
数据集增强:创建人工数据[简单解释]
已发表: 2020-12-07目录
介绍
在设计任何机器学习算法时,总是需要在优化和泛化之间进行权衡。 这些词对于新手来说可能看起来太复杂了,但在他们掌握机器学习的早期阶段就知道它们之间的区别肯定会帮助他们理解为什么他们的模型以特定方式表现的潜在工作原理。
优化方面是指调整模型,使其在训练数据上的性能达到峰值。 另一方面,泛化与学习模型在从未见过的数据(即验证集)上的表现有关。
经常有一段时间,在训练数据经过一定数量的 epoch 后,模型的泛化能力停止改进,验证指标开始下降,这就是模型被称为过度拟合的情况,即它开始学习特定于训练数据,但对关联新数据没有用处。
为了解决过度拟合的问题,最好的解决方案是收集更多的训练数据:模型看到的数据越多,它学习新数据表示的概率就越大。 然而,收集更多的训练数据可能比解决一个需要解决的主要问题更昂贵。 为了解决这个限制,我们可以创建假数据并将其添加到训练集中。 这被称为数据增强。
深度数据增强
从图像中学习视觉表示的前提帮助解决了许多计算机视觉问题。 但是,当我们要训练的数据集较小时,这些视觉表示可能会产生误导。 数据增强是克服这一缺点的绝佳策略。
在增强过程中,训练集中的图像通过旋转、缩放、剪切等某些操作进行转换。例如:如果训练集仅包含站立位置的人类图像,那么我们正在尝试构建的分类器可能无法预测人类躺下的图像,因此增强可以通过将训练集的图片旋转 90 度来模拟人类躺下的图像。

这是扩展数据集和增加模型验证指标的一种廉价且重要的方法。
数据增强是一个强大的工具,特别是对于像对象识别这样的分类问题。 像在每个方向上将训练图像平移几个像素这样的操作通常可以大大提高泛化能力。
增强的另一个优点是图像在流上进行转换,这意味着现有数据集不会被覆盖。 当图像被加载到神经网络中进行训练时,将进行增强,因此,这不会增加内存需求并保留数据以进行进一步的实验。
在收集新数据成本高昂的情况下,应用增强等转化技术非常有用,但必须记住不要应用可能会改变训练类现有分布的转换。 例如,如果训练集包含 0 到 9 的手写数字图像,则翻转/旋转数字“6”和“9”不是适当的转换,因为这会使训练集过时。
另请阅读:顶级机器学习数据集项目创意
将数据增强与 TensorFlow 结合使用
可以通过使用 Keras 的ImageDataGenerator API 以 TensorFlow 作为后端来实现增强。 ImageDataGenerator实例可以在训练点对图像执行许多随机变换。 在这种情况下可用的一些流行论点是:
- rotation_range: 0-180 之间的整数值,用于随机旋转图片。
- width_shift_range:围绕其框架水平移动图像以生成更多示例。
- height_shift_range:围绕其框架垂直移动图像以生成更多示例。
- 剪切范围:对图像应用随机剪切变换以生成多个示例。
- zoom_range:要随机缩放的图像的相对部分。
- Horizontal_flip :用于水平翻转图像。
- fill_mode:填充新创建的像素的方法。
下面是演示如何使用ImageDataGenerator实例执行上述转换的代码片段:

- train_datagen = ImageDataGenerator(
- 重新缩放=1./255,
- 旋转范围=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- 剪切范围=0.2,
- 缩放范围=0.2,
- 水平翻转=真,
- 填充模式='最近的')
看到在训练集上应用这些随机变换的结果也很简单。 为此,我们可以通过迭代训练集来显示一些随机增强的训练图像:

图 1:使用增强生成的图像
(图片来自 Francois Chollet 的 Python 深度学习,第 5 章,第 140 页)
图 1 让我们了解了增强如何从单个输入图像生成多个图像,所有图像在表面上彼此不同,只是因为在训练时对它们执行了随机变换。
要理解使用增强策略的真正本质,我们必须理解它对模型的训练和验证指标的影响。 为此,我们将训练两个模型:一个不使用数据增强,另一个将。 为了验证这一点,我们将使用Cats and Dogs数据集,该数据集位于:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
两种模型观察到的准确度曲线如下图所示:
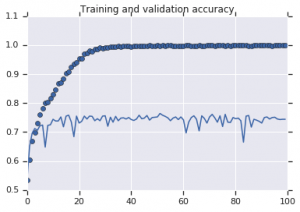
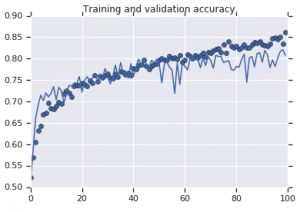
图 2:训练和验证准确性。 左:没有增强的模型。 右:具有随机数据增强变换的模型。
必读:用于情绪分析的顶级已建立数据集
结论
从图 2 可以明显看出,在没有增强策略的情况下训练的模型显示出低泛化能力。 模型在验证集上的表现与训练集上的表现不相上下。 这意味着模型已经过拟合。
另一方面,使用增强策略的第二个模型显示了出色的指标,验证准确度与训练准确度一样高。 这证明了在模型显示出过度拟合迹象的情况下,使用数据集增强技术变得多么有用。
如果您对学习情感分析和相关技术(如人工智能和机器学习)进一步感兴趣,您可以查看我们的机器学习和人工智能 PG 文凭课程。