
Dataset Augmentation: Künstliche Daten erzeugen [Einfach erklärt]
Veröffentlicht: 2020-12-07Inhaltsverzeichnis
Einführung
Beim Entwerfen eines maschinellen Lernalgorithmus muss man immer den Kompromiss zwischen Optimierung und Generalisierung einhalten . Diese Wörter mögen für Anfänger zu kompliziert erscheinen, aber wenn sie den Unterschied zwischen ihnen in einem frühen Stadium auf ihrem Weg zum Meister des maschinellen Lernens kennen, wird ihnen dies definitiv helfen, die zugrunde liegende Funktionsweise zu verstehen, warum sich ihr Modell auf eine bestimmte Weise verhält.
Der Aspekt der Optimierung bezieht sich darauf, das Modell so abzustimmen, dass seine Leistung bei den Trainingsdaten ihren Höhepunkt erreicht. Andererseits bezieht sich Generalisierung auf die Leistung eines Lernmodells auf Daten, die es noch nie zuvor gesehen hat, dh auf einem Validierungssatz.
Es kommt oft eine Zeit, in der sich nach einer bestimmten Anzahl von Epochen der Trainingsdaten die Generalisierung des Modells nicht mehr verbessert und die Validierungsmetriken beginnen, sich zu verschlechtern. Dies ist der Fall, in dem das Modell als überangepasst bezeichnet wird, dh an dem es beginnt, spezifische Informationen zu lernen die Trainingsdaten, aber nicht nützlich für die Korrelation mit neuen Daten.
Um das Problem der Überanpassung anzugehen, besteht die beste Lösung darin, mehr Trainingsdaten zu sammeln: Je mehr Daten das Modell gesehen hat, desto größer ist seine Wahrscheinlichkeit, auch Repräsentationen der neuen Daten zu lernen. Das Sammeln von mehr Trainingsdaten kann jedoch teurer sein als das Lösen des Hauptproblems, das man angehen muss. Um diese Einschränkung zu umgehen, können wir gefälschte Daten erstellen und sie dem Trainingssatz hinzufügen. Dies wird als Datenaugmentation bezeichnet.
Datenerweiterung in der Tiefe
Die Prämisse, visuelle Darstellungen aus Bildern zu lernen, hat dazu beigetragen, viele Computer-Vision-Probleme zu lösen. Wenn wir jedoch einen kleineren Datensatz zum Trainieren haben, können diese visuellen Darstellungen irreführend sein. Die Datenerweiterung ist eine hervorragende Strategie, um diesen Nachteil zu überwinden.
Während der Erweiterung werden die Bilder im Trainingssatz durch bestimmte Operationen wie Rotation, Skalierung, Scherung usw. transformiert. Zum Beispiel: Wenn der Trainingssatz nur aus Bildern von Menschen in stehender Position besteht, dann der Klassifikator, den wir zu erstellen versuchen kann die Bilder von liegenden Menschen möglicherweise nicht vorhersagen, sodass die Augmentation das Bild von liegenden Menschen simulieren kann, indem die Bilder des Trainingssatzes um 90 Grad gedreht werden.

Dies ist eine kostengünstige und signifikante Möglichkeit, den Datensatz zu erweitern und die Validierungsmetriken des Modells zu erhöhen.
Datenaugmentation ist ein mächtiges Werkzeug insbesondere für Klassifikationsprobleme wie Objekterkennung. Operationen wie das Übersetzen der Trainingsbilder um einige Pixel in jede Richtung können die Verallgemeinerung oft erheblich verbessern.
Ein weiteres vorteilhaftes Merkmal der Augmentation besteht darin, dass Bilder im Fluss transformiert werden, was bedeutet, dass der vorhandene Datensatz nicht überschrieben wird. Die Erweiterung findet statt, wenn die Bilder zum Training in das neuronale Netzwerk geladen werden, und daher wird dies die Speicheranforderungen nicht erhöhen und die Daten auch für weitere Experimente aufbewahren.
Die Anwendung von Übersetzungstechniken wie Augmentation ist sehr nützlich, wenn das Sammeln neuer Daten teuer ist, obwohl man bedenken muss, keine Transformation anzuwenden, die die bestehende Verteilung der Trainingsklasse ändern könnte. Wenn der Trainingssatz beispielsweise Bilder von handgeschriebenen Ziffern von 0 bis 9 enthält, dann ist das Spiegeln/Drehen der Ziffern „6“ und „9“ keine geeignete Transformation, da dies den Trainingssatz obsolet macht.
Lesen Sie auch: Top-Projektideen für maschinelle Lerndatensätze
Verwenden von Datenerweiterung mit TensorFlow
Die Erweiterung kann durch die Verwendung der ImageDataGenerator- API von Keras mit TensorFlow als Backend erreicht werden. Die ImageDataGenerator- Instanz kann am Trainingspunkt eine Reihe zufälliger Transformationen an den Bildern durchführen. Einige der populären Argumente, die in diesem Fall zur Verfügung stehen, sind:

- rotation_range: Ein ganzzahliger Wert in Grad zwischen 0-180, um Bilder zufällig zu drehen.
- width_shift_range: Horizontales Verschieben des Bildes um seinen Rahmen herum, um weitere Beispiele zu generieren.
- height_shift_range: Vertikales Verschieben des Bildes um seinen Rahmen herum, um weitere Beispiele zu generieren.
- sheer_range: Wende zufällige Schertransformationen auf das Bild an, um mehrere Beispiele zu generieren.
- zoom_range: Relativer Teil des Bildes, der zufällig gezoomt werden soll.
- horizontal_flip: Wird verwendet, um die Bilder horizontal zu spiegeln.
- fill_mode: Methode zum Füllen neu erzeugter Pixel.
Unten ist das Code-Snippet, das zeigt, wie die ImageDataGenerator- Instanz verwendet werden kann, um die oben erwähnte Transformation durchzuführen:
- train_datagen = Bilddatengenerator (
- Neuskalierung=1./255,
- rotation_range=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- Scherbereich = 0,2,
- zoom_range=0.2,
- horizontal_flip=Wahr,
- fill_mode='am nächsten')
Es ist auch trivial, das Ergebnis der Anwendung dieser zufälligen Transformationen auf den Trainingssatz zu sehen. Dazu können wir einige zufällig erweiterte Trainingsbilder anzeigen, indem wir über den Trainingssatz iterieren:

Abbildung 1: Mittels Augmentation generierte Bilder
(Bild aus Deep Learning with Python von Francois Chollet, Kapitel 5, Seite 140)
Abbildung 1 gibt uns eine Vorstellung davon, wie die Augmentation mehrere Bilder aus einem einzigen Eingabebild erzeugen kann, wobei sich alle Bilder nur oberflächlich voneinander unterscheiden, weil sie zur Trainingszeit zufällig transformiert wurden.
Um die wahre Essenz der Verwendung von Augmentationsstrategien zu verstehen, müssen wir ihre Auswirkungen auf die Trainings- und Validierungsmetriken des Modells verstehen. Dazu werden wir zwei Modelle trainieren: Das eine wird keine Datenaugmentation verwenden, das andere wird es tun. Um dies zu validieren, verwenden wir den Cats and Dogs -Datensatz, der verfügbar ist unter:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Die Genauigkeitskurven, die für beide Modelle beobachtet wurden, sind unten dargestellt:
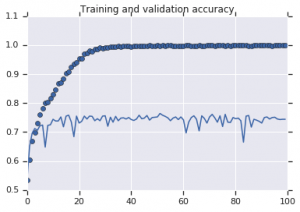
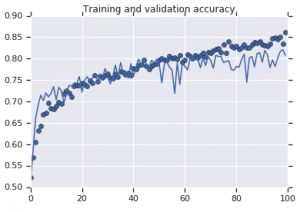
Abbildung 2: Trainings- und Validierungsgenauigkeit. Links : Modell ohne Augmentation. Rechts : Modell mit zufälligen Datenerweiterungstransformationen.
Muss gelesen werden: Top etablierte Datensätze für die Stimmungsanalyse
Fazit
Aus Abbildung 2 ist ersichtlich, dass das ohne Augmentationsstrategien trainierte Modell eine geringe Verallgemeinerungskraft aufweist. Die Leistung des Modells im Validierungssatz entspricht nicht der im Trainingssatz. Dies bedeutet, dass das Modell überangepasst ist.
Andererseits zeigt das zweite Modell, das Augmentationsstrategien verwendet, hervorragende Metriken, wobei die Validierungsgenauigkeit so hoch steigt wie die Trainingsgenauigkeit. Dies zeigt, wie nützlich es ist, Techniken zur Datensatzerweiterung einzusetzen, wenn ein Modell Anzeichen einer Überanpassung aufweist.
Wenn Sie weiter an Sentimentanalysen und den damit verbundenen Technologien wie künstlicher Intelligenz und maschinellem Lernen interessiert sind, können Sie unseren Kurs PG Diploma in Machine Learning and AI besuchen.