
Apprentissage par transfert dans l'apprentissage en profondeur [Guide complet]
Publié: 2020-12-07Table des matières
introduction
Qu'est-ce que l'apprentissage en profondeur ? Il s'agit d'une branche de l'apprentissage automatique qui utilise une simulation du cerveau humain appelée réseaux de neurones. Ces réseaux de neurones sont constitués de neurones similaires à l'unité fondamentale du cerveau humain.
Les neurones constituent un modèle de réseau neuronal et ce domaine d'étude est nommé apprentissage en profondeur. Le résultat final d'un réseau de neurones est appelé un modèle d'apprentissage en profondeur. Généralement, dans l'apprentissage en profondeur, des données non structurées sont utilisées à partir desquelles le modèle d'apprentissage en profondeur extrait des caractéristiques par lui-même par un entraînement répété sur les données.
De tels modèles qui sont conçus pour un ensemble particulier de données lorsqu'ils sont disponibles pour être utilisés comme point de départ pour développer un autre modèle avec un ensemble différent de données et de fonctionnalités, sont connus sous le nom d'apprentissage par transfert. En termes simples, l'apprentissage par transfert est une méthode populaire où un modèle développé pour une tâche particulière est à nouveau utilisé comme point de départ pour développer un modèle pour une autre tâche.
Apprentissage par transfert
L'apprentissage par transfert est utilisé par les humains depuis des temps immémoriaux. Bien que ce domaine de l'apprentissage par transfert soit relativement nouveau pour l'apprentissage automatique, les humains l'ont utilisé de manière inhérente dans presque toutes les situations.
Nous essayons toujours d'appliquer les connaissances acquises de nos expériences passées lorsque nous sommes confrontés à un nouveau problème ou à une nouvelle tâche et c'est la base de l'apprentissage par transfert. Par exemple, si nous savons faire du vélo et qu'on nous demande de conduire une moto, ce que nous n'avons jamais fait auparavant, notre expérience de la conduite d'un vélo sera toujours appliquée lors de la conduite de la moto, comme diriger la poignée et équilibrer le vélo. Ce concept simple constitue la base de l'apprentissage par transfert.
Pour comprendre la notion de base de l'apprentissage par transfert, considérons qu'un modèle X est formé avec succès pour effectuer la tâche A avec le modèle M1. Si la taille de l'ensemble de données pour la tâche B est trop petite, empêchant le modèle Y de s'entraîner efficacement ou provoquant un surajustement des données, nous pouvons utiliser une partie du modèle M1 comme base pour construire le modèle Y pour effectuer la tâche B.

Pourquoi l'apprentissage par transfert ?
Selon Andrew Ng, l'un des pionniers du monde d'aujourd'hui dans la promotion de l'intelligence artificielle, "l'apprentissage par transfert sera le prochain moteur du succès du ML". Il l'a mentionné dans une conférence donnée à la Conférence sur les systèmes de traitement de l'information neuronale (NIPS 2016). Il ne fait aucun doute que le succès du ML dans l'industrie d'aujourd'hui est principalement dû à l'apprentissage supervisé. D'autre part, à l'avenir, avec une plus grande quantité de données non supervisées et non étiquetées, l'apprentissage par transfert sera une technique qui sera largement utilisée dans l'industrie.
De nos jours, les gens préfèrent utiliser un modèle pré-formé qui est déjà formé sur une variété d'images telles que ImageNet plutôt que de créer un modèle complet de réseau neuronal convolutif à partir de zéro. L'apprentissage par transfert présente plusieurs avantages, mais les principaux avantages sont le gain de temps de formation, une meilleure performance des réseaux de neurones et le fait de ne pas avoir besoin de beaucoup de données.
Lire : Les meilleures techniques d'apprentissage en profondeur
Méthodes d'apprentissage par transfert
Généralement, il existe deux façons d'appliquer l'apprentissage par transfert - l'une consiste à développer un modèle à partir de zéro et l'autre consiste à utiliser un modèle pré-formé.
Dans le premier cas, nous construisons généralement une architecture de modèle en fonction des données d'apprentissage et la capacité du modèle à extraire des poids et des modèles du modèle est étudiée avec soin avec plusieurs paramètres statistiques. Après quelques cycles d'entraînement, en fonction du résultat, il peut être nécessaire d'apporter certaines modifications au modèle pour obtenir des performances optimales. De cette façon, nous pouvons enregistrer le modèle et l'utiliser comme point de départ pour créer un autre modèle pour une tâche similaire.
Le deuxième cas d'utilisation de modèles pré-formés est généralement le plus souvent appelé apprentissage par transfert. En cela, nous devons rechercher des modèles pré-formés partagés par plusieurs institutions et organisations de recherche publiés périodiquement pour un usage général. Ces modèles sont disponibles en téléchargement sur Internet avec leurs poids et peuvent être utilisés pour construire des modèles pour des ensembles de données similaires.
Mise en œuvre de l'apprentissage par transfert - Modèle VGG16
Passons en revue une application de Transfer Learning en utilisant un modèle pré-formé appelé VGG16.
Le VGG16 est un modèle de réseau neuronal convolutif qui a été publié par les professeurs de l'Université d'Oxford en 2014. C'était l'un des modèles célèbres qui a remporté le concours ILSVR (ImageNet) cette année-là. Il est toujours reconnu comme l'une des meilleures architectures de modèles de vision. Il comporte 16 couches de poids, dont 13 couches convolutionnelles, 3 couches entièrement connectées et une couche soft max. Il contient environ 138 millions de paramètres. Vous trouverez ci-dessous l'architecture du modèle VGG16.
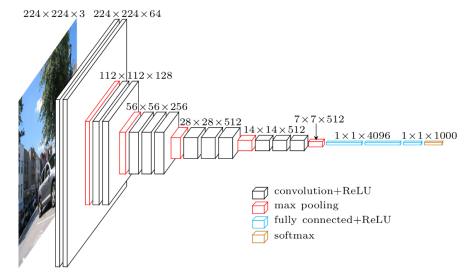
Source de l'image : https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Étape 1 : La première étape consiste à importer le modèle VGG16 fourni par la bibliothèque keras dans le framework TensorFlow.

![]()
Etape 2 : Dans l'étape suivante, nous allons affecter le modèle à une variable "vgg" et télécharger les poids de l'ImageNet en le donnant comme argument au modèle

Étape 3 : Comme ces modèles pré-entraînés tels que VGG16, ResNet ont été entraînés sur plusieurs milliers d'images et sont utilisés pour classer plusieurs classes, nous n'avons pas besoin d'entraîner à nouveau les couches du modèle pré-entraîné. Par conséquent, nous définissons toutes les couches du modèle VGG16 sur "False".
![]()
Étape 4 : Comme nous avons gelé toutes les couches et supprimé les dernières couches de classification du modèle VGG16 pré-formé, nous devons ajouter une couche de classification au-dessus du modèle pré-formé pour l'entraîner sur un jeu de données. Par conséquent, nous aplatissons les couches et introduisons une couche Dense finale avec softmax comme fonction d'activation avec un exemple de modèle de prédiction de classe binaire.

Étape 5 : Dans cette dernière étape, nous imprimons le résumé de notre modèle pour visualiser les couches du modèle VGG16 pré-formé et les deux couches que nous avons ajoutées en utilisant Transfer Learning.
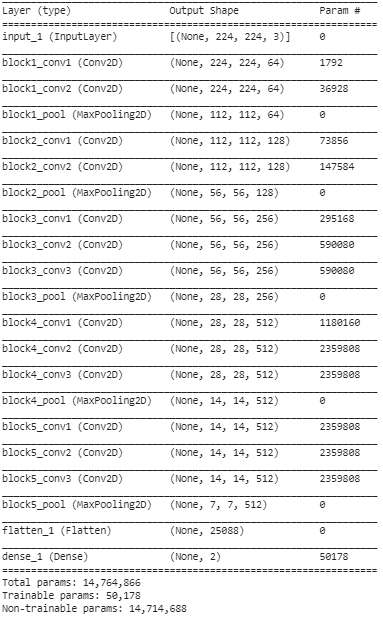
D'après le résumé ci-dessus, nous pouvons voir qu'il existe près de 14,76 millions de paramètres au total, dont seulement 50 000 paramètres environ appartenant aux deux dernières couches sont autorisés à être utilisés à des fins de formation en raison de la condition définie ci-dessus à l'étape 3. Les 14,71 restants Les paramètres M sont appelés paramètres non entraînables.
Une fois ces étapes effectuées, nous pouvons effectuer des étapes pour former le réseau de neurones convolutionnel régulier en compilant notre modèle avec des hyperparamètres externes tels que l'optimiseur et la fonction de perte.
Après la compilation, nous pouvons commencer la formation en utilisant la fonction d'ajustement pour un nombre défini d'époques. De cette façon, nous pouvons utiliser la méthode d'apprentissage par transfert pour former n'importe quel ensemble de données avec plusieurs de ces modèles pré-formés sur le net et ajouter quelques couches au-dessus du modèle en fonction du nombre de classes de nos données de formation.
Lisez également : Algorithme d'apprentissage en profondeur [Guide complet]
Conclusion
Dans cet article, nous avons passé en revue la compréhension de base de l'apprentissage par transfert, son application, ainsi que sa mise en œuvre avec un exemple de modèle VGG16 pré-formé de la bibliothèque keras. En plus de cela, il a été découvert que l'utilisation des poids pré-formés uniquement à partir des deux dernières couches du réseau a le plus grand effet sur la convergence.
Cela se traduit également par une convergence plus rapide en raison de l'utilisation répétée des fonctionnalités. L'apprentissage par transfert a de nombreuses applications dans la construction de modèles aujourd'hui. Plus important encore, l'IA pour les applications de soins de santé nécessite plusieurs modes pré-formés en raison de sa grande taille. Bien que l'apprentissage par transfert en soit à ses débuts, il sera dans les années à venir l'une des méthodes les plus utilisées pour former de grands ensembles de données avec plus d'efficacité et de précision.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
En quoi le deep learning est-il différent du machine learning ?
L'apprentissage automatique et l'apprentissage en profondeur sont des domaines spécialisés sous l'égide de l'intelligence artificielle. L'apprentissage automatique est une sous-catégorie de l'intelligence artificielle qui traite de la manière dont les machines ou les ordinateurs peuvent apprendre à apprendre et à effectuer des tâches définies avec une implication humaine minimale. Et l'apprentissage en profondeur est un sous-domaine de l'apprentissage automatique. L'apprentissage en profondeur repose sur les concepts de réseaux de neurones artificiels qui aident les machines à apprécier les contextes et à décider comme les humains. Alors que l'apprentissage en profondeur est utilisé pour traiter des volumes massifs de données brutes, l'apprentissage automatique attend généralement des entrées sous la forme de données structurées. De plus, alors que les algorithmes d'apprentissage en profondeur peuvent fonctionner avec une interférence humaine nulle ou minimale, les modèles d'apprentissage automatique nécessiteront toujours un certain niveau d'implication humaine.
Y a-t-il des prérequis pour apprendre les réseaux de neurones profonds ?
Travailler sur un projet à grande échelle dans le domaine de l'intelligence artificielle, en particulier de l'apprentissage en profondeur, nécessitera que vous ayez une conception claire et solide des bases des réseaux de neurones artificiels. Pour développer vos bases sur les réseaux de neurones, vous devez d'abord lire de nombreux livres sur le sujet et parcourir des articles et des actualités pour suivre les tendances et les développements. Mais en ce qui concerne les conditions préalables à l'apprentissage des réseaux de neurones, vous ne pouvez pas ignorer les mathématiques, en particulier l'algèbre linéaire, le calcul, les statistiques et les probabilités. En dehors de ceux-ci, une bonne connaissance des langages de programmation tels que Python, R et Java sera également bénéfique.
Qu'est-ce que l'apprentissage par transfert en intelligence artificielle ?
La technique consistant à réutiliser des éléments d'un modèle d'apprentissage automatique précédemment formé dans un nouveau modèle est connue sous le nom d'apprentissage par transfert en intelligence artificielle. Si les deux modèles sont conçus pour remplir des fonctions similaires, il est possible de partager des connaissances généralisées entre eux via l'apprentissage par transfert. Cette technique de modèles de formation favorise l'utilisation efficace des ressources disponibles et évite le gaspillage de données classifiées. Alors que l'apprentissage automatique continue d'évoluer, l'apprentissage par transfert ne cesse de gagner en importance dans le développement de l'intelligence artificielle.