
Transfer Pembelajaran dalam Pembelajaran Mendalam [Panduan Komprehensif]
Diterbitkan: 2020-12-07Daftar isi
pengantar
Apa itu Pembelajaran Mendalam? Ini adalah cabang dari Machine Learning yang menggunakan simulasi otak manusia yang dikenal sebagai jaringan saraf. Jaringan saraf ini terdiri dari neuron yang mirip dengan unit dasar otak manusia.
Neuron membentuk model jaringan saraf dan bidang studi ini secara keseluruhan disebut sebagai pembelajaran mendalam. Hasil akhir dari neural network disebut model deep learning. Sebagian besar, dalam pembelajaran mendalam, data tidak terstruktur digunakan dari mana model pembelajaran mendalam mengekstrak fitur sendiri dengan pelatihan berulang pada data.
Model seperti yang dirancang untuk satu set data tertentu bila tersedia untuk digunakan sebagai titik awal untuk mengembangkan model lain dengan set data dan fitur yang berbeda, dikenal sebagai Transfer Learning. Secara sederhana, Transfer Learning adalah metode populer di mana satu model yang dikembangkan untuk tugas tertentu digunakan lagi sebagai titik awal untuk mengembangkan model untuk tugas lain.
Pindah Belajar
Transfer Learning telah dimanfaatkan oleh manusia sejak dahulu kala. Meskipun bidang pembelajaran transfer ini relatif baru untuk pembelajaran mesin, manusia telah menggunakan ini secara inheren di hampir setiap situasi.
Kami selalu berusaha menerapkan pengetahuan yang diperoleh dari pengalaman masa lalu kami ketika kami menghadapi masalah atau tugas baru dan ini adalah dasar dari transfer learning. Misalnya, jika kita tahu cara mengendarai sepeda dan ketika diminta untuk mengendarai sepeda motor yang belum pernah kita lakukan sebelumnya, pengalaman kita mengendarai sepeda akan selalu diterapkan saat mengendarai sepeda motor seperti kemudi pegangan dan keseimbangan sepeda. Konsep sederhana inilah yang menjadi dasar dari Transfer Learning.
Untuk memahami pengertian dasar Transfer Learning, perhatikan model X yang berhasil dilatih untuk melakukan tugas A dengan model M1. Jika ukuran dataset untuk tugas B terlalu kecil yang mencegah model Y dari pelatihan secara efisien atau menyebabkan kelebihan data, kita dapat menggunakan bagian dari model M1 sebagai dasar untuk membangun model Y untuk melakukan tugas B.

Mengapa Pindah Belajar?
Menurut Andrew Ng, salah satu pelopor dunia saat ini dalam mempromosikan Kecerdasan Buatan, “Transfer Learning akan menjadi pendorong kesuksesan ML berikutnya”. Dia menyebutkannya dalam sebuah ceramah yang diberikan pada Conference on Neural Information Processing Systems (NIPS 2016). Tidak diragukan lagi bahwa keberhasilan ML di industri saat ini terutama disebabkan oleh pembelajaran yang diawasi. Di sisi lain, ke depan, dengan semakin banyaknya jumlah unsupervised dan unlabeled data, transfer learning akan menjadi salah satu teknik yang akan banyak digunakan di industri.
Saat ini, orang lebih suka menggunakan model pra-terlatih yang sudah dilatih pada berbagai gambar seperti ImageNet daripada membangun seluruh model Jaringan Saraf Konvolusi dari awal. Transfer learning memiliki beberapa keuntungan, tetapi keuntungan utama adalah menghemat waktu pelatihan, kinerja jaringan saraf yang lebih baik, dan tidak membutuhkan banyak data.
Baca: Teknik Pembelajaran Mendalam Teratas
Metode Pembelajaran Transfer
Secara umum, ada dua cara untuk menerapkan pembelajaran transfer – Salah satunya adalah mengembangkan model dari awal dan yang lainnya adalah dengan menggunakan model yang telah dilatih sebelumnya.
Dalam kasus pertama, kami biasanya membangun arsitektur model tergantung pada data pelatihan dan kemampuan model untuk mengekstraksi bobot dan pola dari model yang dipelajari dengan cermat dengan beberapa parameter statistik. Setelah beberapa putaran pelatihan, tergantung pada hasilnya, beberapa perubahan mungkin perlu dilakukan pada model untuk mencapai kinerja yang optimal. Dengan cara ini, kita dapat menyimpan model dan menggunakannya sebagai awal untuk membangun model lain untuk tugas serupa.
Kasus kedua menggunakan model pra-terlatih biasanya paling sering disebut Transfer Learning. Dalam hal ini, kita harus mencari model pra-pelatihan yang dibagikan oleh beberapa lembaga penelitian dan organisasi yang dirilis secara berkala untuk penggunaan umum. Model ini tersedia untuk diunduh di internet beserta bobotnya dan dapat digunakan untuk membuat model untuk kumpulan data serupa.
Implementasi Pembelajaran Transfer – Model VGG16
Mari kita telusuri aplikasi Transfer Learning dengan memanfaatkan model pra-terlatih yang disebut VGG16.
VGG16 adalah model Jaringan Saraf Konvolusi yang dirilis oleh Profesor Universitas Oxford pada tahun 2014. Itu adalah salah satu model terkenal yang memenangkan Kompetisi ILSVR (ImageNet) tahun itu. Itu masih diakui sebagai salah satu arsitektur model visi terbaik. Ini memiliki 16 lapisan berat termasuk 13 lapisan konvolusi, 3 lapisan yang terhubung penuh, dan lapisan maks yang lembut. Ini memiliki sekitar 138 juta parameter. Diberikan di bawah ini adalah Arsitektur Model VGG16.
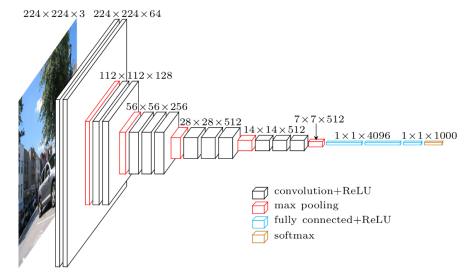
Sumber Gambar: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Langkah 1: Langkah pertama adalah mengimpor model VGG16 yang disediakan oleh perpustakaan keras di kerangka kerja TensorFlow.
![]()

Langkah 2: Pada langkah berikutnya, kita akan menetapkan model ke variabel "vgg" dan mengunduh bobot ImageNet dengan memberikannya sebagai argumen ke model

Langkah 3: Karena model pra-pelatihan ini seperti VGG16, ResNet telah dilatih pada beberapa ribu gambar dan digunakan untuk mengklasifikasikan beberapa kelas, kita tidak perlu melatih lapisan model pra-latihan sekali lagi. Oleh karena itu, kami menetapkan semua lapisan model VGG16 sebagai "Salah".
![]()
Langkah 4: Karena kita telah membekukan semua lapisan dan menghapus lapisan klasifikasi terakhir dari model VGG16 yang telah dilatih sebelumnya, kita perlu menambahkan lapisan klasifikasi di atas model yang telah dilatih sebelumnya untuk melatihnya pada kumpulan data. Oleh karena itu, kami meratakan lapisan dan memperkenalkan lapisan Dense akhir dengan softmax sebagai fungsi aktivasi dengan contoh model prediksi kelas biner.

Langkah 5: Pada langkah terakhir ini, kami mencetak ringkasan model kami untuk memvisualisasikan lapisan model VGG16 yang telah dilatih sebelumnya dan dua lapisan yang kami tambahkan di atasnya menggunakan Transfer Learning.
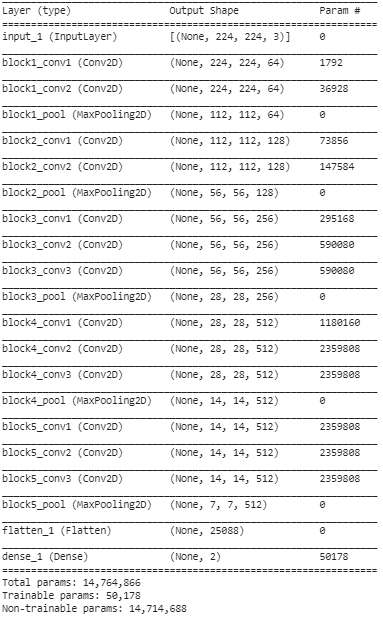
Dari ringkasan di atas, kita dapat melihat bahwa ada hampir 14,76 juta total parameter dimana hanya sekitar 50.000 parameter milik dua lapisan terakhir yang diizinkan untuk digunakan untuk tujuan pelatihan karena kondisi yang ditetapkan di atas pada Langkah 3. Sisanya 14,71 Parameter M disebut sebagai parameter yang tidak dapat dilatih.
Setelah langkah-langkah ini dilakukan, kita dapat melakukan langkah-langkah untuk melatih Jaringan Neural Convolutional biasa dengan mengkompilasi model kita dengan hyperparameter eksternal seperti pengoptimal dan fungsi kerugian.
Setelah kompilasi, kita dapat memulai pelatihan menggunakan fungsi fit untuk sejumlah epoch yang ditetapkan. Dengan cara ini, kita dapat memanfaatkan metode transfer learning untuk melatih dataset apa pun dengan beberapa model yang telah dilatih sebelumnya di internet dan menambahkan beberapa lapisan di atas model sesuai dengan jumlah kelas dari data pelatihan kita.
Baca Juga: Algoritma Deep Learning [Panduan Komprehensif]
Kesimpulan
Pada artikel ini, kita telah melalui pemahaman dasar tentang Transfer Learning, aplikasinya, dan juga implementasinya dengan contoh Model VGG16 yang telah dilatih sebelumnya dari perpustakaan keras. Selain itu, telah ditemukan bahwa menggunakan bobot yang telah dilatih sebelumnya hanya dari dua lapisan terakhir jaringan memiliki efek terbesar pada konvergensi.
Ini juga menghasilkan konvergensi yang lebih cepat karena penggunaan fitur yang berulang. Transfer Learning memiliki banyak aplikasi dalam membangun model saat ini. Yang terpenting, AI untuk aplikasi perawatan kesehatan membutuhkan beberapa mode pra-terlatih karena ukurannya yang besar. Meskipun, Transfer Learning mungkin masih dalam tahap awal, di tahun-tahun mendatang ini akan menjadi salah satu metode yang paling banyak digunakan untuk melatih kumpulan data besar dengan lebih efisien dan akurat.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Bagaimana pembelajaran mendalam berbeda dari pembelajaran mesin?
Baik pembelajaran mesin dan pembelajaran mendalam adalah bidang khusus di bawah payung yang disebut kecerdasan buatan. Pembelajaran mesin adalah subkategori kecerdasan buatan yang berhubungan dengan bagaimana mesin atau komputer dapat diajarkan untuk belajar dan melakukan tugas-tugas tertentu dengan keterlibatan manusia yang minimal. Dan, pembelajaran mendalam adalah subbidang pembelajaran mesin. Pembelajaran mendalam dibangun di atas konsep jaringan saraf tiruan yang membantu mesin menghargai konteks dan memutuskan seperti manusia. Sementara pembelajaran mendalam digunakan untuk memproses sejumlah besar data mentah, pembelajaran mesin biasanya mengharapkan input dalam bentuk data terstruktur. Selain itu, sementara algoritme pembelajaran mendalam dapat berfungsi dengan gangguan manusia nol hingga minimum, model pembelajaran mesin masih memerlukan beberapa tingkat keterlibatan manusia.
Apakah ada prasyarat untuk mempelajari jaringan saraf dalam?
Bekerja pada proyek skala besar di bidang kecerdasan buatan, terutama pembelajaran mendalam, akan membutuhkan Anda untuk memiliki konsep yang jelas dan masuk akal tentang dasar-dasar jaringan saraf tiruan. Untuk mengembangkan dasar-dasar jaringan saraf Anda, pertama-tama, Anda perlu membaca banyak buku yang berkaitan dengan subjek dan juga membaca artikel dan berita untuk mengikuti topik dan perkembangan yang sedang tren. Tetapi datang ke prasyarat belajar jaringan saraf, Anda tidak dapat mengabaikan matematika, terutama aljabar linier, kalkulus, statistik, dan probabilitas. Selain itu, pengetahuan yang adil tentang bahasa pemrograman seperti Python, R, dan Java juga akan bermanfaat.
Apa itu transfer learning dalam kecerdasan buatan?
Teknik menggunakan kembali elemen dari model pembelajaran mesin yang dilatih sebelumnya dalam model baru dikenal sebagai pembelajaran transfer dalam kecerdasan buatan. Jika kedua model dirancang untuk melakukan fungsi yang serupa, dimungkinkan untuk berbagi pengetahuan umum di antara mereka melalui pembelajaran transfer. Teknik model pelatihan ini mempromosikan pemanfaatan sumber daya yang tersedia secara efektif dan mencegah pemborosan data rahasia. Karena pembelajaran mesin terus berkembang, pembelajaran transfer terus mendapatkan signifikansi yang lebih besar dalam pengembangan kecerdasan buatan.