
深度學習中的遷移學習【綜合指南】
已發表: 2020-12-07目錄
介紹
什麼是深度學習? 它是機器學習的一個分支,它使用被稱為神經網絡的人腦模擬。 這些神經網絡由類似於人腦基本單元的神經元組成。
神經元組成了一個神經網絡模型,這個研究領域統稱為深度學習。 神經網絡的最終結果稱為深度學習模型。 大多數情況下,在深度學習中,使用非結構化數據,深度學習模型通過對數據的重複訓練來自行提取特徵。
為一組特定數據設計的此類模型可用作開發具有不同數據集和特徵的另一個模型的起點,稱為遷移學習。 簡單來說,遷移學習是一種流行的方法,其中為特定任務開發的模型再次用作為另一任務開發模型的起點。
遷移學習
自遠古以來,人類就一直在使用遷移學習。 儘管遷移學習這個領域對於機器學習來說是相對較新的領域,但人類幾乎在所有情況下都使用了這一點。
當我們面對新的問題或任務時,我們總是試圖應用從過去的經驗中獲得的知識,這是遷移學習的基礎。 例如,如果我們知道會騎自行車,並且當被要求騎我們以前沒有做過的摩托車時,我們騎自行車的經驗將始終應用於騎摩托車時,例如轉向把手和平衡自行車。 這個簡單的概念構成了遷移學習的基礎。
為了理解遷移學習的基本概念,假設模型 X 已成功訓練以使用模型 M1 執行任務 A。 如果任務 B 的數據集太小,導致模型 Y 無法有效訓練或導致數據過擬合,我們可以使用模型 M1 的一部分作為基礎構建模型 Y 來執行任務 B。

為什麼遷移學習?
當今世界推廣人工智能的先驅之一 Andrew Ng 表示,“遷移學習將成為機器學習成功的下一個驅動力”。 他在神經信息處理系統會議 (NIPS 2016) 上的一次演講中提到了這一點。 毫無疑問,機器學習在當今行業的成功主要歸功於監督學習。 另一方面,隨著越來越多的無監督和未標記數據的發展,遷移學習將成為行業中廣泛使用的一種技術。
如今,人們更喜歡使用已經在ImageNet等各種圖像上訓練過的預訓練模型,而不是從頭開始構建整個卷積神經網絡模型。 遷移學習有幾個好處,但主要優點是節省訓練時間,神經網絡性能更好,並且不需要大量數據。
閱讀:頂級深度學習技術
遷移學習的方法
一般來說,有兩種應用遷移學習的方法——一種是從頭開始開發模型,另一種是使用預訓練的模型。
在第一種情況下,我們通常根據訓練數據構建模型架構,並通過幾個統計參數仔細研究模型從模型中提取權重和模式的能力。 經過幾輪訓練後,根據結果,可能需要對模型進行一些更改以達到最佳性能。 通過這種方式,我們可以保存模型並將其用作為類似任務構建另一個模型的起點。
使用預訓練模型的第二種情況通常最常被稱為遷移學習。 在這方面,我們必須查找由幾個研究機構和組織共享的預訓練模型,這些模型和組織定期發布以供一般使用。 這些模型及其權重可在 Internet 上下載,並可用於為類似數據集構建模型。
遷移學習實現——VGG16 模型
讓我們通過使用稱為 VGG16 的預訓練模型來了解遷移學習的應用。
VGG16是牛津大學教授於2014年發布的捲積神經網絡模型,是當年贏得ILSVR(ImageNet)競賽的著名模型之一。 它仍然被公認為最好的視覺模型架構之一。 它有 16 個權重層,包括 13 個卷積層、3 個全連接層和一個 soft max 層。 它有大約 1.38 億個參數。 下面給出的是 VGG16 模型的架構。
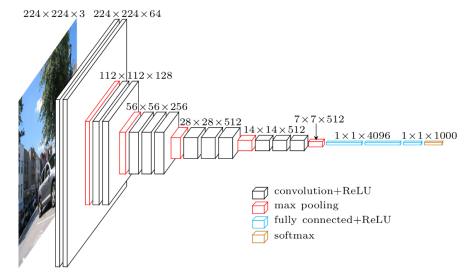
圖片來源: https ://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7

第一步:第一步是導入TensorFlow框架中keras庫提供的VGG16模型。
![]()
第 2 步:在下一步中,我們將模型分配給變量“vgg”,並通過將其作為模型的參數來下載 ImageNet 的權重

步驟 3:由於這些預訓練模型如 VGG16、ResNet 已經在數千張圖像上訓練並用於分類多個類別,因此我們不需要再次訓練預訓練模型的層數。 因此,我們將 VGG16 模型的所有層設置為“False”。
![]()
第 4 步:由於我們已經凍結了所有層並刪除了預訓練 VGG16 模型的最後一個分類層,我們需要在預訓練模型之上添加一個分類層以在數據集上對其進行訓練。 因此,我們將這些層展平並引入一個最終的 Dense 層,該層以 softmax 作為激活函數,並以二元類預測模型為例。

第 5 步:在最後一步中,我們打印模型的摘要,以可視化預訓練的 VGG16 模型的層以及我們利用遷移學習在其上添加的兩層。
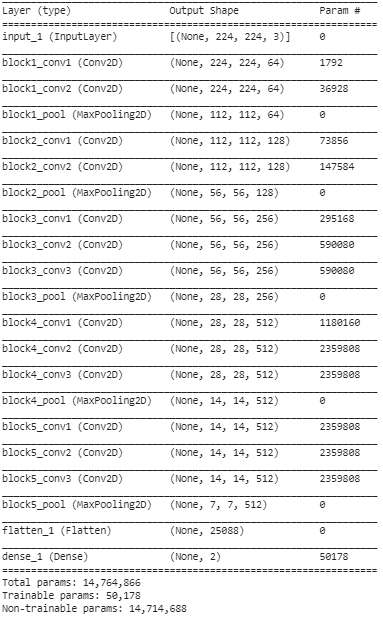
從上面的總結中,我們可以看到總共有接近 14.76M 的參數,其中只有大約 50,000 個屬於最後兩層的參數由於上面步驟 3 中設置的條件而被允許用於訓練目的。剩下的 14.71 M 個參數稱為不可訓練參數。
一旦執行了這些步驟,我們就可以通過使用外部超參數(例如優化器和損失函數)編譯我們的模型來執行訓練常規卷積神經網絡的步驟。
編譯後,我們可以使用 fit 函數開始訓練一組 epoch。 通過這種方式,我們可以利用遷移學習的方法在網絡上用幾個這樣的預訓練模型訓練任何數據集,並根據我們訓練數據的類數在模型之上添加幾層。
另請閱讀:深度學習算法 [綜合指南]
結論
在本文中,我們通過 keras 庫中的示例預訓練 VGG16 模型對遷移學習、其應用及其實現進行了基本了解。 除此之外,已經發現僅使用網絡最後兩層的預訓練權重對收斂的影響最大。
由於重複使用特徵,這也導致更快的收斂。 如今,遷移學習在構建模型方面有很多應用。 最重要的是,用於醫療保健應用的人工智能由於其龐大的規模,需要幾種這樣的預訓練模式。 儘管遷移學習可能還處於起步階段,但在未來幾年,它將成為以更高的效率和準確性訓練大型數據集的最常用方法之一。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
深度學習與機器學習有何不同?
機器學習和深度學習都是稱為人工智能的專業領域。 機器學習是人工智能的一個子類別,它涉及如何教機器或計算機在最少的人為參與的情況下學習和執行確定的任務。 而且,深度學習是機器學習的一個子領域。 深度學習建立在人工神經網絡的概念之上,可以幫助機器理解上下文並像人類一樣做出決定。 雖然深度學習用於處理大量原始數據,但機器學習通常需要結構化數據形式的輸入。 此外,雖然深度學習算法可以在零到最小人為乾擾的情況下運行,但機器學習模型仍需要一定程度的人為參與。
學習深度神經網絡有什麼先決條件嗎?
從事人工智能領域的大型項目,尤其是深度學習,需要你對人工神經網絡的基礎有一個清晰而健全的概念。 要發展您的神經網絡基礎知識,首先,您需要閱讀大量與該主題相關的書籍,並閱讀文章和新聞以跟上熱門話題和發展。 但談到學習神經網絡的先決條件,你不能忽視數學,尤其是線性代數、微積分、統計學和概率。 除此之外,對 Python、R 和 Java 等編程語言有一定的了解也將是有益的。
什麼是人工智能中的遷移學習?
在新模型中重用先前訓練的機器學習模型中的元素的技術被稱為人工智能中的遷移學習。 如果兩個模型都設計為執行相似的功能,則可以通過遷移學習在它們之間共享通用知識。 這種訓練模型的技術促進了可用資源的有效利用,並防止分類數據的浪費。 隨著機器學習的不斷發展,遷移學習在人工智能的發展中越來越重要。