
情感分析背后的直觉:如何从头开始进行情感分析?
已发表: 2020-12-07目录
介绍
文字是人类感知信息的最重要手段。 人类获得的大部分智能是通过学习和理解周围文本和句子的含义来获得的。
到了一定年龄后,人类会发展出一种内在的反射,以在不知道的情况下理解任何单词/文本的推理。 对于机器来说,这个任务是完全不同的。 为了吸收文本和句子的含义,机器依赖于自然语言处理 (NLP) 的基础。
自然语言处理的深度学习是应用于单词、句子和段落的模式识别,就像计算机视觉是应用于图像像素的模式识别一样。
这些深度学习模型都没有真正理解人类意义上的文本。 相反,这些模型可以映射书面语言的统计结构,这足以解决许多简单的文本任务。 情感分析就是这样一项任务,例如:将字符串或电影评论的情感分类为正面或负面。
这些在工业中也有大规模的应用。 例如:一家商品和服务公司希望收集其针对特定产品收到的正面和负面评论数量的数据,以处理产品生命周期并改善其销售数据并收集客户反馈。
预处理
情感分析的任务可以分解为一个简单的监督机器学习算法,我们通常有一个输入X ,它进入一个预测函数以获得然后我们将我们的预测与真实值Y进行比较,这给了我们成本,然后我们用它来更新我们的文本处理模型的参数为了解决从以前看不见的文本流中提取情绪的任务,原始步骤是收集带有单独正面和负面情绪的标记数据集。 这些情绪可以是:好评或差评、讽刺性评论或非讽刺性评论等。
下一步是创建一个维度为V的向量,其中这个词汇向量将包含我们数据集中存在的每个单词(没有重复的单词) ,并将充当我们机器可以引用的词典。 现在我们预处理词汇向量以去除冗余。 执行以下步骤:
- 消除 URL 和其他重要信息(这无助于确定句子的含义)
- 将字符串标记为单词:假设我们有字符串“I love machine learning”,现在通过标记我们只需将句子分解为单个单词并将其存储在列表中为 [I, love, machine, learning]
- 删除停用词,如“and”、“am”、“or”、“I”等。
- 词干:我们将每个单词转换为其词干形式。 像“tune”、“tuning”和“tuned”这样的词在语义上具有相同的含义,因此将它们简化为“tun”的词干形式将减少词汇量
- 将所有单词转换为小写
总结预处理步骤,让我们看一个例子:假设我们有一个正字符串“我喜欢 upGrad.com 的新产品” 。 最终的预处理字符串是通过删除 URL、将句子标记为单个单词列表、删除诸如“I、am、the、at”之类的停用词,然后将单词“loving”提取为“lov”和“product”来获得的转换为“produ”,最后将其全部转换为小写,从而生成列表[lov, new, produ] 。
特征提取
在对语料库进行预处理之后,下一步将是从句子列表中提取特征。 与所有其他神经网络一样,深度学习模型不会将原始文本作为输入:它们仅适用于数字张量。 因此,需要将预处理的单词列表转换为数值。 这可以通过以下方式完成。 假设给定带有正负字符串的字符串汇编,例如(假设这是数据集) :
| 正弦 | 负字符串 |
|
|
现在要将这些字符串中的每一个转换为维度为 3 的数字向量,我们创建一个字典来将单词及其出现的类(正或负)映射到该单词在其对应类中出现的次数。
| 词汇 | 正频率 | 负频率 |
| 一世 | 3 | 3 |
| 是 | 3 | 3 |
| 快乐的 | 2 | 0 |
| 因为 | 1 | 0 |
| 学习 | 1 | 1 |
| 自然语言处理 | 1 | 1 |
| 伤心 | 0 | 2 |
| 不是 | 0 | 1 |
生成上述字典后,我们分别查看每个字符串,然后将字符串中出现的单词的正负频率数相加,留下未出现在字符串中的单词。 让我们取字符串“我很伤心,我没有学习 NLP”并生成 3 维向量。

“我很难过,我没有学习 NLP”
| 词汇 | 正频率 | 负频率 |
| 一世 | 3 | 3 |
| 是 | 3 | 3 |
| 快乐的 | 2 | 0 |
| 因为 | 1 | 0 |
| 学习 | 1 | 1 |
| 自然语言处理 | 1 | 1 |
| 伤心 | 0 | 2 |
| 不是 | 0 | 1 |
| 总和 = 8 | 总和 = 11 |
我们看到对于字符串“I am sad, I am not learning NLP”,只有两个词“happy,因为”不包含在词汇表中,现在要提取特征并创建所述向量,我们将正负频率相加列分别省略了字符串中不存在的单词的频率数,在这种情况下,我们留下“快乐,因为”。 我们得到的总和为正频率为 8,负频率为 9。
因此,字符串“I am sad, I am not learning NLP”可以表示为向量索引 0 中出现的数字“1”是偏置单元,对于所有即将出现的字符串将保持为“1”,数字“8”、“11”分别表示正频率和负频率的总和。
以类似的方式,可以将数据集中的所有字符串轻松地转换为维度为 3 的向量。
阅读更多:使用 Python 进行情绪分析:动手指南
应用逻辑回归
特征提取可以很容易地理解句子的本质,但机器仍然需要一种更清晰的方法来将看不见的字符串标记为正数或负数。 在这里,逻辑回归发挥作用,它利用 sigmoid 函数为每个向量化字符串输出 0 到 1 之间的概率。

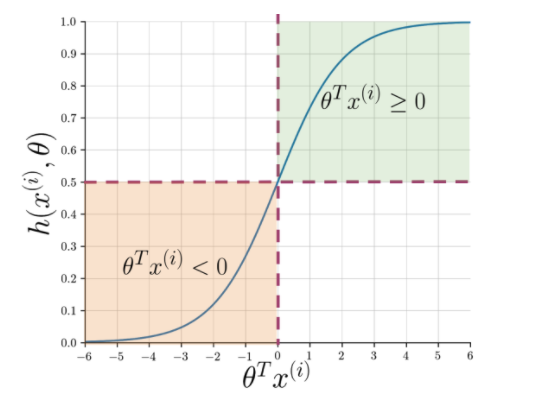
图 1: sigmoid 函数的图形表示法
图 1 显示,当theta和另请阅读:前 4 大数据分析项目理念:从初学者到专家级别
接下来是什么?
情感分析是机器学习中的一个重要课题。 它在多个领域都有大量应用。 如果您想了解有关此主题的更多信息,则可以前往我们的博客并找到许多新资源。
另一方面,如果您想获得全面和结构化的学习体验,并且如果您有兴趣了解更多关于机器学习的信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,专为工作专业人士设计并提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT-B 校友身份、5 多个实用的实践顶点项目和顶级公司的工作协助。
Q1。 为什么随机森林算法最适合机器学习?
随机森林算法属于监督学习算法的范畴,广泛用于开发不同的机器学习模型。 随机森林算法可用于分类和回归模型。 使该算法最适合机器学习的原因在于它可以出色地处理高维信息,因为机器学习主要处理数据子集。 有趣的是,随机森林算法源自决策树算法。 但是,您可以在比使用决策树更短的时间内使用此算法进行训练,因为它只使用特定的特征。 它在机器学习模型中提供了更高的效率,因此更受欢迎。
Q2。 机器学习与深度学习有何不同?
深度学习和机器学习都是我们称之为人工智能的整个保护伞的子领域。 但是,这两个子领域各有不同。 深度学习本质上是机器学习的一个子集。 然而,使用深度学习,机器可以分析视频、图像和其他形式的非结构化数据,而仅使用机器学习很难实现这一点。 机器学习就是让计算机能够在最少的人工干预下自主思考和行动。 相比之下,深度学习用于帮助机器基于类似于人脑的结构进行思考。
Q3。 为什么数据科学家更喜欢随机森林算法?
使用随机森林算法有很多好处,这使其成为数据科学家的首选。 首先,与逻辑和线性回归等其他线性算法相比,它提供了高度准确的结果。 尽管该算法可能难以解释,但根据其基础决策树检查和解释结果更容易。 即使添加了新样本和功能,您也可以同样轻松地使用此算法。 即使缺少某些数据,它也很容易使用。