
ディープラーニングにおける転移学習[包括的なガイド]
公開: 2020-12-07目次
序章
ディープラーニングとは何ですか? これは、ニューラルネットワークとして知られている人間の脳のシミュレーションを使用する機械学習のブランチです。 これらのニューラルネットワークは、人間の脳の基本単位に似たニューロンで構成されています。
ニューロンはニューラルネットワークモデルを構成し、この研究分野はすべてディープラーニングと呼ばれます。 ニューラルネットワークの最終結果は、深層学習モデルと呼ばれます。 ほとんどの場合、深層学習では、非構造化データが使用され、深層学習モデルは、データのトレーニングを繰り返すことにより、それ自体で特徴を抽出します。
異なるデータセットと機能を備えた別のモデルを開発するための開始点として使用できる場合に、ある特定のデータセット用に設計されたこのようなモデルは、転移学習として知られています。 簡単に言うと、転移学習は、特定のタスク用に開発された1つのモデルが、別のタスク用のモデルを開発するための開始点として再び使用される一般的な方法です。
転移学習
太古の昔から、転移学習は人間によって利用されてきました。 この転移学習の分野は機械学習にとって比較的新しいものですが、人間はほとんどすべての状況でこれを本質的に使用しています。
新しい問題や課題に直面したとき、私たちは常に過去の経験から得た知識を応用しようとします。これが転移学習の基礎です。 たとえば、自転車に乗ることを知っていて、これまでに行ったことのないバイクに乗るように頼まれた場合、ハンドルのステアリングやバイクのバランス調整など、バイクに乗るときの経験は常に適用されます。 この単純な概念は、転移学習の基礎を形成します。
転移学習の基本的な概念を理解するために、モデルXがモデルM1でタスクAを実行するように正常にトレーニングされていると考えてください。 タスクBのデータセットのサイズが小さすぎて、モデルYが効率的にトレーニングできなかったり、データの過剰適合が発生したりする場合は、モデルM1の一部をベースとして使用して、タスクBを実行するモデルYを構築できます。

なぜ転移学習?
人工知能の推進における今日の世界のパイオニアの1人であるAndrewNgによると、「転送学習はMLの成功の次の推進力になるでしょう」。 彼は、Neural Information Processing Systemsに関する会議(NIPS 2016)で行われた講演でそれについて言及しました。 今日の業界でのMLの成功は、主に教師あり学習によるものであることは間違いありません。 一方、今後、教師なしデータやラベルなしデータが増えるにつれ、転移学習は業界で多用される手法の1つになるでしょう。
今日、人々は、畳み込みニューラルネットワークモデル全体を最初から構築するよりも、 ImageNetなどのさまざまな画像ですでにトレーニングされている事前トレーニング済みモデルを使用することを好みます。 転移学習にはいくつかの利点がありますが、主な利点は、トレーニング時間の節約、ニューラルネットワークのパフォーマンスの向上、および大量のデータを必要としないことです。
読む:トップディープラーニングテクニック
転移学習の方法
一般に、転移学習を適用する方法は2つあります。1つはモデルを最初から開発する方法で、もう1つは事前にトレーニングされたモデルを使用する方法です。
最初のケースでは、通常、トレーニングデータに応じてモデルアーキテクチャを構築し、モデルから重みとパターンを抽出するモデルの能力を、いくつかの統計パラメータを使用して慎重に調査します。 数ラウンドのトレーニングの後、結果によっては、最適なパフォーマンスを実現するためにモデルにいくつかの変更を加える必要がある場合があります。 このようにして、モデルを保存し、同様のタスクのために別のモデルを構築するための開始点として使用できます。
事前にトレーニングされたモデルを使用する2番目のケースは、通常、最も一般的には転移学習と呼ばれます。 この中で、私たちは、一般的な使用のために定期的にリリースされるいくつかの研究機関や組織によって共有される事前に訓練されたモデルを探す必要があります。 これらのモデルは、重みとともにインターネットでダウンロードでき、同様のデータセットのモデルを構築するために使用できます。
転移学習の実装–VGG16モデル
VGG16と呼ばれる事前にトレーニングされたモデルを利用して、転移学習のアプリケーションを見てみましょう。
VGG16は、2014年にオックスフォード大学の教授によってリリースされた畳み込みニューラルネットワークモデルです。これは、その年にILSVR(ImageNet)コンペティションで優勝した有名なモデルの1つでした。 それは今でも最高のビジョンモデルアーキテクチャの1つとして認められています。 13の畳み込み層、3つの完全に接続された層、およびソフトマックス層を含む16の重み層があります。 約1億3800万のパラメータがあります。 以下に、VGG16モデルのアーキテクチャを示します。
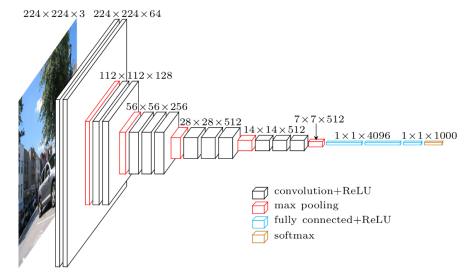
画像ソース: https ://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7

ステップ1:最初のステップは、TensorFlowフレームワークのkerasライブラリによって提供されるVGG16モデルをインポートすることです。
![]()
ステップ2:次のステップでは、モデルを変数「vgg」に割り当て、モデルの引数としてImageNetの重みをダウンロードします。

ステップ3: VGG16、ResNetなどのこれらの事前トレーニング済みモデルは数千の画像でトレーニングされており、いくつかのクラスを分類するために使用されるため、事前トレーニング済みモデルのレイヤーをもう一度トレーニングする必要はありません。 したがって、VGG16モデルのすべてのレイヤーを「False」として設定します。
![]()
ステップ4:すべてのレイヤーをフリーズし、事前トレーニングされたVGG16モデルの最後の分類レイヤーを削除したので、データセットでトレーニングするために、事前トレーニングされたモデルの上に分類レイヤーを追加する必要があります。 したがって、レイヤーをフラット化し、バイナリクラス予測モデルの例を使用して、アクティブ化関数としてsoftmaxを使用した最終的な高密度レイヤーを導入します。

ステップ5:この最後のステップでは、モデルの概要を印刷して、事前にトレーニングされたVGG16モデルのレイヤーと、転送学習を使用してその上に追加した2つのレイヤーを視覚化します。
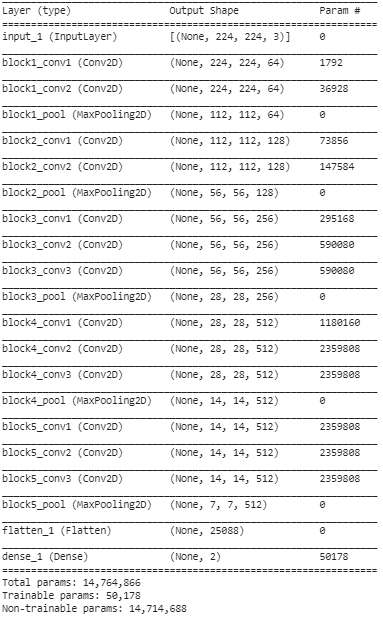
上記の要約から、合計で約1,476万のパラメーターがあり、ステップ3で設定した条件により、最後の2つのレイヤーに属する約50,000のパラメーターのみをトレーニング目的で使用できることがわかります。残りの14.71 Mパラメーターは、トレーニング不可能なパラメーターと呼ばれます。
これらの手順を実行したら、オプティマイザーや損失関数などの外部ハイパーパラメーターを使用してモデルをコンパイルすることにより、通常の畳み込みニューラルネットワークをトレーニングする手順を実行できます。
コンパイル後、設定されたエポック数のフィット関数を使用してトレーニングを開始できます。 このように、転移学習の方法を利用して、ネット上でそのような事前トレーニング済みモデルをいくつか使用してデータセットをトレーニングし、トレーニングデータのクラス数に応じてモデルの上にいくつかのレイヤーを追加できます。
また読む:ディープラーニングアルゴリズム[包括的なガイド]
結論
この記事では、Transfer Learningの基本的な理解、そのアプリケーション、およびkerasライブラリからのサンプルの事前トレーニング済みVGG16モデルを使用した実装について説明しました。 これに加えて、ネットワークの最後の2つの層からのみ事前にトレーニングされた重みを使用すると、収束に最大の影響を与えることがわかっています。
これにより、機能を繰り返し使用するため、収束が速くなります。 Transfer Learningには、今日のモデルの構築に多くのアプリケーションがあります。 最も重要なことは、ヘルスケアアプリケーション向けのAIは、サイズが大きいため、このような事前トレーニング済みのモードがいくつか必要です。 転移学習は初期段階にあるかもしれませんが、今後数年間で、より効率的かつ正確に大規模なデータセットをトレーニングするために最も使用される方法の1つになるでしょう。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
ディープラーニングは機械学習とどう違うのですか?
機械学習と深層学習はどちらも、人工知能と呼ばれる傘下の専門分野です。 機械学習は、人間の関与を最小限に抑えて明確なタスクを学習および実行するように機械またはコンピューターを教える方法を扱う人工知能のサブカテゴリです。 そして、ディープラーニングは機械学習のサブフィールドです。 ディープラーニングは、機械がコンテキストを認識し、人間のように決定するのに役立つ人工ニューラルネットワークの概念に基づいて構築されています。 ディープラーニングは大量の生データを処理するために使用されますが、機械学習は通常、構造化データの形式での入力を期待します。 さらに、深層学習アルゴリズムは人間の干渉をゼロから最小限に抑えて機能できますが、機械学習モデルにはある程度の人間の関与が必要です。
ディープニューラルネットワークを学習するための前提条件はありますか?
人工知能、特に深層学習の分野で大規模なプロジェクトに取り組むには、人工ニューラルネットワークの基本について明確で健全な概念を持っている必要があります。 ニューラルネットワークの基礎を開発するには、まず、主題に関連する多くの本を読み、トレンドのトピックや開発に追いつくために記事やニュースを読む必要があります。 しかし、ニューラルネットワークを学習するための前提条件になると、数学、特に線形代数、微積分、統計、および確率を無視することはできません。 これらとは別に、Python、R、Javaなどのプログラミング言語に関する公正な知識も有益です。
人工知能における転移学習とは何ですか?
以前にトレーニングされた機械学習モデルの要素を新しいモデルで再利用する手法は、人工知能の転移学習として知られています。 両方のモデルが同様の機能を実行するように設計されている場合、転移学習を介してそれらの間で一般化された知識を共有することが可能です。 モデルをトレーニングするこの手法は、利用可能なリソースの効果的な利用を促進し、分類されたデータの浪費を防ぎます。 機械学習が進化し続けるにつれて、人工知能の開発において転移学習はますます重要性を増しています。