
딥 러닝에서의 전이 학습 [종합 가이드]
게시 됨: 2020-12-07목차
소개
딥 러닝이란 무엇입니까? 그것은 신경망으로 알려진 인간 두뇌의 시뮬레이션을 사용하는 기계 학습의 한 분야입니다. 이러한 신경망은 인간 두뇌의 기본 단위와 유사한 뉴런으로 구성됩니다.
뉴런은 신경망 모델을 구성하며 이 연구 분야를 모두 딥 러닝이라고 합니다. 신경망의 최종 결과를 딥 러닝 모델이라고 합니다. 딥 러닝에서는 주로 딥 러닝 모델이 데이터에 대한 반복 학습을 통해 자체적으로 특징을 추출하는 비정형 데이터를 사용합니다.
다른 데이터 및 기능 세트를 사용하여 다른 모델을 개발하기 위한 시작점으로 사용할 수 있을 때 특정 데이터 세트를 위해 설계된 이러한 모델을 전이 학습이라고 합니다. 간단히 말해서, Transfer Learning은 특정 작업을 위해 개발된 하나의 모델을 다른 작업을 위한 모델을 개발하기 위한 출발점으로 다시 사용하는 인기 있는 방법입니다.
전이 학습
Transfer Learning은 태곳적부터 인간에 의해 활용되어 왔습니다. 이 전이 학습 분야는 기계 학습에 비교적 새롭지만 인간은 본질적으로 거의 모든 상황에서 이것을 사용했습니다.
우리는 항상 새로운 문제나 과제에 직면할 때 과거 경험에서 얻은 지식을 적용하려고 노력하며 이것이 전이 학습의 기초입니다. 예를 들어, 우리가 자전거를 탈 줄 알고 전에 한 번도 해보지 않은 오토바이를 타라고 요청을 받으면 핸들을 조종하고 자전거의 균형을 잡는 것과 같이 오토바이를 탈 때 자전거를 탈 때의 경험이 항상 적용됩니다. 이 간단한 개념은 Transfer Learning의 기반을 형성합니다.
Transfer Learning의 기본 개념을 이해하려면 모델 X가 모델 M1을 사용하여 작업 A를 수행하도록 성공적으로 훈련되었다고 가정하십시오. 작업 B에 대한 데이터 세트의 크기가 너무 작아서 모델 Y가 효율적으로 훈련되지 않거나 데이터가 과적합되는 경우 모델 M1의 일부를 기반으로 사용하여 작업 B를 수행하기 위한 모델 Y를 구축할 수 있습니다.

왜 전이 학습인가?
오늘날 인공 지능 촉진 분야의 선구자 중 한 명인 Andrew Ng에 따르면 "전이 학습은 ML 성공의 다음 동인이 될 것"입니다. 그는 신경 정보 처리 시스템에 관한 회의(NIPS 2016)에서 한 연설에서 이를 언급했습니다. 오늘날 업계에서 ML의 성공이 주로 지도 학습 덕분이라는 것은 의심의 여지가 없습니다. 반면에 비지도 및 레이블이 지정되지 않은 데이터의 양이 증가함에 따라 전이 학습은 업계에서 많이 활용될 기술 중 하나가 될 것입니다.
요즘 사람들은 전체 Convolutional Neural Network 모델을 처음부터 구축하는 것보다 ImageNet 과 같은 다양한 이미지에 대해 이미 훈련된 사전 훈련된 모델을 사용하는 것을 선호합니다 . 전이 학습에는 몇 가지 이점이 있지만 주요 이점은 훈련 시간을 절약하고 신경망의 성능을 향상시키며 많은 데이터가 필요하지 않다는 것입니다.
읽기: 최고의 딥 러닝 기술
전이 학습 방법
일반적으로 전이 학습을 적용하는 두 가지 방법이 있습니다. 하나는 모델을 처음부터 개발하는 것이고 다른 하나는 사전 훈련된 모델을 사용하는 것입니다.
첫 번째 경우, 우리는 일반적으로 훈련 데이터에 따라 모델 아키텍처를 구축하고 모델에서 가중치와 패턴을 추출하는 모델의 능력은 여러 통계 매개변수를 사용하여 주의 깊게 연구됩니다. 몇 번의 훈련 후 결과에 따라 최적의 성능을 달성하기 위해 모델을 약간 변경해야 할 수 있습니다. 이러한 방식으로 모델을 저장하고 유사한 작업을 위한 다른 모델을 구축하기 위한 시작으로 사용할 수 있습니다.
사전 훈련된 모델을 사용하는 두 번째 경우는 일반적으로 Transfer Learning이라고 합니다. 여기서 우리는 일반 사용을 위해 주기적으로 출시되는 여러 연구 기관 및 조직에서 공유하는 사전 훈련된 모델을 찾아야 합니다. 이러한 모델은 가중치와 함께 인터넷에서 다운로드할 수 있으며 유사한 데이터 세트에 대한 모델을 구축하는 데 사용할 수 있습니다.
전이 학습 구현 – VGG16 모델
VGG16이라는 사전 훈련된 모델을 활용하여 Transfer Learning을 적용해 보겠습니다.
VGG16은 2014년 옥스포드 대학교 교수들이 발표한 Convolutional Neural Network 모델입니다. 그 해 ILSVR(ImageNet) 대회에서 우승한 유명한 모델 중 하나입니다. 여전히 최고의 비전 모델 아키텍처 중 하나로 인정받고 있습니다. 13개의 convolutional layer, 3개의 fully connected layer, soft max layer를 포함한 16개의 weight layer를 가지고 있습니다. 약 1억 3,800만 개의 매개변수가 있습니다. 아래는 VGG16 모델의 아키텍처입니다.
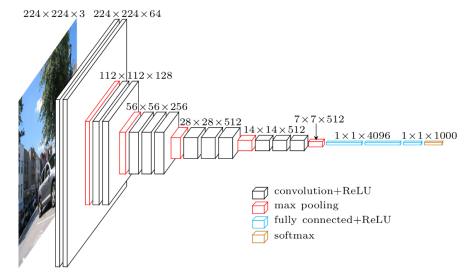
이미지 출처: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7

1단계: 첫 번째 단계는 TensorFlow 프레임워크의 keras 라이브러리에서 제공하는 VGG16 모델을 가져오는 것입니다.
![]()
2단계: 다음 단계에서 모델을 변수 "vgg"에 할당하고 모델에 인수로 제공하여 ImageNet의 가중치를 다운로드합니다.

3단계: VGG16, ResNet과 같은 사전 훈련된 모델은 수천 개의 이미지에 대해 훈련되고 여러 클래스를 분류하는 데 사용되므로 사전 훈련된 모델의 레이어를 다시 한 번 훈련할 필요가 없습니다. 따라서 VGG16 모델의 모든 레이어를 "False"로 설정합니다.
![]()
4단계: 모든 계층을 고정하고 사전 훈련된 VGG16 모델의 마지막 분류 계층을 제거했으므로 사전 훈련된 모델 위에 분류 계층을 추가하여 데이터 세트에서 훈련해야 합니다. 따라서 레이어를 평면화하고 이진 클래스 예측 모델의 예를 사용하여 활성화 함수로 softmax를 사용하는 최종 Dense 레이어를 도입합니다.

5단계: 이 마지막 단계에서는 사전 훈련된 VGG16 모델의 레이어와 Transfer Learning을 사용하여 그 위에 추가한 두 레이어를 시각화하기 위해 모델 요약을 인쇄합니다.
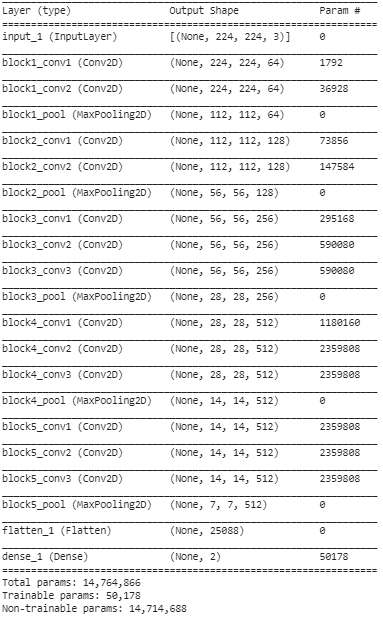
위의 요약에서 우리는 14.76M에 가까운 총 매개변수가 있음을 알 수 있습니다. 그 중 마지막 두 계층에 속하는 약 50,000개의 매개변수만 3단계에서 위에서 설정한 조건으로 인해 훈련 목적으로 사용할 수 있습니다. 나머지 14.71 M개의 매개변수를 훈련 불가능한 매개변수라고 합니다.
이러한 단계가 수행되면 최적화 및 손실 함수와 같은 외부 하이퍼파라미터로 모델을 컴파일하여 일반 컨볼루션 신경망을 훈련하는 단계를 수행할 수 있습니다.
컴파일 후, 우리는 정해진 epoch 수에 대해 fit 함수를 사용하여 훈련을 시작할 수 있습니다. 이러한 방식으로, 우리는 네트워크에서 사전 훈련된 여러 모델로 데이터 세트를 훈련하고 훈련 데이터의 클래스 수에 따라 모델 위에 몇 개의 레이어를 추가하기 위해 전이 학습 방법을 활용할 수 있습니다.
더 읽어보기: 딥 러닝 알고리즘 [종합 가이드]
결론
이 기사에서 우리는 Transfer Learning에 대한 기본적인 이해와 그 적용, 그리고 keras 라이브러리에서 미리 훈련된 샘플 VGG16 모델을 사용한 구현을 살펴보았습니다. 이 외에도 네트워크의 마지막 두 계층에서만 사전 훈련된 가중치를 사용하는 것이 수렴에 가장 큰 영향을 미치는 것으로 밝혀졌습니다.
또한 반복되는 기능 사용으로 인해 수렴 속도가 빨라집니다. Transfer Learning은 오늘날 모델을 구축하는 데 많은 응용 프로그램을 가지고 있습니다. 가장 중요한 것은 의료 애플리케이션을 위한 AI는 크기가 크기 때문에 사전 훈련된 모드가 여러 개 필요하다는 것입니다. Transfer Learning은 초기 단계에 있을 수 있지만 앞으로 몇 년 동안 더 효율적이고 정확하게 대규모 데이터 세트를 훈련하는 데 가장 많이 사용되는 방법 중 하나가 될 것입니다.
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI PG 디플로마를 확인하세요. 이 PG 디플로마는 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT- B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
딥 러닝은 머신 러닝과 어떻게 다른가요?
머신 러닝과 딥 러닝은 모두 인공 지능이라는 우산 아래 전문 분야입니다. 기계 학습은 최소한의 인간 개입으로 명확한 작업을 배우고 수행하도록 기계나 컴퓨터를 가르칠 수 있는 방법을 다루는 인공 지능의 하위 범주입니다. 그리고 딥 러닝은 머신 러닝의 하위 분야입니다. 딥 러닝은 기계가 컨텍스트를 인식하고 인간처럼 결정하는 데 도움이 되는 인공 신경망 개념을 기반으로 합니다. 딥 러닝은 방대한 양의 원시 데이터를 처리하는 데 사용되지만 머신 러닝은 일반적으로 구조화된 데이터 형태의 입력을 기대합니다. 더욱이 딥 러닝 알고리즘은 사람의 간섭이 전혀 없이 작동할 수 있지만 기계 학습 모델은 여전히 어느 정도 사람의 개입이 필요합니다.
심층 신경망을 배우기 위한 전제 조건이 있습니까?
인공 지능, 특히 딥 러닝 분야에서 대규모 프로젝트를 진행하려면 인공 신경망의 기본에 대한 명확하고 건전한 개념이 필요합니다. 신경망의 기초를 개발하려면 먼저 해당 주제와 관련된 많은 책을 읽고 기사와 뉴스를 통해 최신 주제와 발전을 따라가야 합니다. 그러나 신경망 학습의 전제 조건에 도달하면 수학, 특히 선형 대수학, 미적분학, 통계 및 확률을 무시할 수 없습니다. 이 외에도 Python, R 및 Java와 같은 프로그래밍 언어에 대한 공정한 지식도 도움이 될 것입니다.
인공 지능에서 전이 학습이란 무엇입니까?
이전에 훈련된 기계 학습 모델의 요소를 새 모델에서 재사용하는 기술을 인공 지능에서 전이 학습이라고 합니다. 두 모델이 유사한 기능을 수행하도록 설계되면 전이 학습을 통해 일반화된 지식을 공유할 수 있습니다. 이러한 훈련 모델 기술은 사용 가능한 리소스의 효과적인 활용을 촉진하고 분류된 데이터의 낭비를 방지합니다. 기계 학습이 계속 진화함에 따라 전이 학습은 인공 지능 개발에서 점점 더 중요해지고 있습니다.