
Расширение набора данных: создание искусственных данных [простое объяснение]
Опубликовано: 2020-12-07Оглавление
Введение
При разработке любого алгоритма машинного обучения всегда необходимо поддерживать компромисс между оптимизацией и обобщением . Эти слова могут показаться слишком сложными для новичков, но знание разницы между ними на раннем этапе их пути к освоению машинного обучения определенно поможет им понять, что лежит в основе того, почему их модель ведет себя определенным образом.
Аспект оптимизации относится к настройке модели таким образом, чтобы ее производительность на обучающих данных была максимальной. С другой стороны, обобщение относится к эффективности модели обучения на данных, которые она никогда раньше не видела, т. е. на проверочном наборе.
Часто наступает момент, когда после определенного количества эпох на обучающих данных обобщение модели перестает улучшаться, а показатели проверки начинают ухудшаться . данные обучения, но бесполезны для корреляции с новыми данными.
Чтобы решить проблему переобучения, лучшим решением является сбор большего количества обучающих данных: чем больше данных увидела модель, тем выше вероятность того, что она также выучит представления новых данных. Однако сбор большего количества обучающих данных может оказаться более дорогостоящим, чем решение основной задачи, которую необходимо решить. Чтобы обойти это ограничение, мы можем создать поддельные данные и добавить их в обучающую выборку. Это известно как увеличение данных.
Углубленное увеличение данных
Предпосылка изучения визуальных представлений из изображений помогла решить многие проблемы компьютерного зрения. Однако, когда у нас есть меньший набор данных для обучения, эти визуальные представления могут вводить в заблуждение. Увеличение данных — отличная стратегия для преодоления этого недостатка.
Во время аугментации изображения в обучающей выборке преобразуются с помощью определенных операций, таких как вращение, масштабирование, сдвиг и т. д. Например: если обучающая выборка состоит только из изображений людей в положении стоя, то классификатор, который мы пытаемся построить, может не предсказать изображения лежащих людей, поэтому аугментация может имитировать изображение лежащих людей, поворачивая изображения обучающего набора на 90 градусов.

Это дешевый и важный способ расширения набора данных и повышения показателей проверки модели.
Расширение данных — это мощный инструмент, особенно для задач классификации, таких как распознавание объектов. Такие операции, как перемещение обучающих изображений на несколько пикселей в каждом направлении, часто могут значительно улучшить обобщение.
Еще одна полезная особенность аугментации заключается в том, что изображения трансформируются в потоке, что означает, что существующий набор данных не переопределяется. Увеличение будет происходить, когда изображения загружаются в нейронную сеть для обучения, и, следовательно, это не увеличит требования к памяти и сохранит данные для дальнейших экспериментов.
Применение трансляционных методов, таких как увеличение, очень полезно, когда сбор новых данных обходится дорого, хотя следует помнить, что нельзя применять преобразование, которое может изменить существующее распределение обучающего класса. Например, если обучающий набор включает изображения рукописных цифр от 0 до 9, то переворачивание/поворот цифр «6» и «9» не является подходящим преобразованием, поскольку это сделает обучающий набор устаревшим.
Читайте также: Лучшие идеи проекта наборов данных машинного обучения
Использование увеличения данных с TensorFlow
Увеличение может быть достигнуто с помощью API ImageDataGenerator от Keras с использованием TensorFlow в качестве бэкэнда. Экземпляр ImageDataGenerator может выполнять ряд случайных преобразований изображений в точке обучения. Некоторые из популярных аргументов, доступных в этом случае:

- rotate_range: целочисленное значение в градусах от 0 до 180 для случайного поворота изображений.
- width_shift_range: смещение изображения по горизонтали вокруг его рамки для создания дополнительных примеров.
- height_shift_range: смещение изображения по вертикали вокруг рамки для создания дополнительных примеров.
- shear_range: примените к изображению случайные преобразования сдвига, чтобы создать несколько примеров.
- zoom_range: Относительная часть изображения для произвольного масштабирования.
- horizontal_flip: используется для отражения изображений по горизонтали.
- fill_mode: метод заполнения вновь созданных пикселей.
Ниже приведен фрагмент кода, демонстрирующий, как можно использовать экземпляр ImageDataGenerator для выполнения вышеупомянутого преобразования:
- train_datagen = ImageDataGenerator(
- масштаб = 1./255,
- диапазон_вращения=40,
- ширина_сдвига_диапазон = 0,2,
- height_shift_range=0,2,
- сдвиг_диапазон = 0,2,
- масштаб_диапазон = 0,2,
- horizontal_flip = Верно,
- fill_mode='ближайший')
Также тривиально увидеть результат применения этих случайных преобразований к обучающей выборке. Для этого мы можем отобразить несколько случайно дополненных обучающих изображений, перебирая обучающий набор:

Рис. 1. Изображения, созданные с помощью аугментации .
(Изображение из «Глубокого обучения с помощью Python» Франсуа Шолле, глава 5, стр. 140)
Рисунок 1 дает нам представление о том, как аугментация может создавать несколько изображений из одного входного изображения, при этом все изображения внешне отличаются друг от друга только из-за случайных преобразований, которые были выполнены с ними во время обучения.
Чтобы понять истинную суть использования стратегий расширения, мы должны понять его влияние на показатели обучения и проверки модели. Для этого мы будем обучать две модели: одна не будет использовать аугментацию данных, а другая будет. Чтобы проверить это, мы будем использовать набор данных Cats and Dogs , который доступен по адресу:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Кривые точности, которые наблюдались для обеих моделей, представлены ниже:
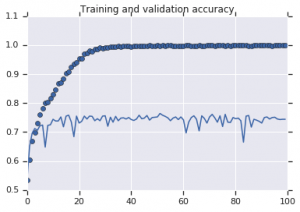
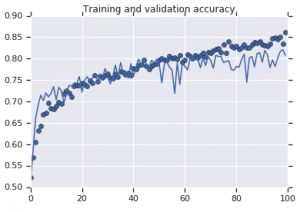
Рисунок 2: Точность обучения и проверки. Слева : модель без аугментации. Справа : модель со случайными преобразованиями увеличения данных.
Обязательно прочтите: лучшие наборы данных для анализа настроений
Заключение
Из рисунка 2 видно, что модель, обученная без стратегий аугментации, демонстрирует низкую обобщающую способность. Производительность модели на проверочном наборе не соответствует производительности на обучающем наборе. Это означает, что модель переоснащена.
С другой стороны, вторая модель, использующая стратегии расширения, демонстрирует отличные показатели, при этом точность проверки достигает уровня точности обучения. Это демонстрирует, насколько полезным становится использование методов увеличения набора данных, когда модель показывает признаки переобучения.
Если вы заинтересованы в дальнейшем изучении анализа настроений и связанных с ним технологий, таких как искусственный интеллект и машинное обучение, вы можете ознакомиться с нашим курсом PG Diploma in Machine Learning and AI .