
Augmentasi Dataset: Membuat Data Buatan [Dijelaskan Secara Sederhana]
Diterbitkan: 2020-12-07Daftar isi
pengantar
Saat merancang algoritme pembelajaran mesin apa pun, Anda harus selalu menjaga keseimbangan antara pengoptimalan dan generalisasi . Kata-kata ini mungkin tampak terlalu rumit untuk pemula, tetapi mengetahui perbedaan di antara mereka pada tahap awal selama perjalanan mereka untuk menguasai pembelajaran mesin pasti akan membantu mereka memahami cara kerja yang mendasari mengapa model mereka berperilaku dengan cara tertentu.
Aspek optimasi mengacu pada penyetelan model sedemikian rupa sehingga kinerjanya pada data pelatihan berada pada puncaknya. Di sisi lain, generalisasi berkaitan dengan kinerja model pembelajaran pada data yang belum pernah terlihat sebelumnya, yaitu pada set validasi.
Ada saatnya ketika setelah sejumlah epoch tertentu pada data pelatihan, generalisasi model berhenti membaik dan metrik validasi mulai menurun, ini adalah kasus di mana model dikatakan overfit, yaitu di mana ia mulai mempelajari informasi khusus untuk data pelatihan tetapi tidak berguna untuk menghubungkan ke data baru.
Untuk mengatasi masalah overfitting, solusi terbaik adalah mengumpulkan lebih banyak data pelatihan: semakin banyak data yang telah dilihat model, semakin baik kemungkinannya untuk mempelajari representasi data baru juga. Namun, mengumpulkan lebih banyak data pelatihan mungkin lebih mahal daripada memecahkan masalah utama yang perlu ditangani. Untuk mengatasi batasan ini, kita dapat membuat data palsu dan menambahkannya ke set pelatihan. Ini dikenal sebagai augmentasi data.
Augmentasi Data secara Mendalam
Premis pembelajaran representasi visual dari gambar telah membantu memecahkan banyak masalah visi komputer. Namun, ketika kita memiliki kumpulan data yang lebih kecil untuk dilatih, maka representasi visual ini mungkin menyesatkan. Augmentasi data adalah strategi yang sangat baik untuk mengatasi kelemahan ini.
Selama augmentasi, gambar dalam set pelatihan ditransformasikan oleh operasi tertentu seperti rotasi, penskalaan, geser, dll. Misalnya: jika set pelatihan terdiri dari gambar manusia dalam posisi berdiri saja, maka classifier yang kita coba bangun mungkin gagal untuk memprediksi gambar manusia berbaring, sehingga augmentasi dapat mensimulasikan gambar manusia berbaring dengan memutar gambar pelatihan yang ditetapkan sebesar 90 derajat.

Ini adalah cara yang murah dan signifikan untuk memperluas kumpulan data dan meningkatkan metrik validasi model.
Augmentasi data adalah alat yang ampuh terutama untuk masalah klasifikasi seperti pengenalan objek. Operasi seperti menerjemahkan gambar pelatihan beberapa piksel di setiap arah seringkali dapat sangat meningkatkan generalisasi.
Fitur augmentasi lain yang menguntungkan adalah bahwa gambar ditransformasikan pada aliran, yang berarti bahwa kumpulan data yang ada tidak diganti. Augmentasi akan terjadi ketika gambar dimuat ke jaringan saraf untuk pelatihan dan karenanya, ini tidak akan meningkatkan kebutuhan memori dan juga menyimpan data untuk eksperimen lebih lanjut.
Menerapkan teknik translasi seperti augmentasi sangat berguna di mana pengumpulan data baru mahal, meskipun harus diingat untuk tidak menerapkan transformasi yang dapat mengubah distribusi kelas pelatihan yang ada. Misalnya, jika set pelatihan menyertakan gambar angka tulisan tangan dari 0 hingga 9, maka membalik/memutar angka "6" dan "9" bukanlah transformasi yang tepat karena ini akan membuat set pelatihan menjadi usang.
Baca Juga: Ide Proyek Kumpulan Data Pembelajaran Mesin Teratas
Menggunakan Augmentasi Data dengan TensorFlow
Augmentasi dapat dicapai dengan menggunakan ImageDataGenerator API dari Keras menggunakan TensorFlow sebagai backend. Instance ImageDataGenerator dapat melakukan sejumlah transformasi acak pada gambar di titik pelatihan. Beberapa argumen populer yang tersedia dalam contoh ini adalah:

- rotasi_range : Nilai integer dalam derajat antara 0-180 untuk memutar gambar secara acak.
- width_shift_range: Menggeser gambar secara horizontal di sekitar bingkainya untuk menghasilkan lebih banyak contoh.
- height_shift_range: Menggeser gambar secara vertikal di sekitar bingkainya untuk menghasilkan lebih banyak contoh.
- shear_range: Terapkan transformasi geser acak pada gambar untuk menghasilkan banyak contoh.
- zoom_range: Bagian relatif dari gambar untuk diperbesar secara acak.
- horizontal_flip: Digunakan untuk membalik gambar secara horizontal.
- fill_mode: Metode untuk mengisi piksel yang baru dibuat.
Di bawah ini adalah cuplikan kode yang menunjukkan bagaimana instance ImageDataGenerator dapat digunakan untuk melakukan transformasi yang disebutkan di atas:
- train_datagen = ImageDataGenerator(
- skala ulang=1./255,
- rotasi_rentang=40,
- lebar_shift_range=0.2,
- ketinggian_shift_range=0.2,
- rentang_geser=0.2,
- rentang_zoom=0.2,
- horizontal_flip=Benar,
- fill_mode='terdekat')
Hal ini juga sepele untuk melihat hasil dari penerapan transformasi acak ini pada set pelatihan. Untuk ini, kami dapat menampilkan beberapa gambar pelatihan yang diperbesar secara acak dengan mengulangi set pelatihan:

Gambar 1: Gambar yang dihasilkan menggunakan augmentasi
(Gambar dari Deep Learning dengan Python oleh Francois Chollet, Bab 5, halaman 140)
Gambar 1 memberi kita gambaran tentang bagaimana augmentasi dapat menghasilkan banyak gambar dari satu gambar input dengan semua gambar yang sangat berbeda satu sama lain hanya karena transformasi acak yang dilakukan pada gambar tersebut pada waktu pelatihan.
Untuk memahami esensi sebenarnya dari penggunaan strategi augmentasi, kita harus memahami dampaknya pada metrik pelatihan dan validasi model. Untuk ini, kami akan melatih dua model: satu tidak akan menggunakan augmentasi data dan yang lainnya akan. Untuk memvalidasi ini, kami akan menggunakan dataset Cats and Dogs yang tersedia di:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Kurva akurasi yang diamati untuk kedua model diplot di bawah ini:
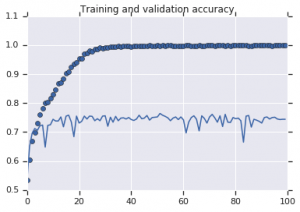
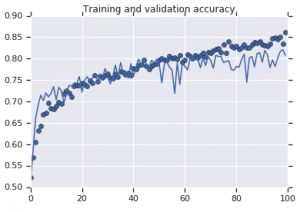
Gambar 2: Akurasi pelatihan dan validasi. Kiri : Model tanpa augmentasi. Kanan : Model dengan transformasi augmentasi data acak.
Harus Dibaca: Kumpulan Data Teratas Untuk Analisis Sentimen
Kesimpulan
Terlihat dari Gambar 2 bahwa model yang dilatih tanpa strategi augmentasi menampilkan kekuatan generalisasi yang rendah. Performa model di set validasi tidak setara dengan di set pelatihan. Ini berarti model telah overfitted.
Di sisi lain, model kedua yang menggunakan strategi augmentasi menunjukkan metrik yang sangat baik dengan akurasi validasi mendaki setinggi akurasi pelatihan. Ini menunjukkan betapa bergunanya menggunakan teknik augmentasi kumpulan data di mana model menunjukkan tanda-tanda overfitting.
Jika Anda lebih tertarik untuk mempelajari tentang analisis sentimen dan teknologi yang terkait, seperti kecerdasan buatan dan pembelajaran mesin, Anda dapat memeriksa Diploma PG kami dalam Pembelajaran Mesin dan kursus AI.