
Aumento do conjunto de dados: criando dados artificiais [explicado de forma simples]
Publicados: 2020-12-07Índice
Introdução
Ao projetar qualquer algoritmo de aprendizado de máquina, sempre é preciso manter o equilíbrio entre otimização e generalização . Essas palavras podem parecer muito complicadas para iniciantes, mas saber a diferença entre elas em um estágio inicial durante sua jornada para dominar o aprendizado de máquina definitivamente os ajudará a entender o funcionamento subjacente de por que seu modelo se comporta de uma maneira específica.
O aspecto da otimização refere-se ao ajuste do modelo de forma que seu desempenho nos dados de treinamento esteja no máximo. Por outro lado, a generalização diz respeito ao desempenho de um modelo de aprendizagem em dados que ele nunca viu antes, ou seja, em um conjunto de validação.
Muitas vezes chega um momento em que após um certo número de épocas nos dados de treinamento, a generalização do modelo para de melhorar e as métricas de validação começam a se degradar, este é o caso em que se diz que o modelo está superajustado, ou seja, onde ele começa a aprender informações específicas para os dados de treinamento, mas não é útil para correlacionar com novos dados.
Para resolver o problema de overfitting, a melhor solução é reunir mais dados de treinamento: quanto mais dados o modelo tiver visto, melhor será sua probabilidade de aprender representações dos novos dados também. No entanto, coletar mais dados de treinamento pode ser mais caro do que resolver o problema principal que é necessário resolver. Para contornar essa limitação, podemos criar dados falsos e adicioná-los ao conjunto de treinamento. Isso é conhecido como aumento de dados.
Aumento de dados em profundidade
A premissa de aprender representações visuais a partir de imagens tem ajudado a resolver muitos problemas de visão computacional. No entanto, quando temos um conjunto de dados menor para treinar, essas representações visuais podem ser enganosas. O aumento de dados é uma excelente estratégia para superar essa desvantagem.
Durante o aumento, as imagens no conjunto de treinamento são transformadas por certas operações como rotação, dimensionamento, cisalhamento, etc. Por exemplo: se o conjunto de treinamento consiste em imagens de humanos apenas em pé, o classificador que estamos tentando construir pode falhar em prever as imagens de humanos deitados, então o aumento pode simular a imagem de humanos deitados girando as imagens do conjunto de treinamento em 90 graus.

Essa é uma maneira barata e significativa de estender o conjunto de dados e aumentar as métricas de validação do modelo.
O aumento de dados é uma ferramenta poderosa especialmente para problemas de classificação como reconhecimento de objetos. Operações como traduzir as imagens de treinamento alguns pixels em cada direção geralmente podem melhorar muito a generalização.
Outro recurso vantajoso do aumento é que as imagens são transformadas no fluxo, o que significa que o conjunto de dados existente não é substituído. O aumento ocorrerá quando as imagens estiverem sendo carregadas na rede neural para treinamento e, portanto, isso não aumentará os requisitos de memória e preservará os dados também para novas experiências.
A aplicação de técnicas translacionais como o aumento é muito útil onde a coleta de novos dados é cara, embora se deva ter em mente para não aplicar transformações que possam alterar a distribuição existente da classe de treinamento. Por exemplo, se o conjunto de treinamento inclui imagens de dígitos manuscritos de 0 a 9, então inverter/girar os dígitos “6” e “9” não é uma transformação apropriada, pois isso tornará o conjunto de treinamento obsoleto.
Leia também: Principais ideias de projetos de conjuntos de dados de machine learning
Como usar o aumento de dados com o TensorFlow
O aumento pode ser obtido usando a API ImageDataGenerator da Keras usando o TensorFlow como back-end. A instância ImageDataGenerator pode realizar várias transformações aleatórias nas imagens no ponto de treinamento. Alguns dos argumentos populares disponíveis neste caso são:

- range_rotação: Um valor inteiro em graus entre 0-180 para girar imagens aleatoriamente.
- width_shift_range: Deslocando a imagem horizontalmente em torno de seu quadro para gerar mais exemplos.
- height_shift_range: Deslocando a imagem verticalmente em torno de seu quadro para gerar mais exemplos.
- shear_range: aplique transformações de cisalhamento aleatórias na imagem para gerar vários exemplos.
- zoom_range: Porção relativa da imagem para zoom aleatório.
- horizontal_flip: Usado para inverter as imagens horizontalmente.
- fill_mode: Método para preenchimento de pixels recém-criados.
Abaixo está o trecho de código que demonstra como a instância ImageDataGenerator pode ser usada para realizar a transformação mencionada:
- train_datagen = ImageDataGenerator(
- redimensionar=1./255,
- intervalo_rotação=40,
- largura_deslocamento_intervalo=0,2,
- height_shift_range=0,2,
- shear_range=0,2,
- zoom_range=0,2,
- horizontal_flip=Verdadeiro,
- fill_mode='mais próximo')
Também é trivial ver o resultado da aplicação dessas transformações aleatórias no conjunto de treinamento. Para isso, podemos exibir algumas imagens de treinamento aumentadas aleatoriamente, iterando sobre o conjunto de treinamento:

Figura 1: Imagens geradas usando aumento
(Imagem de Deep Learning com Python por François Chollet, Capítulo 5, página 140)
A Figura 1 nos dá uma ideia de como o aumento pode produzir várias imagens a partir de uma única imagem de entrada com todas as imagens sendo superficialmente diferentes umas das outras apenas por causa das transformações aleatórias que foram realizadas nelas no tempo de treinamento.
Para entender a verdadeira essência do uso de estratégias de aumento, devemos compreender seu impacto nas métricas de treinamento e validação do modelo. Para isso, treinaremos dois modelos: um não utilizará data augmentation e o outro. Para validar isso, usaremos o conjunto de dados Cats and Dogs que está disponível em:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
As curvas de precisão que foram observadas para ambos os modelos estão representadas abaixo:
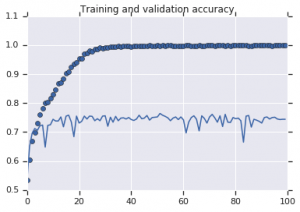
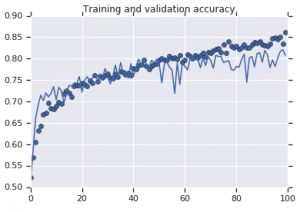
Figura 2: Precisão de treinamento e validação. Esquerda : Modelo sem aumento. Direita : Modelo com transformações de aumento de dados aleatórios.
Deve ler: Principais conjuntos de dados estabelecidos para análise de sentimento
Conclusão
Fica evidente na Figura 2 que o modelo treinado sem estratégias de aumento apresenta baixo poder de generalização. O desempenho do modelo no conjunto de validação não é igual ao do conjunto de treinamento. Isso significa que o modelo foi superajustado.
Por outro lado, o segundo modelo que usa estratégias de aumento mostra excelentes métricas com a precisão da validação subindo tão alto quanto a precisão do treinamento. Isso demonstra como é útil empregar técnicas de aumento de conjunto de dados onde um modelo mostra sinais de overfitting.
Se você estiver ainda mais interessado em aprender sobre análise de sentimentos e as tecnologias associadas, como inteligência artificial e aprendizado de máquina, confira nosso curso PG Diploma in Machine Learning and AI .