
Veri Kümesi Büyütme: Yapay Veri Oluşturma [Basitçe Açıklandı]
Yayınlanan: 2020-12-07İçindekiler
Tanıtım
Herhangi bir makine öğrenimi algoritması tasarlarken, her zaman optimizasyon ve genelleme arasındaki dengeyi korumak gerekir . Bu kelimeler acemiler için çok karmaşık görünebilir, ancak makine öğreniminde ustalaşma yolculukları sırasında erken bir aşamada aralarındaki farkı bilmek, modellerinin neden belirli bir şekilde davrandığının altında yatan çalışmayı anlamalarına kesinlikle yardımcı olacaktır.
Optimizasyonun yönü, modelin eğitim verileri üzerindeki performansının zirvede olacağı şekilde ayarlanmasını ifade eder. Öte yandan, genelleme, bir öğrenme modelinin daha önce hiç görmediği veriler üzerindeki, yani bir doğrulama setindeki performansıyla ilgilidir.
Eğitim verilerinde belirli sayıda çağdan sonra, modelin genellemesinin gelişmeyi bıraktığı ve doğrulama metriklerinin bozulmaya başladığı bir zaman sıklıkla gelir; bu, modelin fazla uyduğunun söylendiği, yani modele özgü bilgileri öğrenmeye başladığı yerdir. eğitim verileridir ancak yeni verilerle ilişkilendirme için kullanışlı değildir.
Fazla uydurma sorununu çözmek için en iyi çözüm daha fazla eğitim verisi toplamaktır: model ne kadar çok veri görmüşse, yeni verinin temsillerini öğrenme olasılığı da o kadar iyidir. Bununla birlikte, daha fazla eğitim verisi toplamak, üstesinden gelinmesi gereken ana sorunu çözmekten daha pahalı olabilir. Bu sınırlamayı aşmak için sahte veriler oluşturabilir ve eğitim setine ekleyebiliriz. Bu, veri büyütme olarak bilinir.
Derinlikte Veri Geliştirme
Görüntülerden görsel temsilleri öğrenme öncülü, birçok bilgisayarla görme probleminin çözülmesine yardımcı olmuştur. Bununla birlikte, üzerinde çalışacağımız daha küçük bir veri kümemiz olduğunda, bu görsel temsiller yanıltıcı olabilir. Veri büyütme, bu dezavantajın üstesinden gelmek için mükemmel bir stratejidir.
Büyütme sırasında, eğitim setindeki görüntüler döndürme, ölçekleme, kesme vb. gibi belirli işlemlerle dönüştürülür. Örneğin: eğitim seti yalnızca ayakta duran insan görüntülerinden oluşuyorsa, oluşturmaya çalıştığımız sınıflandırıcı uzanmış insanların görüntülerini tahmin etmede başarısız olabilir, bu nedenle büyütme, eğitim setinin resimlerini 90 derece döndürerek yatan insanların görüntüsünü simüle edebilir.

Bu, veri kümesini genişletmenin ve modelin doğrulama ölçütlerini artırmanın ucuz ve önemli bir yoludur.
Veri büyütme, özellikle nesne tanıma gibi sınıflandırma problemleri için güçlü bir araçtır. Eğitim görüntülerini her yönde birkaç piksel çevirmek gibi işlemler genellikle genellemeyi büyük ölçüde iyileştirebilir.
Büyütmenin bir diğer avantajlı özelliği, görüntülerin akış üzerinde dönüştürülmesidir, bu da mevcut veri setinin geçersiz kılınmadığı anlamına gelir. Büyütme, görüntüler eğitim için sinir ağına yüklenirken gerçekleşecek ve bu nedenle bu, bellek gereksinimlerini artırmayacak ve verileri daha sonraki deneyler için korumayacaktır.
Yeni veri toplamanın pahalı olduğu durumlarda büyütme gibi çeviri tekniklerini uygulamak çok faydalıdır, ancak eğitim sınıfının mevcut dağılımını değiştirebilecek dönüşüm uygulanmaması akılda tutulmalıdır. Örneğin, eğitim seti 0'dan 9'a kadar el yazısı rakamların resimlerini içeriyorsa, o zaman “6” ve “9” rakamlarını çevirmek/döndürmek eğitim setini geçersiz kılacağından uygun bir dönüşüm değildir.
Ayrıca Okuyun: En İyi Makine Öğrenimi Veri Kümeleri Proje Fikirleri
TensorFlow ile Veri Geliştirmeyi Kullanma
Arttırma, arka uç olarak TensorFlow kullanılarak Keras'tan ImageDataGenerator API kullanılarak gerçekleştirilebilir. ImageDataGenerator örneği , eğitim noktasında görüntüler üzerinde bir dizi rastgele dönüşüm gerçekleştirebilir . Bu örnekte mevcut olan popüler argümanlardan bazıları şunlardır:

- döndürme_aralığı: Resimleri rastgele döndürmek için 0-180 arasında derece cinsinden bir tamsayı değeri.
- width_shift_range: Daha fazla örnek oluşturmak için görüntüyü çerçevesi etrafında yatay olarak kaydırma.
- height_shift_range: Daha fazla örnek oluşturmak için görüntüyü çerçevesi etrafında dikey olarak kaydırma.
- shear_range: Birden çok örnek oluşturmak için görüntüye rastgele kesme dönüşümleri uygulayın.
- zoom_range: Görüntünün rastgele yakınlaştırılacak göreli kısmı.
- horizontal_flip: Görüntüleri yatay olarak çevirmek için kullanılır.
- fill_mode: Yeni oluşturulan pikselleri doldurma yöntemi.
Aşağıda, yukarıda bahsedilen dönüşümü gerçekleştirmek için ImageDataGenerator örneğinin nasıl kullanılabileceğini gösteren kod parçacığı yer almaktadır :
- train_datagen = ImageDataGenerator(
- yeniden ölçeklendirme=1./255,
- rotasyon_aralığı=40,
- genişlik_kaydırma_aralığı=0.2,
- height_shift_range=0.2,
- kesme_aralığı=0.2,
- zoom_range=0.2,
- yatay_flip=Doğru,
- fill_mode='en yakın')
Bu rasgele dönüşümlerin eğitim kümesine uygulanmasının sonucunu görmek de önemsizdir. Bunun için eğitim seti üzerinde yineleme yaparak bazı rastgele artırılmış eğitim görüntülerini görüntüleyebiliriz:

Şekil 1: Büyütme kullanılarak oluşturulan görüntüler
(Francois Chollet, Bölüm 5, sayfa 140'tan Python ile Derin Öğrenme'den bir görüntü)
Şekil 1 bize, tüm görüntülerin yalnızca eğitim zamanında üzerlerinde gerçekleştirilen rastgele dönüşümler nedeniyle yüzeysel olarak farklı olduğu tek bir giriş görüntüsünden birden çok görüntü üretebileceğine dair bir fikir verir.
Büyütme stratejilerini kullanmanın gerçek özünü anlamak için, modelin eğitim ve doğrulama metrikleri üzerindeki etkisini anlamamız gerekir. Bunun için iki model eğiteceğiz: biri veri büyütmeyi kullanmayacak, diğeri kullanacak. Bunu doğrulamak için şu adreste bulunan Cats and Dogs veri setini kullanacağız:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Her iki model için de gözlemlenen doğruluk eğrileri aşağıda gösterilmiştir:
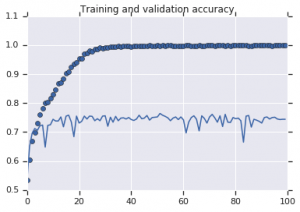
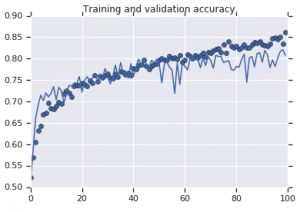
Şekil 2: Eğitim ve doğrulama doğruluğu. Sol : Büyütme olmayan model. Sağ : Rastgele veri artırma dönüşümlerine sahip model.
Okumalısınız: Duyarlılık Analizi İçin En İyi Sabitlenmiş Veri Kümeleri
Çözüm
Büyütme stratejileri olmadan eğitilen modelin düşük genelleme gücü gösterdiği Şekil 2'den açıkça görülmektedir. Modelin doğrulama setindeki performansı, eğitim setindeki ile aynı değildir. Bu, modelin fazla takıldığı anlamına gelir.
Öte yandan, büyütme stratejilerini kullanan ikinci model, doğrulama doğruluğunun eğitim doğruluğu kadar yüksek çıkmasıyla mükemmel metrikler gösterir. Bu, bir modelin fazla uyum belirtileri gösterdiği durumlarda veri kümesi büyütme tekniklerini kullanmanın ne kadar yararlı olduğunu gösterir.
Duygu analizi ve yapay zeka ve makine öğrenimi gibi ilişkili teknolojiler hakkında daha fazla bilgi edinmek istiyorsanız, Makine Öğrenimi ve Yapay Zeka kursunda PG Diplomamızı inceleyebilirsiniz.