
數據集增強:創建人工數據[簡單解釋]
已發表: 2020-12-07目錄
介紹
在設計任何機器學習算法時,總是需要在優化和泛化之間進行權衡。 這些詞對於新手來說可能看起來太複雜了,但在他們掌握機器學習的早期階段就知道它們之間的區別肯定會幫助他們理解為什麼他們的模型以特定方式表現的潛在工作原理。
優化方面是指調整模型,使其在訓練數據上的性能達到峰值。 另一方面,泛化與學習模型在從未見過的數據(即驗證集)上的表現有關。
經常有一段時間,在訓練數據經過一定數量的 epoch 後,模型的泛化能力停止改進,驗證指標開始下降,這就是模型被稱為過度擬合的情況,即它開始學習特定於訓練數據,但對關聯新數據沒有用處。
為了解決過度擬合的問題,最好的解決方案是收集更多的訓練數據:模型看到的數據越多,它學習新數據表示的概率就越大。 然而,收集更多的訓練數據可能比解決一個需要解決的主要問題更昂貴。 為了解決這個限制,我們可以創建假數據並將其添加到訓練集中。 這被稱為數據增強。
深度數據增強
從圖像中學習視覺表示的前提幫助解決了許多計算機視覺問題。 但是,當我們要訓練的數據集較小時,這些視覺表示可能會產生誤導。 數據增強是克服這一缺點的絕佳策略。
在增強過程中,訓練集中的圖像通過旋轉、縮放、剪切等某些操作進行轉換。例如:如果訓練集僅包含站立位置的人類圖像,那麼我們正在嘗試構建的分類器可能無法預測人類躺下的圖像,因此增強可以通過將訓練集的圖片旋轉 90 度來模擬人類躺下的圖像。

這是擴展數據集和增加模型驗證指標的一種廉價且重要的方法。
數據增強是一個強大的工具,特別是對於像對象識別這樣的分類問題。 像在每個方向上將訓練圖像平移幾個像素這樣的操作通常可以大大提高泛化能力。
增強的另一個優點是圖像在流上進行轉換,這意味著現有數據集不會被覆蓋。 當圖像被加載到神經網絡中進行訓練時,將進行增強,因此,這不會增加內存需求並保留數據以進行進一步的實驗。
在收集新數據成本高昂的情況下,應用增強等轉化技術非常有用,但必須記住不要應用可能會改變訓練類現有分佈的轉換。 例如,如果訓練集包含 0 到 9 的手寫數字圖像,則翻轉/旋轉數字“6”和“9”不是適當的轉換,因為這會使訓練集過時。
另請閱讀:頂級機器學習數據集項目創意
將數據增強與 TensorFlow 結合使用
可以通過使用 Keras 的ImageDataGenerator API 以 TensorFlow 作為後端來實現增強。 ImageDataGenerator實例可以在訓練點對圖像執行許多隨機變換。 在這種情況下可用的一些流行論點是:
- rotation_range: 0-180 之間的整數值,用於隨機旋轉圖片。
- width_shift_range:圍繞其框架水平移動圖像以生成更多示例。
- height_shift_range:圍繞其框架垂直移動圖像以生成更多示例。
- 剪切範圍:對圖像應用隨機剪切變換以生成多個示例。
- zoom_range:要隨機縮放的圖像的相對部分。
- Horizontal_flip :用於水平翻轉圖像。
- fill_mode:填充新創建的像素的方法。
下面是演示如何使用ImageDataGenerator實例執行上述轉換的代碼片段:

- train_datagen = ImageDataGenerator(
- 重新縮放=1./255,
- 旋轉範圍=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- 剪切範圍=0.2,
- 縮放範圍=0.2,
- 水平翻轉=真,
- 填充模式='最近的')
看到在訓練集上應用這些隨機變換的結果也很簡單。 為此,我們可以通過迭代訓練集來顯示一些隨機增強的訓練圖像:

圖 1:使用增強生成的圖像
(圖片來自 Francois Chollet 的 Python 深度學習,第 5 章,第 140 頁)
圖 1 讓我們了解了增強如何從單個輸入圖像生成多個圖像,所有圖像在表面上彼此不同,這僅僅是因為在訓練時對它們執行了隨機變換。
要理解使用增強策略的真正本質,我們必須理解它對模型的訓練和驗證指標的影響。 為此,我們將訓練兩個模型:一個不使用數據增強,另一個將。 為了驗證這一點,我們將使用Cats and Dogs數據集,該數據集位於:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
兩種模型觀察到的準確度曲線如下圖所示:
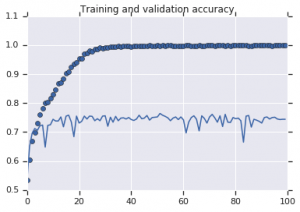
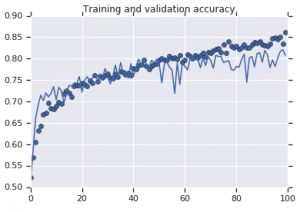
圖 2:訓練和驗證準確性。 左:沒有增強的模型。 右:具有隨機數據增強變換的模型。
必讀:用於情緒分析的頂級已建立數據集
結論
從圖 2 可以明顯看出,在沒有增強策略的情況下訓練的模型顯示出低泛化能力。 模型在驗證集上的表現與訓練集上的表現不相上下。 這意味著模型已經過擬合。
另一方面,使用增強策略的第二個模型顯示了出色的指標,驗證準確度與訓練準確度一樣高。 這證明了在模型顯示出過度擬合跡象的情況下,使用數據集增強技術變得多麼有用。
如果您對學習情感分析和相關技術(如人工智能和機器學習)進一步感興趣,您可以查看我們的機器學習和人工智能 PG 文憑課程。