
データセットの拡張:人工データの作成[簡単に説明]
公開: 2020-12-07目次
序章
機械学習アルゴリズムを設計するときは、最適化と一般化の間のトレードオフを常に維持する必要があります。 これらの単語は初心者には複雑すぎるように思われるかもしれませんが、機械学習をマスターするための旅の早い段階でそれらの違いを知ることは、モデルが特定の方法で動作する理由の根本的な働きを理解するのに間違いなく役立ちます。
最適化の側面とは、トレーニングデータのパフォーマンスがピークになるようにモデルを調整することです。 一方、一般化は、これまでに見たことのないデータ、つまり検証セットでの学習モデルのパフォーマンスに関係します。
トレーニングデータの特定のエポックの後、モデルの一般化が改善を停止し、検証メトリックが低下し始めるときがよくあります。これは、モデルが過剰適合していると言われる場合、つまり、特定の情報の学習を開始する場合です。トレーニングデータですが、新しいデータとの相関には役立ちません。
最適なソリューションの過剰適合の問題に対処するには、より多くのトレーニングデータを収集する必要があります。モデルが確認したデータが多いほど、新しいデータの表現を学習する確率も高くなります。 ただし、より多くのトレーニングデータを収集することは、取り組む必要のあるマスターの問題を解決するよりもコストがかかる可能性があります。 この制限を回避するために、偽のデータを作成してトレーニングセットに追加することができます。 これは、データ拡張として知られています。
深さのデータ拡張
画像から視覚表現を学ぶという前提は、多くのコンピュータビジョンの問題を解決するのに役立ちました。 ただし、トレーニングするデータセットが小さい場合、これらの視覚的表現は誤解を招く可能性があります。 データ拡張は、この欠点を克服するための優れた戦略です。
拡張中に、トレーニングセット内の画像は、回転、スケーリング、せん断などの特定の操作によって変換されます。たとえば、トレーニングセットが立った状態の人間の画像のみで構成されている場合、作成しようとしている分類子横になっている人間の画像を予測できない可能性があるため、拡張では、トレーニングセットの画像を90度回転させることで、横になっている人間の画像をシミュレートできます。

これは、データセットを拡張し、モデルの検証メトリックを増やすための安価で重要な方法です。
データ拡張は、特にオブジェクト認識などの分類問題に対して強力なツールです。 トレーニング画像を各方向に数ピクセル変換するなどの操作により、一般化が大幅に改善されることがよくあります。
拡張のもう1つの有利な機能は、画像がフロー上で変換されることです。これは、既存のデータセットが上書きされないことを意味します。 トレーニングのために画像がニューラルネットワークにロードされているときに拡張が行われるため、これによってメモリ要件が増加することはなく、さらに実験するためにデータも保存されます。
トレーニングクラスの既存の分布を変更する可能性のある変換を適用しないように注意する必要がありますが、拡張などの翻訳手法を適用することは、新しいデータの収集に費用がかかる場合に非常に役立ちます。 たとえば、トレーニングセットに0から9までの手書き数字の画像が含まれている場合、数字「6」と「9」を反転/回転することは、トレーニングセットを廃止するため、適切な変換ではありません。
また読む:トップの機械学習データセットプロジェクトのアイデア
TensorFlowでのデータ拡張の使用
拡張は、TensorFlowをバックエンドとして使用するKerasのImageDataGeneratorAPIを使用して実現できます。 ImageDataGeneratorインスタンスは、トレーニングポイントで画像に対していくつかのランダムな変換を実行できます。 このインスタンスで利用可能な一般的な引数のいくつかは次のとおりです。
- rotation_range:画像をランダムに回転させるための0〜180度の整数値。
- width_shift_range:より多くの例を生成するために、画像をフレームの周りで水平方向にシフトします。
- height_shift_range:より多くの例を生成するために、画像をフレームの周りで垂直にシフトします。
- Shear_range:画像にランダムなせん断変換を適用して、複数の例を生成します。
- Zoom_range:ランダムにズームする画像の相対部分。
- horizontal_flip :画像を水平方向に反転するために使用されます。
- fill_mode:新しく作成されたピクセルを塗りつぶすためのメソッド。
以下は、 ImageDataGeneratorインスタンスを使用して前述の変換を実行する方法を示すコードスニペットです。

- train_datagen = ImageDataGenerator(
- rescale = 1. / 255、
- rotation_range = 40、
- width_shift_range = 0.2、
- height_shift_range = 0.2、
- せん断範囲=0.2、
- Zoom_range = 0.2、
- horizontal_flip = True、
- fill_mode ='最も近い')
これらのランダムな変換をトレーニングセットに適用した結果を確認することも簡単です。 このために、トレーニングセットを反復処理することにより、ランダムに拡張されたトレーニング画像を表示できます。

図1:拡張を使用して生成された画像
(Francois CholletによるPythonを使用したディープラーニングの画像、第5章、140ページ)
図1は、トレーニング時に実行されたランダムな変換によってのみ、すべての画像が表面的に異なる単一の入力画像から、拡張によって複数の画像を生成する方法を示しています。
拡張戦略を使用することの真の本質を理解するには、モデルのトレーニングと検証のメトリックへの影響を理解する必要があります。 このために、2つのモデルをトレーニングします。1つはデータ拡張を使用せず、もう1つは使用します。 これを検証するために、次の場所で入手できるCatsandDogsデータセットを使用します。
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
両方のモデルで観察された精度曲線を以下にプロットします。
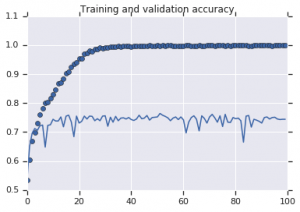
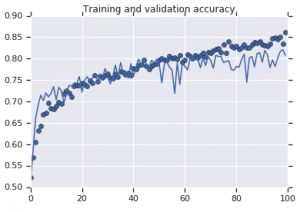
図2:トレーニングと検証の精度。 左:拡張なしのモデル。 右:ランダムなデータ拡張変換を使用したモデル。
必読:感情分析のためのトップの安定化されたデータセット
結論
図2から、拡張戦略なしでトレーニングされたモデルは低い一般化力を示していることが明らかです。 検証セットでのモデルのパフォーマンスは、トレーニングセットでのパフォーマンスと同等ではありません。 これは、モデルが過剰適合していることを意味します。
一方、拡張戦略を使用する2番目のモデルは、検証精度がトレーニング精度と同じくらい高くなる優れたメトリックを示します。 これは、モデルが過剰適合の兆候を示すデータセット拡張手法を採用することがいかに有用であるかを示しています。
感情分析や、人工知能や機械学習などの関連テクノロジーについてさらに詳しく知りたい場合は、機械学習とAIコースのPGディプロマを確認してください。