76 млн, из которых только около 50 000 параметров, принадлежащих к последним двум уровням, разрешено использовать для целей обучения из-за условия, установленного выше на шаге 3. Остальные 14,71 M параметры называются необучаемыми параметрами.
После выполнения этих шагов мы можем выполнить шаги для обучения обычной сверточной нейронной сети, скомпилировав нашу модель с внешними гиперпараметрами, такими как оптимизатор и функция потерь.
После компиляции мы можем начать обучение, используя функцию подгонки для заданного количества эпох. Таким образом, мы можем использовать метод трансферного обучения для обучения любого набора данных с несколькими такими предварительно обученными моделями в сети и добавления нескольких слоев поверх модели в соответствии с количеством классов наших обучающих данных.
Читайте также: Алгоритм глубокого обучения [Полное руководство]
Заключение
В этой статье мы рассмотрели базовое понимание трансферного обучения, его применения, а также его реализации с образцом предварительно обученной модели VGG16 из библиотеки keras. В дополнение к этому было обнаружено, что использование предварительно обученных весов только из двух последних слоев сети оказывает наибольшее влияние на сходимость.
Это также приводит к более быстрой сходимости из-за многократного использования функций. Трансферное обучение сегодня имеет множество применений в построении моделей. Что наиболее важно, ИИ для приложений здравоохранения нуждается в нескольких таких предварительно обученных режимах из-за его большого размера. Хотя трансферное обучение может находиться на начальных этапах, в ближайшие годы оно станет одним из наиболее часто используемых методов обучения больших наборов данных с большей эффективностью и точностью.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Чем глубокое обучение отличается от машинного обучения?
И машинное обучение, и глубокое обучение являются специализированными областями под эгидой искусственного интеллекта. Машинное обучение — это подкатегория искусственного интеллекта, которая касается того, как машины или компьютеры можно научить учиться и выполнять определенные задачи с минимальным участием человека. А глубокое обучение — это подполе машинного обучения. Глубокое обучение основано на концепциях искусственных нейронных сетей, которые помогают машинам оценивать контекст и принимать решения, как люди. В то время как глубокое обучение используется для обработки огромных объемов необработанных данных, машинное обучение обычно ожидает ввода в виде структурированных данных. Более того, в то время как алгоритмы глубокого обучения могут работать с нулевым или минимальным вмешательством человека, модели машинного обучения все равно будут нуждаться в некотором уровне участия человека.
Есть ли предпосылки для изучения глубоких нейронных сетей?
Работа над крупномасштабным проектом в области искусственного интеллекта, особенно глубокого обучения, потребует от вас четкого и обоснованного представления об основах искусственных нейронных сетей. Чтобы развить свои основы нейронных сетей, во-первых, вам нужно прочитать много книг, связанных с предметом, а также просматривать статьи и новости, чтобы быть в курсе актуальных тем и событий. Но, переходя к предпосылкам изучения нейронных сетей, нельзя игнорировать математику, особенно линейную алгебру, исчисление, статистику и вероятность. Помимо этого, также будет полезно хорошее знание языков программирования, таких как Python, R и Java.
Что такое трансферное обучение в искусственном интеллекте?
Метод повторного использования элементов из ранее обученной модели машинного обучения в новой модели известен как трансферное обучение в искусственном интеллекте. Если обе модели предназначены для выполнения сходных функций, между ними можно обмениваться обобщенными знаниями посредством трансферного обучения. Этот метод обучения моделей способствует эффективному использованию доступных ресурсов и предотвращает потерю секретных данных. По мере того, как машинное обучение продолжает развиваться, трансферное обучение приобретает все большее значение в развитии искусственного интеллекта.