
Transferencia de aprendizaje en aprendizaje profundo [Guía completa]
Publicado: 2020-12-07Tabla de contenido
Introducción
¿Qué es el aprendizaje profundo? Es una rama del aprendizaje automático que utiliza una simulación del cerebro humano que se conoce como redes neuronales. Estas redes neuronales están formadas por neuronas que son similares a la unidad fundamental del cerebro humano.
Las neuronas forman un modelo de red neuronal y este campo de estudio en conjunto se denomina aprendizaje profundo. El resultado final de una red neuronal se denomina modelo de aprendizaje profundo. Principalmente, en el aprendizaje profundo, se utilizan datos no estructurados de los cuales el modelo de aprendizaje profundo extrae características por sí mismo mediante el entrenamiento repetido de los datos.
Dichos modelos que están diseñados para un conjunto particular de datos cuando están disponibles para su uso como punto de partida para desarrollar otro modelo con un conjunto diferente de datos y características, se conocen como Transferencia de aprendizaje. En términos simples, Transfer Learning es un método popular en el que un modelo desarrollado para una tarea en particular se usa nuevamente como punto de partida para desarrollar un modelo para otra tarea.
Transferencia de aprendizaje
Transfer Learning ha sido utilizado por humanos desde tiempos inmemoriales. Aunque este campo del aprendizaje por transferencia es relativamente nuevo para el aprendizaje automático, los humanos lo han utilizado de manera inherente en casi todas las situaciones.
Siempre tratamos de aplicar el conocimiento obtenido de nuestras experiencias pasadas cuando nos enfrentamos a un nuevo problema o tarea y esta es la base del aprendizaje por transferencia. Por ejemplo, si sabemos andar en bicicleta y cuando se nos pide que andemos en moto lo que no hemos hecho antes, nuestra experiencia con andar en bicicleta siempre se aplicará al andar en moto, como manejar el manillar y equilibrar la bicicleta. Este concepto simple forma la base de Transfer Learning.
Para comprender la noción básica de Transfer Learning, considere que un modelo X se entrena con éxito para realizar la tarea A con el modelo M1. Si el tamaño del conjunto de datos para la tarea B es demasiado pequeño, lo que impide que el modelo Y se entrene de manera eficiente o provoca un sobreajuste de los datos, podemos usar una parte del modelo M1 como base para construir el modelo Y para realizar la tarea B.

¿Por qué transferir el aprendizaje?
Según Andrew Ng, uno de los pioneros del mundo actual en la promoción de la Inteligencia Artificial, “Transfer Learning será el próximo impulsor del éxito de ML”. Lo mencionó en una charla dada en la Conferencia sobre Sistemas de Procesamiento de Información Neural (NIPS 2016). No hay duda de que el éxito de ML en la industria actual se debe principalmente al aprendizaje supervisado. Por otro lado, en el futuro, con más cantidad de datos no supervisados ni etiquetados, el aprendizaje por transferencia será una técnica que se utilizará mucho en la industria.
Hoy en día, las personas prefieren usar un modelo previamente entrenado que ya está entrenado en una variedad de imágenes como ImageNet que construir un modelo de red neuronal convolucional completo desde cero. El aprendizaje por transferencia tiene varios beneficios, pero las principales ventajas son el ahorro de tiempo de capacitación, un mejor rendimiento de las redes neuronales y la no necesidad de una gran cantidad de datos.
Leer: Principales técnicas de aprendizaje profundo
Métodos de transferencia de aprendizaje
En general, hay dos formas de aplicar el aprendizaje por transferencia: una es desarrollar un modelo desde cero y la otra es usar un modelo previamente entrenado.
En el primer caso, generalmente construimos una arquitectura de modelo según los datos de entrenamiento y la capacidad del modelo para extraer pesos y patrones del modelo se estudia cuidadosamente con varios parámetros estadísticos. Después de algunas rondas de entrenamiento, dependiendo del resultado, es posible que sea necesario realizar algunos cambios en el modelo para lograr un rendimiento óptimo. De esta forma, podemos guardar el modelo y usarlo como punto de partida para construir otro modelo para una tarea similar.
El segundo caso de uso de modelos pre-entrenados suele denominarse más comúnmente Transfer Learning. En esto, tenemos que buscar modelos pre-entrenados que son compartidos por varias instituciones y organizaciones de investigación publicados periódicamente para uso general. Estos modelos están disponibles para su descarga en Internet junto con sus pesos y se pueden usar para construir modelos para conjuntos de datos similares.
Transferencia de Implementación de Aprendizaje – Modelo VGG16
Repasemos una aplicación de Transfer Learning utilizando un modelo pre-entrenado llamado VGG16.
El VGG16 es un modelo de red neuronal convolucional que fue lanzado por los profesores de la Universidad de Oxford en el año 2014. Fue uno de los modelos famosos que ganó la competencia ILSVR (ImageNet) ese año. Todavía se reconoce como una de las mejores arquitecturas de modelos de visión. Tiene 16 capas de peso que incluyen 13 capas convolucionales, 3 capas completamente conectadas y una capa suave máxima. Tiene aproximadamente 138 millones de parámetros. A continuación se muestra la arquitectura del modelo VGG16.
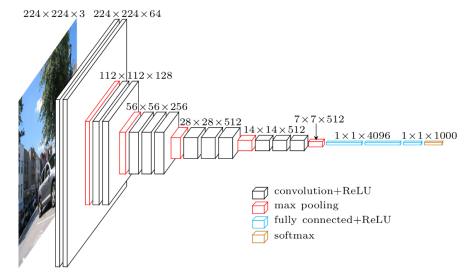
Fuente de la imagen: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Paso 1: el primer paso es importar el modelo VGG16 que proporciona la biblioteca keras en el marco TensorFlow.

![]()
Paso 2: En el siguiente paso, asignaremos el modelo a una variable “vgg” y descargaremos los pesos de ImageNet dándolo como argumento al modelo.

Paso 3: Como estos modelos preentrenados como VGG16, ResNet se han entrenado en varios miles de imágenes y se utilizan para clasificar varias clases, no es necesario volver a entrenar las capas del modelo preentrenado. Por lo tanto, configuramos todas las capas del modelo VGG16 como "Falsas".
![]()
Paso 4: como congelamos todas las capas y eliminamos las últimas capas de clasificación del modelo VGG16 preentrenado, debemos agregar una capa de clasificación sobre el modelo preentrenado para entrenarlo en un conjunto de datos. Por lo tanto, aplanamos las capas e introducimos una capa densa final con softmax como función de activación con un ejemplo de un modelo de predicción de clase binaria.

Paso 5: en este paso final, imprimimos el resumen de nuestro modelo para visualizar las capas del modelo VGG16 preentrenado y las dos capas que agregamos encima utilizando Transfer Learning.
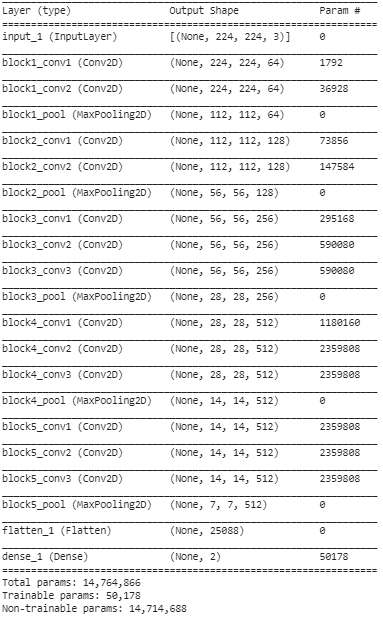
Del resumen anterior, podemos ver que hay cerca de 14,76 millones de parámetros totales, de los cuales solo unos 50 000 parámetros pertenecientes a las dos últimas capas pueden usarse con fines de capacitación debido a la condición establecida anteriormente en el Paso 3. Los 14,71 restantes Los parámetros M se conocen como parámetros no entrenables.
Una vez que se realizan estos pasos, podemos realizar pasos para entrenar la red neuronal convolucional regular compilando nuestro modelo con hiperparámetros externos como el optimizador y la función de pérdida.
Después de compilar, podemos comenzar el entrenamiento usando la función de ajuste para un número determinado de épocas. De esta manera, podemos utilizar el método de transferencia de aprendizaje para entrenar cualquier conjunto de datos con varios de estos modelos previamente entrenados en la red y agregar algunas capas sobre el modelo de acuerdo con la cantidad de clases de nuestros datos de entrenamiento.
Lea también: Algoritmo de aprendizaje profundo [Guía completa]
Conclusión
En este artículo, hemos repasado la comprensión básica de Transfer Learning, su aplicación y también su implementación con un modelo VGG16 preentrenado de muestra de la biblioteca de keras. Además de esto, se ha descubierto que usar los pesos preentrenados solo de las dos últimas capas de la red tiene el mayor efecto sobre la convergencia.
Esto también da como resultado una convergencia más rápida debido al uso repetido de funciones. Transfer Learning tiene muchas aplicaciones en la construcción de modelos hoy en día. Lo que es más importante, la IA para aplicaciones de atención médica necesita varios modos preentrenados debido a su gran tamaño. Si bien Transfer Learning puede estar en sus etapas iniciales, en los próximos años será uno de los métodos más utilizados para entrenar grandes conjuntos de datos con mayor eficiencia y precisión.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿En qué se diferencia el aprendizaje profundo del aprendizaje automático?
Tanto el aprendizaje automático como el aprendizaje profundo son campos especializados bajo el paraguas de la inteligencia artificial. El aprendizaje automático es una subcategoría de la inteligencia artificial que se ocupa de cómo se puede enseñar a las máquinas o computadoras a aprender y realizar tareas definidas con una participación humana mínima. Y, el aprendizaje profundo es un subcampo del aprendizaje automático. El aprendizaje profundo se basa en los conceptos de redes neuronales artificiales que ayudan a las máquinas a apreciar los contextos y decidir como los humanos. Si bien el aprendizaje profundo se usa para procesar volúmenes masivos de datos sin procesar, el aprendizaje automático generalmente espera entradas en forma de datos estructurados. Además, si bien los algoritmos de aprendizaje profundo pueden funcionar con una interferencia humana mínima o nula, los modelos de aprendizaje automático seguirán necesitando cierto nivel de participación humana.
¿Hay algún requisito previo para aprender redes neuronales profundas?
Trabajar en un proyecto a gran escala en el campo de la inteligencia artificial, especialmente el aprendizaje profundo, requerirá que tenga un concepto claro y sólido de los conceptos básicos de las redes neuronales artificiales. Para desarrollar los fundamentos de las redes neuronales, en primer lugar, debe leer muchos libros relacionados con el tema y también leer artículos y noticias para mantenerse al día con los temas y desarrollos de moda. Pero llegando a los requisitos previos para aprender redes neuronales, no puede ignorar las matemáticas, especialmente el álgebra lineal, el cálculo, la estadística y la probabilidad. Aparte de estos, también será beneficioso un conocimiento justo de lenguajes de programación como Python, R y Java.
¿Qué es el aprendizaje por transferencia en inteligencia artificial?
La técnica de reutilizar elementos de un modelo de aprendizaje automático previamente entrenado en un nuevo modelo se conoce como aprendizaje de transferencia en inteligencia artificial. Si ambos modelos están diseñados para realizar funciones similares, es posible compartir conocimiento generalizado entre ellos a través del aprendizaje por transferencia. Esta técnica de entrenamiento de modelos promueve la utilización efectiva de los recursos disponibles y evita el desperdicio de datos clasificados. A medida que el aprendizaje automático sigue evolucionando, el aprendizaje por transferencia sigue adquiriendo una mayor importancia en el desarrollo de la inteligencia artificial.