
Rozszerzenie zestawu danych: tworzenie sztucznych danych [wyjaśnione po prostu]
Opublikowany: 2020-12-07Spis treści
Wstęp
Projektując dowolny algorytm uczenia maszynowego, zawsze trzeba zachować kompromis między optymalizacją a uogólnianiem . Te słowa mogą wydawać się zbyt skomplikowane dla nowicjuszy, ale poznanie różnicy między nimi na wczesnym etapie ich drogi do opanowania uczenia maszynowego z pewnością pomoże im zrozumieć, dlaczego ich model zachowuje się w określony sposób.
Aspekt optymalizacji odnosi się do dostrojenia modelu tak, aby jego wydajność na danych uczących była maksymalna. Z drugiej strony uogólnienie odnosi się do wydajności modelu uczenia się na danych, których nigdy wcześniej nie widział, tj. na zbiorze walidacyjnym.
Często zdarza się, że po upływie określonej liczby epok na danych uczących uogólnienie modelu przestaje się poprawiać, a metryki walidacji zaczynają się pogarszać, tak jest w przypadku, gdy mówi się o przesunięciu modelu, tj. gdy zaczyna uczyć się informacji specyficznych dla dane treningowe, ale nie są przydatne do korelacji z nowymi danymi.
Aby rozwiązać problem nadmiernego dopasowania, najlepszym rozwiązaniem jest zebranie większej ilości danych uczących: im więcej danych zobaczył model, tym większe jest prawdopodobieństwo, że nauczy się również reprezentacji nowych danych. Jednak zebranie większej ilości danych szkoleniowych może być droższe niż rozwiązanie głównego problemu, z którym trzeba się uporać. Aby obejść to ograniczenie, możemy stworzyć fałszywe dane i dodać je do zestawu treningowego. Nazywa się to rozszerzaniem danych.
Rozszerzanie danych w głębi
Założenie uczenia się reprezentacji wizualnych z obrazów pomogło rozwiązać wiele problemów widzenia komputerowego. Jednak gdy mamy do dyspozycji mniejszy zbiór danych, te reprezentacje wizualne mogą wprowadzać w błąd. Rozszerzanie danych to doskonała strategia przezwyciężenia tej wady.
Podczas augmentacji obrazy w zbiorze uczącym są przekształcane przez pewne operacje, takie jak obracanie, skalowanie, ścinanie itp. Na przykład: jeśli zbiór uczący składa się tylko z obrazów ludzi w pozycji stojącej, to klasyfikator, który próbujemy zbudować może nie przewidywać obrazów ludzi leżących, więc augmentacja może symulować obraz ludzi leżących, obracając obrazy treningu ustawionego o 90 stopni.

Jest to tani i znaczący sposób na rozszerzenie zbioru danych i zwiększenie metryk walidacji modelu.
Rozszerzanie danych to potężne narzędzie, zwłaszcza w przypadku problemów z klasyfikacją, takich jak rozpoznawanie obiektów. Operacje takie jak tłumaczenie obrazów treningowych o kilka pikseli w każdym kierunku mogą często znacznie poprawić uogólnienie.
Inną korzystną cechą augmentacji jest to, że obrazy są przekształcane w przepływie, co oznacza, że istniejący zestaw danych nie jest nadpisywany. Rozszerzenie będzie miało miejsce, gdy obrazy będą ładowane do sieci neuronowej w celu treningu, a zatem nie zwiększy to wymagań dotyczących pamięci i zachowa dane również do dalszych eksperymentów.
Stosowanie technik translacyjnych, takich jak augmentacja, jest bardzo przydatne, gdy zbieranie nowych danych jest kosztowne, chociaż należy pamiętać, aby nie stosować transformacji, która może zmienić istniejącą dystrybucję klasy szkoleniowej. Na przykład, jeśli zbiór uczący zawiera obrazy odręcznych cyfr od 0 do 9, to odwracanie/obracanie cyfr „6” i „9” nie jest odpowiednią transformacją, ponieważ spowoduje to, że zbiór uczący stanie się przestarzały.
Przeczytaj także: Najlepsze pomysły na projekty dotyczące zestawów danych uczenia maszynowego
Korzystanie z rozszerzenia danych z TensorFlow
Rozszerzenie można osiągnąć za pomocą interfejsu API ImageDataGenerator firmy Keras przy użyciu TensorFlow jako backendu. Instancja ImageDataGenerator może wykonać szereg losowych przekształceń na obrazach w punkcie trenowania. Niektóre z popularnych argumentów dostępnych w tym przypadku to:

- zakres_rotacji: wartość całkowita w stopniach z zakresu od 0 do 180 do losowego obracania zdjęć.
- width_shift_range: Przesuwanie obrazu w poziomie wokół ramki, aby wygenerować więcej przykładów.
- zakres_przesunięcia_wysokości: Przesuwanie obrazu w pionie wokół jego ramki, aby wygenerować więcej przykładów.
- shear_range: Zastosuj losowe przekształcenia ścinania na obrazie, aby wygenerować wiele przykładów.
- zoom_range: Względna część obrazu do losowego powiększenia.
- horizontal_flip: Służy do odwracania obrazów w poziomie.
- fill_mode: Metoda wypełniania nowo utworzonych pikseli.
Poniżej znajduje się fragment kodu, który pokazuje, w jaki sposób można użyć instancji ImageDataGenerator do wykonania wspomnianej transformacji:
- train_datagen = GeneratorDanych Obrazów (
- przeskalowanie=1./255,
- zakres_rotacji=40,
- zakres_przesunięć_szerokości=0.2,
- zakres_przesunięcia_wysokości=0.2,
- zakres ścinania=0.2,
- zakres_powiększenia=0.2,
- horizontal_flip=Prawda,
- fill_mode='najbliższy')
Równie trywialne jest zobaczenie wyniku zastosowania tych losowych przekształceń w zbiorze uczącym. W tym celu możemy wyświetlić kilka losowo rozszerzonych obrazów treningowych, iterując po zbiorze treningowym:

Rysunek 1: Obrazy wygenerowane przy użyciu augmentacji
(Obraz z Deep Learning with Python autorstwa Francois Chollet, rozdział 5, strona 140)
Rysunek 1 daje nam wyobrażenie, w jaki sposób augmentacja może generować wiele obrazów z jednego obrazu wejściowego, przy czym wszystkie obrazy są powierzchownie różne od siebie tylko z powodu losowych przekształceń, które zostały na nich wykonane w czasie uczenia.
Aby zrozumieć prawdziwą istotę stosowania strategii augmentacji, musimy zrozumieć jej wpływ na metryki uczenia i walidacji modelu. W tym celu wyszkolimy dwa modele: jeden nie będzie korzystał z augmentacji danych, a drugi będzie. Aby to potwierdzić, użyjemy zestawu danych Koty i psy , który jest dostępny pod adresem:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Krzywe dokładności zaobserwowane dla obu modeli przedstawiono poniżej:
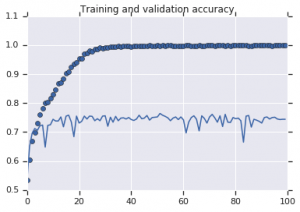
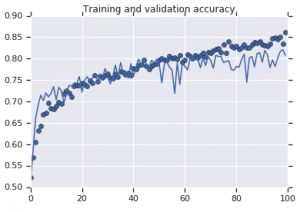
Rysunek 2: Dokładność szkolenia i walidacji. Po lewej : Model bez wzmocnienia. Po prawej : model z losowymi przekształceniami rozszerzającymi dane.
Trzeba przeczytać: najpopularniejsze zestawy danych do analizy nastrojów
Wniosek
Z rysunku 2 widać, że model wytrenowany bez strategii augmentacji wykazuje niską moc uogólniania. Wydajność modelu w zestawie walidacyjnym nie jest taka sama jak w zestawie uczącym. Oznacza to, że model jest przesadnie dopasowany.
Z drugiej strony, drugi model, który wykorzystuje strategie augmentacji, pokazuje doskonałe metryki z dokładnością walidacji rosnącą tak wysoko, jak dokładność treningu. Pokazuje to, jak przydatne staje się stosowanie technik rozszerzania zbioru danych, gdy model wykazuje oznaki nadmiernego dopasowania.
Jeśli chcesz dowiedzieć się więcej o analizie sentymentu i powiązanych technologiach, takich jak sztuczna inteligencja i uczenie maszynowe, możesz sprawdzić nasz kurs PG Diploma in Machine Learning i AI .