
Lerntransfer im Deep Learning [Umfassender Leitfaden]
Veröffentlicht: 2020-12-07Inhaltsverzeichnis
Einführung
Was ist Deep Learning? Es ist ein Zweig des maschinellen Lernens, der eine Simulation des menschlichen Gehirns verwendet, die als neuronale Netze bekannt ist. Diese neuronalen Netze bestehen aus Neuronen, die der Grundeinheit des menschlichen Gehirns ähneln.
Die Neuronen bilden ein neuronales Netzwerkmodell, und dieses Studiengebiet insgesamt wird als Deep Learning bezeichnet. Das Endergebnis eines neuronalen Netzes wird als Deep-Learning-Modell bezeichnet. Meist werden beim Deep Learning unstrukturierte Daten verwendet, aus denen das Deep-Learning-Modell durch wiederholtes Training auf den Daten eigenständig Merkmale extrahiert.
Solche Modelle, die für einen bestimmten Datensatz entwickelt wurden, wenn sie als Ausgangspunkt für die Entwicklung eines anderen Modells mit einem anderen Datensatz und anderen Merkmalen verwendet werden können, werden als Transfer Learning bezeichnet. Einfach ausgedrückt ist Transfer Learning eine beliebte Methode, bei der ein für eine bestimmte Aufgabe entwickeltes Modell wieder als Ausgangspunkt für die Entwicklung eines Modells für eine andere Aufgabe verwendet wird.
Lernen übertragen
Transfer Learning wird seit jeher von Menschen genutzt. Obwohl dieses Gebiet des Transferlernens für das maschinelle Lernen relativ neu ist, haben Menschen es von Natur aus in fast jeder Situation genutzt.
Wir versuchen immer, das aus unseren vergangenen Erfahrungen gewonnene Wissen anzuwenden, wenn wir uns einem neuen Problem oder einer neuen Aufgabe stellen, und dies ist die Grundlage des Transferlernens. Wenn wir zum Beispiel wissen, wie man Fahrrad fährt, und wenn wir aufgefordert werden, ein Motorrad zu fahren, was wir noch nie gemacht haben, werden unsere Erfahrungen mit dem Fahrradfahren immer beim Motorradfahren angewendet, z. B. beim Lenken des Lenkers und beim Ausbalancieren des Fahrrads. Dieses einfache Konzept bildet die Grundlage des Transfer Learning.
Um den grundlegenden Begriff des Transferlernens zu verstehen, stellen Sie sich vor, dass ein Modell X erfolgreich trainiert wurde, um Aufgabe A mit Modell M1 auszuführen. Wenn die Größe des Datensatzes für Aufgabe B zu klein ist und das Modell Y daran hindert, effizient zu trainieren oder eine Überanpassung der Daten verursacht, können wir einen Teil des Modells M1 als Basis verwenden, um Modell Y zu erstellen, um Aufgabe B auszuführen.

Warum Transferlernen?
Laut Andrew Ng, einem der Pioniere der heutigen Welt bei der Förderung der künstlichen Intelligenz, wird „Transfer Learning der nächste Treiber für den Erfolg von ML sein“. Er erwähnte es in einem Vortrag auf der Conference on Neural Information Processing Systems (NIPS 2016). Es besteht kein Zweifel, dass der Erfolg von ML in der heutigen Industrie hauptsächlich auf überwachtes Lernen zurückzuführen ist. Auf der anderen Seite wird Transfer Learning in Zukunft mit einer größeren Menge an unbeaufsichtigten und unbeschrifteten Daten eine Technik sein, die in der Branche stark genutzt wird.
Heutzutage ziehen es die Menschen vor, ein vortrainiertes Modell zu verwenden, das bereits mit einer Vielzahl von Bildern wie ImageNet trainiert wurde, als ein ganzes Convolutional Neural Network-Modell von Grund auf neu zu erstellen. Transfer Learning hat mehrere Vorteile, aber die Hauptvorteile sind die Einsparung von Trainingszeit, eine bessere Leistung neuronaler Netze und der geringere Bedarf an Daten.
Lesen Sie: Die besten Deep-Learning-Techniken
Methoden des Transferlernens
Im Allgemeinen gibt es zwei Möglichkeiten, Transfer Learning anzuwenden – Zum einen wird ein Modell von Grund auf neu entwickelt, zum anderen wird ein vortrainiertes Modell verwendet.
Im ersten Fall erstellen wir normalerweise eine Modellarchitektur in Abhängigkeit von den Trainingsdaten, und die Fähigkeit des Modells, Gewichtungen und Muster aus dem Modell zu extrahieren, wird sorgfältig mit mehreren statistischen Parametern untersucht. Nach einigen Trainingsrunden müssen je nach Ergebnis möglicherweise einige Änderungen am Modell vorgenommen werden, um eine optimale Leistung zu erzielen. Auf diese Weise können wir das Modell speichern und es als Ausgangspunkt für die Erstellung eines anderen Modells für eine ähnliche Aufgabe verwenden.
Der zweite Fall der Verwendung vortrainierter Modelle wird normalerweise am häufigsten als Transfer Learning bezeichnet. Dabei müssen wir nach vortrainierten Modellen suchen, die von mehreren Forschungseinrichtungen und Organisationen gemeinsam genutzt werden und regelmäßig zur allgemeinen Verwendung freigegeben werden. Diese Modelle stehen zusammen mit ihren Gewichten im Internet zum Download bereit und können zum Erstellen von Modellen für ähnliche Datensätze verwendet werden.
Umsetzung des Transferlernens – VGG16-Modell
Lassen Sie uns eine Anwendung des Transfer Learning durchgehen, indem wir ein vortrainiertes Modell namens VGG16 verwenden.
Das VGG16 ist ein Convolutional Neural Network-Modell, das im Jahr 2014 von den Professoren der University of Oxford veröffentlicht wurde. Es war eines der berühmten Modelle, das in diesem Jahr den ILSVR (ImageNet)-Wettbewerb gewann. Es wird immer noch als eine der besten Vision-Modellarchitekturen anerkannt. Es hat 16 Gewichtsschichten, darunter 13 Faltungsschichten, 3 vollständig verbundene Schichten und eine weiche Max-Schicht. Es hat ungefähr 138 Millionen Parameter. Unten ist die Architektur des VGG16-Modells angegeben.
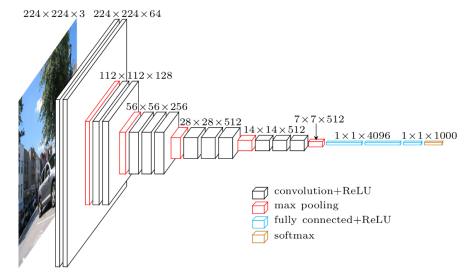
Bildquelle: https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Schritt 1: Der erste Schritt besteht darin, das VGG16-Modell zu importieren, das von der Keras-Bibliothek im TensorFlow-Framework bereitgestellt wird.

![]()
Schritt 2: Im nächsten Schritt weisen wir das Modell einer Variablen „vgg“ zu und laden die Gewichte des ImageNet herunter, indem wir sie als Argument an das Modell übergeben

Schritt 3: Da diese vortrainierten Modelle wie VGG16, ResNet mit mehreren tausend Bildern trainiert wurden und zur Klassifizierung mehrerer Klassen verwendet werden, müssen wir die Schichten des vortrainierten Modells nicht erneut trainieren. Daher setzen wir alle Layer des VGG16-Modells auf „False“.
![]()
Schritt 4: Da wir alle Schichten eingefroren und die letzten Klassifizierungsschichten des vortrainierten VGG16-Modells entfernt haben, müssen wir eine Klassifizierungsschicht über dem vortrainierten Modell hinzufügen, um es mit einem Datensatz zu trainieren. Daher glätten wir die Schichten und führen eine abschließende dichte Schicht mit Softmax als Aktivierungsfunktion mit einem Beispiel eines binären Klassenvorhersagemodells ein.

Schritt 5: In diesem letzten Schritt drucken wir die Zusammenfassung unseres Modells aus, um die Schichten des vortrainierten VGG16-Modells und die beiden Schichten, die wir mithilfe von Transfer Learning darüber hinzugefügt haben, zu visualisieren.
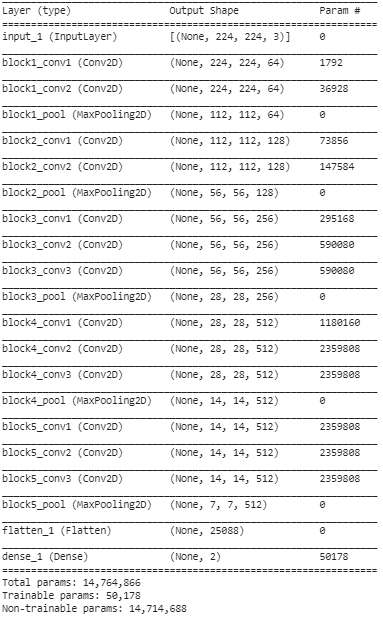
Aus der obigen Zusammenfassung können wir ersehen, dass es fast 14,76 Mio. Gesamtparameter gibt, von denen nur etwa 50.000 Parameter, die zu den letzten beiden Schichten gehören, aufgrund der oben in Schritt 3 festgelegten Bedingung für Trainingszwecke verwendet werden dürfen. Die restlichen 14,71 M-Parameter werden als nicht trainierbare Parameter bezeichnet.
Sobald diese Schritte ausgeführt sind, können wir Schritte ausführen, um das reguläre Convolutional Neural Network zu trainieren, indem wir unser Modell mit externen Hyperparametern wie Optimierer und Verlustfunktion kompilieren.
Nach dem Kompilieren können wir mit dem Training beginnen, indem wir die Fit-Funktion für eine festgelegte Anzahl von Epochen verwenden. Auf diese Weise können wir die Methode des Transferlernens verwenden, um jeden Datensatz mit mehreren solcher vortrainierten Modelle im Netz zu trainieren und je nach Anzahl der Klassen unserer Trainingsdaten ein paar Schichten über dem Modell hinzuzufügen.
Lesen Sie auch: Deep-Learning-Algorithmus [Umfassender Leitfaden]
Fazit
In diesem Artikel haben wir das grundlegende Verständnis von Transfer Learning, seine Anwendung und auch seine Implementierung anhand eines Beispiels für ein vortrainiertes VGG16-Modell aus der Keras-Bibliothek durchgegangen. Darüber hinaus wurde herausgefunden, dass die Verwendung der vortrainierten Gewichtungen nur aus den letzten beiden Schichten des Netzwerks die größte Auswirkung auf die Konvergenz hat.
Dies führt auch zu einer schnelleren Konvergenz aufgrund der wiederholten Verwendung von Funktionen. Transfer Learning hat heute viele Anwendungen beim Erstellen von Modellen. Am wichtigsten ist, dass KI für Anwendungen im Gesundheitswesen aufgrund ihrer Größe mehrere solcher vortrainierter Modi benötigt. Obwohl Transfer Learning noch in den Anfängen steckt, wird es in den kommenden Jahren eine der am häufigsten verwendeten Methoden sein, um große Datensätze effizienter und genauer zu trainieren.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Wie unterscheidet sich Deep Learning von maschinellem Lernen?
Sowohl maschinelles Lernen als auch Deep Learning sind Spezialgebiete unter dem Dach der künstlichen Intelligenz. Maschinelles Lernen ist eine Unterkategorie der künstlichen Intelligenz, die sich damit befasst, wie Maschinen oder Computern beigebracht werden können, zu lernen und bestimmte Aufgaben mit minimaler menschlicher Beteiligung auszuführen. Und Deep Learning ist ein Teilbereich des maschinellen Lernens. Deep Learning basiert auf den Konzepten künstlicher neuronaler Netze, die Maschinen helfen, Zusammenhänge zu erkennen und wie Menschen zu entscheiden. Während Deep Learning verwendet wird, um riesige Mengen an Rohdaten zu verarbeiten, erwartet maschinelles Lernen normalerweise Eingaben in Form von strukturierten Daten. Darüber hinaus können Deep-Learning-Algorithmen zwar ohne bis zu einem Minimum an menschlichen Eingriffen funktionieren, Modelle für maschinelles Lernen erfordern jedoch immer noch ein gewisses Maß an menschlicher Beteiligung.
Gibt es Voraussetzungen für das Erlernen tiefer neuronaler Netze?
Die Arbeit an einem Großprojekt im Bereich Künstliche Intelligenz, insbesondere Deep Learning, erfordert ein klares und fundiertes Verständnis der Grundlagen künstlicher neuronaler Netze. Um Ihre Grundlagen neuronaler Netze zu entwickeln, müssen Sie zunächst viele Bücher zu diesem Thema lesen und auch Artikel und Nachrichten lesen, um mit den Trendthemen und Entwicklungen Schritt zu halten. Aber um zu den Voraussetzungen für das Erlernen neuronaler Netze zu kommen, können Sie die Mathematik nicht ignorieren, insbesondere lineare Algebra, Analysis, Statistik und Wahrscheinlichkeit. Außerdem sind gute Kenntnisse in Programmiersprachen wie Python, R und Java von Vorteil.
Was ist Transferlernen in der künstlichen Intelligenz?
Die Technik, Elemente aus einem zuvor trainierten maschinellen Lernmodell in einem neuen Modell wiederzuverwenden, wird in der künstlichen Intelligenz als Transferlernen bezeichnet. Wenn beide Modelle ähnliche Funktionen ausführen sollen, ist es möglich, allgemeines Wissen zwischen ihnen durch Transfer Learning zu teilen. Diese Technik des Trainierens von Modellen fördert die effektive Nutzung verfügbarer Ressourcen und verhindert die Verschwendung klassifizierter Daten. Mit der Weiterentwicklung des maschinellen Lernens gewinnt das Transfer Learning immer mehr an Bedeutung in der Entwicklung der künstlichen Intelligenz.