
การเพิ่มชุดข้อมูล: การสร้างข้อมูลเทียม [อธิบายอย่างง่าย]
เผยแพร่แล้ว: 2020-12-07สารบัญ
บทนำ
ในขณะที่ออกแบบอัลกอริธึมแมชชีนเลิร์นนิง เราจำเป็นต้องรักษาการประนีประนอมระหว่างการปรับให้ เหมาะสม และ ลักษณะทั่วไป เสมอ คำเหล่านี้อาจดูซับซ้อนเกินไปสำหรับมือใหม่ แต่การรู้ถึงความแตกต่างระหว่างคำเหล่านี้ในช่วงแรกระหว่างการเดินทางสู่การเรียนรู้ด้วยเครื่องหลัก จะช่วยให้พวกเขาเข้าใจการทำงานเบื้องหลังว่าทำไมแบบจำลองของพวกเขาจึงมีพฤติกรรมในลักษณะเฉพาะ
แง่มุมของการเพิ่มประสิทธิภาพหมายถึงการปรับโมเดลเพื่อให้ประสิทธิภาพในข้อมูลการฝึกอยู่ที่จุดสูงสุด ในทางกลับกัน การวางนัยทั่วไปเกี่ยวข้องกับประสิทธิภาพของโมเดลการเรียนรู้เกี่ยวกับข้อมูลที่ไม่เคยเห็นมาก่อน กล่าวคือ ในชุดการตรวจสอบความถูกต้อง
มักจะมีบางครั้งที่หลังจากช่วงเวลาหนึ่งของข้อมูลการฝึก การวางนัยทั่วไปของแบบจำลองหยุดการปรับปรุง และตัววัดการตรวจสอบเริ่มเสื่อมลง นี่เป็นกรณีที่กล่าวว่าแบบจำลอง เกินพอดี กล่าวคือ เริ่มเรียนรู้ข้อมูลเฉพาะสำหรับ ข้อมูลการฝึกอบรมแต่ไม่มีประโยชน์ในการเชื่อมโยงกับข้อมูลใหม่
วิธีแก้ปัญหาที่ดีที่สุดคือการรวบรวมข้อมูลการฝึกอบรมเพิ่มเติม: ยิ่งแบบจำลองเห็นข้อมูลมากเท่าใด ความน่าจะเป็นที่จะเรียนรู้การแสดงข้อมูลใหม่ก็จะยิ่งดีขึ้นด้วย อย่างไรก็ตาม การรวบรวมข้อมูลการฝึกอบรมเพิ่มเติมอาจมีราคาแพงกว่าการแก้ปัญหาหลักที่ต้องจัดการ เพื่อหลีกเลี่ยงข้อจำกัดนี้ เราสามารถสร้างข้อมูลปลอมและเพิ่มลงในชุดการฝึกได้ สิ่งนี้เรียกว่าการเพิ่มข้อมูล
การเสริมข้อมูลในเชิงลึก
สมมติฐานของการเรียนรู้การแสดงภาพจากภาพได้ช่วยแก้ปัญหาการมองเห็นคอมพิวเตอร์จำนวนมาก อย่างไรก็ตาม เมื่อเรามีชุดข้อมูลขนาดเล็กกว่าที่จะฝึก การแสดงภาพเหล่านี้อาจทำให้เข้าใจผิดได้ การเพิ่มข้อมูลเป็นกลยุทธ์ที่ยอดเยี่ยมในการเอาชนะข้อเสียนี้
ในระหว่างการเสริมแต่ง รูปภาพในชุดฝึกจะถูกแปลงโดยการดำเนินการบางอย่าง เช่น การหมุน การสเกล การตัด เป็นต้น ตัวอย่างเช่น หากชุดการฝึกประกอบด้วยภาพมนุษย์ในท่ายืนเท่านั้น ตัวแยกประเภทที่เรากำลังพยายามสร้าง อาจล้มเหลวในการทำนายภาพมนุษย์นอนราบ ดังนั้นการเสริมสามารถจำลองภาพมนุษย์นอนราบโดยหมุนภาพการฝึกที่ตั้งไว้ 90 องศา

นี่เป็นวิธีที่ถูกและสำคัญในการขยายชุดข้อมูลและเพิ่มเมตริกการตรวจสอบความถูกต้องของแบบจำลอง
การเสริมข้อมูลเป็นเครื่องมือที่ทรงพลังโดยเฉพาะอย่างยิ่งสำหรับปัญหาการจำแนกประเภท เช่น การจดจำวัตถุ การดำเนินการต่างๆ เช่น การแปลภาพการฝึกไม่กี่พิกเซลในแต่ละทิศทางมักจะสามารถปรับปรุงลักษณะทั่วไปได้อย่างมาก
คุณสมบัติที่ได้เปรียบอีกประการของการเพิ่มคือ รูปภาพจะถูกแปลงในโฟลว์ ซึ่งหมายความว่าชุดข้อมูลที่มีอยู่จะไม่ถูกแทนที่ การเสริมจะเกิดขึ้นเมื่อมีการโหลดภาพลงในโครงข่ายประสาทเทียมสำหรับการฝึก ดังนั้น การดำเนินการนี้จะไม่เพิ่มความต้องการหน่วยความจำและรักษาข้อมูลไว้สำหรับการทดลองต่อไป
การใช้เทคนิคการแปล เช่น การเสริม มีประโยชน์มากในการรวบรวมข้อมูลใหม่ซึ่งมีราคาแพง แม้ว่าจะต้องจำไว้ว่าอย่าใช้การแปลงที่อาจเปลี่ยนการกระจายที่มีอยู่ของชั้นเรียนการฝึกอบรม ตัวอย่างเช่น หากชุดการฝึกมีรูปภาพของตัวเลขที่เขียนด้วยลายมือตั้งแต่ 0 ถึง 9 การพลิก/หมุนหลัก "6" และ "9" จะไม่ใช่การแปลงที่เหมาะสม เนื่องจากจะทำให้ชุดการฝึกล้าสมัย
อ่านเพิ่มเติม: แนวคิดโครงการชุดข้อมูลการเรียนรู้ของเครื่องยอดนิยม
การใช้การเพิ่มข้อมูลด้วย TensorFlow
การเพิ่มสามารถทำได้โดยใช้ ImageDataGenerator API จาก Keras โดยใช้ TensorFlow เป็นแบ็กเอนด์ อิน ส แตนซ์ ImageDataGenerator สามารถทำการแปลงแบบสุ่มจำนวนหนึ่งในอิมเมจที่จุดฝึกอบรม อาร์กิวเมนต์ยอดนิยมบางส่วนที่มีอยู่ในตัวอย่างนี้คือ:

- rotation_range: ค่าจำนวนเต็มในหน่วยองศาระหว่าง 0-180 เพื่อหมุนรูปภาพแบบสุ่ม
- width_shift_range: เลื่อนรูปภาพในแนวนอนไปรอบๆ กรอบเพื่อสร้างตัวอย่างเพิ่มเติม
- height_shift_range: เลื่อนรูปภาพในแนวตั้งไปรอบๆ เฟรมเพื่อสร้างตัวอย่างเพิ่มเติม
- shear_range: ใช้การแปลงแบบตัดเฉือนแบบสุ่มบนรูปภาพเพื่อสร้างตัวอย่างหลายตัวอย่าง
- zoom_range: ส่วนสัมพันธ์ของรูปภาพเพื่อซูมแบบสุ่ม
- แนวนอน_พลิก: ใช้สำหรับพลิกภาพในแนวนอน
- fill_mode: วิธีการเติมพิกเซลที่สร้างขึ้นใหม่
ด้านล่างนี้คือข้อมูลโค้ดซึ่งแสดงให้เห็นว่า อินสแตนซ์ ImageDataGenerator สามารถใช้เพื่อดำเนินการแปลงดังกล่าวได้อย่างไร:
- train_datagen = ImageDataGenerator (
- ปรับสเกล = 1./255,
- การหมุน_range=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- shear_range=0.2,
- zoom_range=0.2,
- แนวนอน_flip=จริง,
- fill_mode='ใกล้ที่สุด')
การเห็นผลของการใช้การแปลงแบบสุ่มเหล่านี้กับชุดการฝึกนั้นเป็นเรื่องเล็กน้อย สำหรับสิ่งนี้ เราสามารถแสดงภาพการฝึกที่เสริมแบบสุ่มโดยการวนซ้ำในชุดการฝึก:

รูปที่ 1: รูปภาพที่สร้างขึ้นโดยใช้การเสริม
(รูปภาพจาก Deep Learning with Python โดย Francois Chollet บทที่ 5 หน้า 140)
รูปที่ 1 ให้แนวคิดว่าการเสริมแต่งสามารถสร้างรูปภาพหลายภาพจากอิมเมจอินพุตเดียวได้อย่างไร โดยที่รูปภาพทั้งหมดมีความแตกต่างกันอย่างผิวเผินเพียงเพราะการแปลงแบบสุ่มที่ดำเนินการกับรูปภาพเหล่านั้นในเวลาฝึก
เพื่อให้เข้าใจถึงสาระสำคัญที่แท้จริงของการใช้กลยุทธ์การเสริม เราต้องเข้าใจผลกระทบของมันต่อเมตริกการฝึกอบรมและการตรวจสอบความถูกต้องของแบบจำลอง สำหรับสิ่งนี้ เราจะฝึกสองโมเดล: หนึ่งจะไม่ใช้การเสริมข้อมูล และอีกอันหนึ่งจะ เพื่อตรวจสอบสิ่งนี้ เราจะใช้ ชุดข้อมูล Cats and Dogs ซึ่งมีอยู่ที่:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
เส้นกราฟความแม่นยำที่สังเกตได้จากทั้งสองรุ่นมีแผนภาพด้านล่าง:
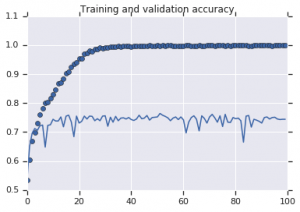
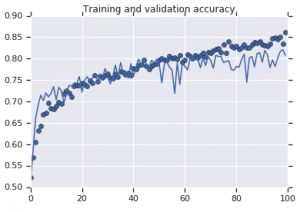
รูปที่ 2: การฝึกอบรมและความถูกต้องในการตรวจสอบ ซ้าย : รุ่นไม่เสริม ขวา : โมเดลที่มีการแปลงการเพิ่มข้อมูลแบบสุ่ม
ต้องอ่าน: ชุดข้อมูลที่มีความเสถียรสูงสุดสำหรับการวิเคราะห์ความเชื่อมั่น
บทสรุป
เห็นได้ชัดจากรูปที่ 2 ว่าแบบจำลองที่ได้รับการฝึกฝนโดยไม่มีกลยุทธ์การเสริมแสดงพลังการวางนัยทั่วไปที่ต่ำ ประสิทธิภาพของแบบจำลองในชุดการตรวจสอบความถูกต้องไม่เทียบเท่ากับชุดการฝึก ซึ่งหมายความว่าโมเดลมีการติดตั้งมากเกินไป
ในทางกลับกัน รุ่นที่สองที่ใช้กลยุทธ์การเสริมแสดงตัวชี้วัดที่ยอดเยี่ยมพร้อมความแม่นยำในการตรวจสอบความถูกต้องที่ไต่ขึ้นสูงเท่ากับความแม่นยำในการฝึก สิ่งนี้แสดงให้เห็นว่ามีประโยชน์เพียงใดในการใช้เทคนิคการเสริมชุดข้อมูลที่แบบจำลองแสดงสัญญาณของการใส่มากเกินไป
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับการวิเคราะห์ความรู้สึกและเทคโนโลยีที่เกี่ยวข้อง เช่น ปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง คุณสามารถตรวจสอบ หลักสูตร PG Diploma in Machine Learning และ AI